【Decision Tree】理论与实现
🗓 2017年05月22日 📁 文章归类: 0x21_有监督学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2017/05/22/DecisionTreeClassifier.html
简介
决策树是一种强大的有监督数据挖掘技术,它能应用范围非常广,而且产生的模型具有可解释性,而且可以用来筛选变量。
决策树的特点:
- 每个节点两个走向
- 每个节点1个变量
- 变量可以重复使用
优点:
- 易于理解和解释
例如,收集专家的历史数据,用决策树可以总结出他的经验。 - 和其它模型相比,数据的预处理往往是不必要的。例如,不需要归一化 ,也 不用填充空值
- 可以同时处理分类变量和连续变量。其它模型很多要求数据类型单一
- 白盒模型,可以轻松推出逻辑表达式
- 计算量少,大量数据可也以快速得出良好结果
- 有变量筛选功能
- 决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。
缺点:
- 样本各类别数量不同时,结果更偏向于类别多的。 (除了朴素贝叶斯之外的大多数模型都存在这个问题)
- 过拟合
- 忽略自变量之间的相关性(因为每个节点只能选取1个feature)
用途:
- 有监督
- 既可以做分类,也可以做回归
- 也可以用于变量筛选
理论推导
Quinlan在1986年提出ID3,1993年提出C4.5
Breiman在1984年提出CART算法
定义
决策树是由node和directed edge组成
其中node有两种:
- internal node表示一个特征或属性
- leaf node 表示一个类
决策树有一个重要性质:互斥且完备。意思是每个case都被一条路径覆盖,并且只被一条路径覆盖
输入数据
给定的数据是$D={(x_1,y_1),(x_2,y_2),…(x_N,y_N) }$
其中,
$x_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})$是一个样本,有n个维度
$y_i \in { 1,2,…K } $类标记
N是样本容量
模型1
问题是找出$P(Y \mid X)$,X是表示特征的随机变量,Y是表示类的随机变量
lost function是正则化极大似然函数
遍历是一个NP完全问题,因此改用启发式方法近似求解
要理解决策树算法,必须先理解2个方面的知识:
其一是: 信息熵和信息益增,
其二是: 树结构和递归
关于信息熵,信息益增,见于我写的一篇博客信息熵
关于树结构,见于我写的另一篇博客Graph&Tree
ID3(算法)
注:很多材料给出的算法包含很多步,这里把一些不会分开的步放到了一起,看起来比较简洁
输入:训练数据集D,特征集A,阈值$\epsilon$
输出:决策树T
ID3递归算法:
step1:对于当前要计算的节点,找到信息益增最大的Feature,记为$A_g$
step2:如果信息益增小于$\epsilon$,生成节点,把实例数最大的类作为这个节点的类,递归结束
step3:否则,用$A_g$中的每一个可能值$\alpha_i$构建下多个子节点,递归转到每一个子节点。
C4.5
C4.5是ID3的改进,在ID3的基础上增加一个步骤:剪枝。
part1,用信息增益率生成树
算法:
第一步与ID3算法类似,只有一个区别:
用信息增益率来选择属性,而不是信息益增
信息益增率定义为$g_R(D,A)=\dfrac{g(D,A)}{H(D)}$ (详见相关博客信息熵)
step1:对于当前要计算的节点,找到信息益增率最大的Feature,记为$A_g$
step2:如果信息益率增小于$\epsilon$,生成节点,把实例数最大的类作为这个节点的类,节点变成叶节点,递归结束
step3:否则,用$A_g$中的每一个可能值$\alpha_i$构建下多个子节点,递归转到每一个子节点。
part2,剪枝(pruning)
引入cost function
$C_\alpha(T)=\sum\limits_{t=1}^{\mid T \mid} N_t H_t(T)+\alpha \mid T \mid$
where,
$\mid T\mid$是叶节点个数
对于T的第t个叶节点,该叶节点有$N_t$个样本,其中第k类样本个数为$N_{tk}$
$\alpha$控制模型复杂度
这个cost function等价于正则化的极大似然估计
剪枝算法:
输入:part1产生的整个树T,参数$\alpha$
输出:修建后的子数$T_\alpha$
方法:
- 扫描叶节点,$T_A$是修剪后的叶节点,如果$C_\alpha(T_A) \leq C_\alpha(T)$,那么剪枝
- $T=T_A$,继续上一步,直到所有节点都不再能修剪为止
C4.5的特点:
- 能够完成对连续属性的离散化处理;
- 能够对不完整数据进行处理。
- 其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
- C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
- 生成是局部选择,剪枝是全局选择
CART
特点:
- 二叉树,左支代表是,右支代表否
- 既可以用于分类,也可以用于回归
最小二乘回归树生成算法
这个算法的整体架构与C4.5,ID3类似,不同的是找Feature的方法不一样,并因此导致分类方法也有所调整
先看一个节点的计算方法。假设找到第j个Feature(无论连续还是离散),并且找到一个值s作为切分点(splitting Point),那么可以立即切分成两个区域:
\(R_1(j,s)=\{ x \mid x^{j} \leq s \}\)
\(R_2(j,s)=\{ x \mid x^{j} > s \}\)
求解:
\(\min\limits_{j,s}\bigg[\min\limits_{c_1}\sum\limits_{x_1 \in R_1(j,s)}(y_i-c_1)^2+\min\limits_{c_2}\sum\limits_{x_2 \in R_2(j,s)}(y_i-c_2)^2\bigg]\)
CART生成算法
引入一个概念,gini index
$Gini(X)=\sum_{k=1}^K p_k(1-p_k)$
这个概念与entropy有很大的相似度,也有类似的一组概念
特征A下,集合D的gini index定义为:
$Gini(D,A)=\dfrac{\mid D_1 \mid}{\mid D\mid}Gini(D_1)+\dfrac{\mid D_2 \mid}{\mid D\mid }Gini(D_2)$(与conditonal entropy相似的概念)
where,
$D_1,D_2$是被$A=\alpha$分割后的集合
算法流程与前面的ID3,,C4.5基本一致,不同的是,要选择Feature,分割$A=\alpha$,使得Gini 最小(对比ID3的信息益增最大等价于条件信息熵最小)
方法:
step1:对于当前要计算的节点,找到gini index最小的Feature和划分$A=\alpha$
step2:如果样本数量小于阈值,或者gini index小于阈值$\epsilon$,生成节点,把实例数最大的类作为这个节点的类,节点变为叶节点,递归结束
step3:否则,构建子节点,递归转到每一个子节点。
CART剪枝算法
与C4.5类似,引入loss function
$C_\alpha(T)=C(T)+\alpha\mid T\mid$
step1: 改变$\alpha$,例如,排序的$0,\alpha_1,\alpha_2,…,+\infty$可以得到一组子树:\(\{ T_0,T_1,...T_n \}\)。
找到这组子树的算法的复杂度并不高,这是因为剪掉每个节点损失的函数值可以一次性计算出来\(g(t)=\dfrac{C(t)-C(T_t)}{\mid T_t \mid -1}\)
step2: 用交叉比较的方法找到$T_0,T_1,…T_n$中最优的。
python实现:
环境准备
用Python的sklearn做模型。
sklearn的一个缺点:pruning not currently supported。只实现了pre-pruning
-
安装graphviz
conda install graphviz -
安装软件graphviz,官网:
http://www.graphviz.org/Download.php
代码
step1:做出模型
from sklearn import datasets
dataset=datasets.load_iris()
from sklearn import tree
clf=tree.DecisionTreeClassifier()
clf=clf.fit(dataset.data,dataset.target)
step2:把规则输出
tree.export_graphviz(clf,out_file="tree.doc" )#输出到doc
step3:规则可视化
import graphviz
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=dataset.feature_names, class_names=dataset.target_names,filled=True, rounded=True,special_characters=True) #参数是配置颜色等
graph = graphviz.Source(dot_data)
graph.view('hehe.pdf')
graph.save('abc.pdf')
graph #在jupyter中有用
结果:
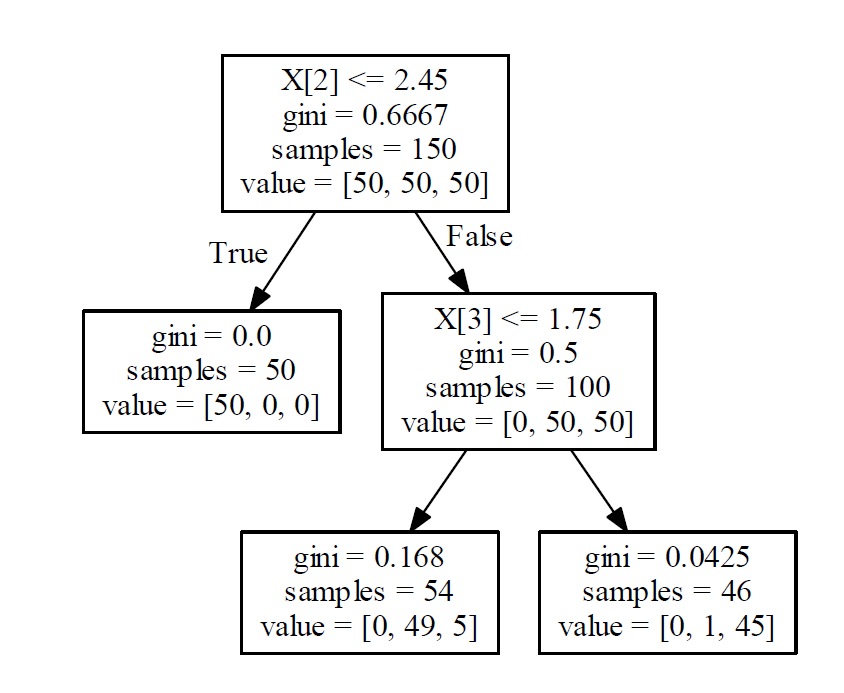
预测
clf.predict(train_data)#判断数据属于哪个类别
clf.predict_proba(train_data)#判断属于各个类别的概率
clf.feature_importances_#变量重要性指标,各个属性的gini系数归一化后的值
#例如,print(pd.DataFrame(list(zip(data.columns,clf.feature_importances_))))
用CART拟合的例子
由于使用的是gini idex生成决策树,因此y可以是连续变量,所以可以做拟合。
先用模拟法生成数据
import numpy as np
from sklearn.tree import DecisionTreeRegressor
x=np.linspace(0,10,90)
x.shape=-1,1
y=np.sin(x)+np.random.normal(size=x.shape)*0.5
模型的输入是一维的连续变量
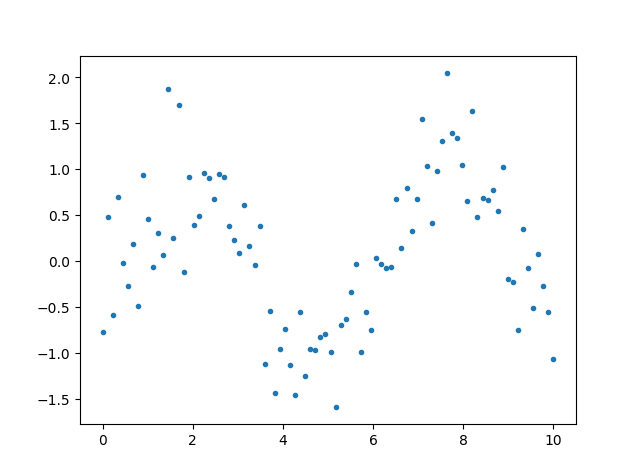
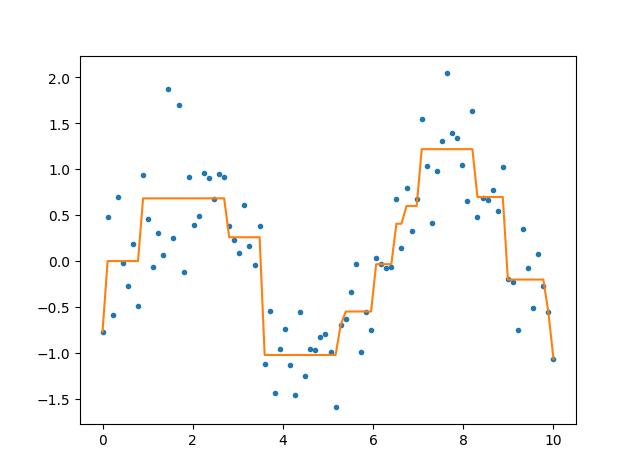
下面是拟合并作图
clf=DecisionTreeRegressor(max_depth=4)
clf.fit(x,y)
ynew=clf.predict(x)
import matplotlib.pyplot as plt
plt.plot(x,y,'.')
plt.show()
plt.plot(x,y,'.')
plt.plot(x,ynew)
plt.show()
后注(备用)
可视化输入方法(备用)
为了可视化输出,还需要进行下面的配置:
- 安装pydotplus:
https://github.com/carlos-jenkins/pydotplus -
安装graphviz
conda install graphviz -
安装软件graphviz,官网:
http://www.graphviz.org/Download.php - 加入环境变量:
import os os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
备用方法1:转化为决策图,输出到pdf
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
备用方法2
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,feature_names=iris.feature_names, class_names=iris.target_names,filled=True, rounded=True,special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
参考文献
您的支持将鼓励我继续创作!
