【pandas】合并数据表
🗓 2017年07月04日 📁 文章归类: pandas
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2017/07/04/pandasconcat.html
本博客取材于pandas作者Wes McKinney 在【PYTHON FOR DATA ANALYSIS】中对pandas的一个权威简明的入门级的介绍,图片来自网络,本人进行了归纳整理。
涉及到3个函数:concat,merge,加减乘除
0数据准备
案例的数据准备:生成要用到的几个表:
import pandas as pd
df1=pd.DataFrame({'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']},
index=[0,1,2,3])
df2=pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7'],
'D':['D4','D5','D6','D7']},
index=[4,5,6,7])
df3=pd.DataFrame({'A':['A8','A9','A10','A11'],
'B':['B8','B9','B10','B11'],
'C':['C8','C9','C10','C11'],
'D':['D8','D9','D10','D11']},
index=[8,9,10,11])
df4=pd.DataFrame({'B':['A8','A9','A10','A11'],
'D':['B8','B9','B10','B11'],
'F':['C8','C9','C10','C11']},
index=[2,3,6,7])
1. pd.concat:以index或columns为合并条件
特点:匹配columns,匹配不到的的填入nan
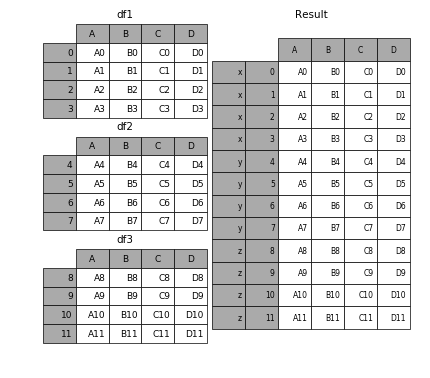
result=pd.concat([df1,df2,df3])
例子:
result=pd.concat([df1,df2,df3])
效果如下:
1.1 axis:纵向合并还是横向合并
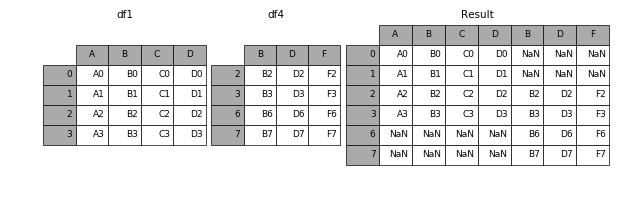
result = pd.concat([df1, df4], axis=1)
# axis='index'(默认)是纵向合并,(等价:axis=0)
# axis='columns' 是横向合并,(等价:axis=1)
效果如下:
1.2 join
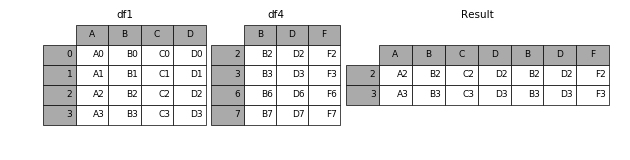
join=’outer’(默认),把所有未匹配到的也列出来,(上面这个案例)
join=’inner’,只列出左右两列都有的
result = pd.concat([df1, df4], axis=1, join='inner')
效果如下:
1.3 keys分组键
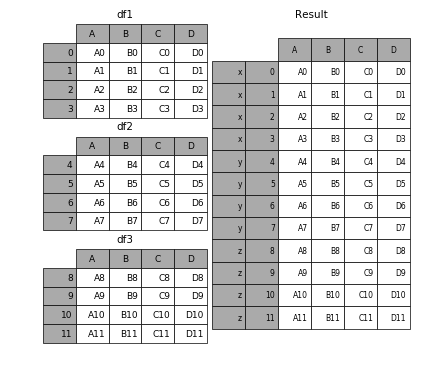
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
result = pd.concat([df1,df2,df3], keys=['x', 'y', 'z'])
#result=pd.concat({'x':df1,'y':df2,'z':df3})
#也可以用dict来做
效果如下:
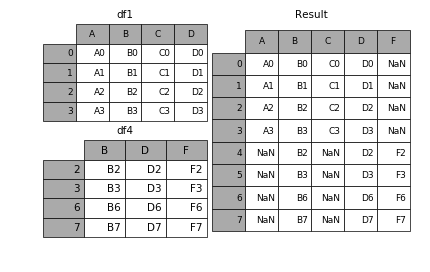
1.4 ignore_index
如果两个表的index没什么实际含义,用ignore_index=True,使两个表对齐整理出一个新的index
result=pd.concat([df1,df4],ignore_index=True)
效果如下:
2. merge:以指定列为合并条件
除了简单合并外,有时需要匹配合并(类似SQL中的join命令)
数据准备
import pandas as pd
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
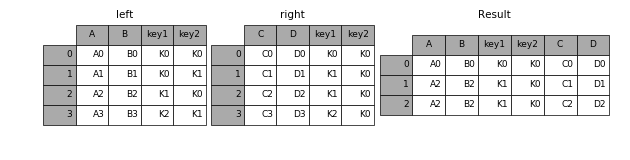
3.1 连接
result = pd.merge(left, right, on=['key1', 'key2'])
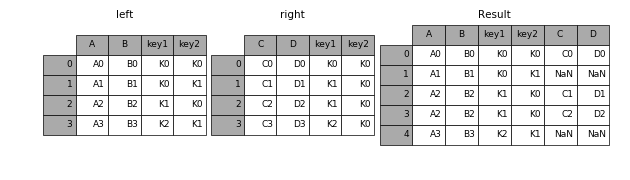
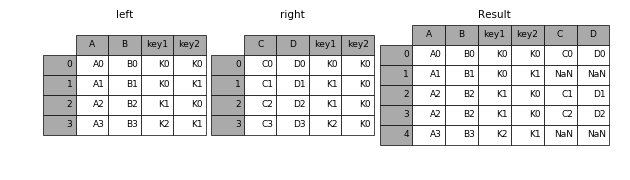
3.2 how
how=’inner’(默认)
how=’left’
how=’right’
how=’outer’
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
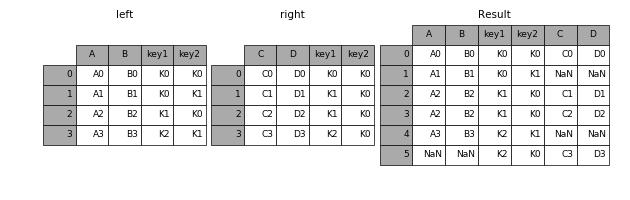
on
有的时候,在左右表中,待匹配的列名不相同,分别指定左右表的列名就行了。
- on
- left_on/right_on
- left_index/right_index: 用index作为左连接键/右链接键
import pandas as pd
left = pd.DataFrame({'group': ['a', 'a', 'a', 'b','b', 'b', 'c', 'c','c'],'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
right = pd.DataFrame({'label':['a','b','c'],'value':['alpha','beta','charlie']})
inner_joined = pd.merge(left, right, how='inner', left_on='group', right_on='label')
suffix
两个表的列名相同,但是意义不同。合并的时候想自动让他们重命名,然后保留下来。
result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
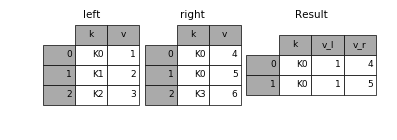
3. 加减乘除
df1+df2
#+-*/
#//求商 %求余
不是合并。对应项相加减乘除。遇到index和column无法匹配的,填入NaN
用函数功能更多
df1.add(df2,fill_value=0)
#不再填入NaN,而是填入0
add,sub,div,mul
参考文献
您的支持将鼓励我继续创作!
