【Bagging&Boosting】理论与实现
🗓 2017年10月06日 📁 文章归类: 0x21_有监督学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2017/10/06/baggingboosting.html
组合算法的简介
训练 多个分类器 ,然后 投票来进行分类 ,从而预测来提高分类准确率。
但是: 组合方法比任意单分类器的效果要好吗?
打个比方
考虑25个分类器的组合,其中每个分类器的误差均为0.35,并且 相互独立。
那么组合算法的误差是:
$E=\sum\limits_{i=13}^{25} C_{25}^i e^i (1-e)^{25-i}=0.06$
结论
上面这个例子说明,当满足以下条件时,组合分类器优于单个分类器
- 基分类器之间 相互独立
- 基分类器 好于随机猜测分类器
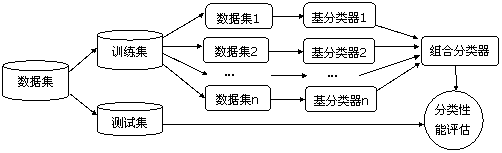
组合算法的分类
很难保证基分类器相互独立,基分类器轻微相关的情况下,组合方法也可以提高分类的准确率,
如何减少相关关系呢?
这里提供4种方法
1. 处理训练数据集
根据某种抽样分布,对原始数据进行再抽样,然后使用特定的学习算法为每一个训练集建立一个分类器。
典型:
装袋(bagging) 和 提升(boosting)
2. 处理输入特征
通过选择输入特征的子集来形成每个训练集,子集可以随机选择,也可以根据领域专家的建议选择。适合含有大量冗余特征的数据集。
典型:
随机森林(Random forest)
3. 处理类标号
通过将类标号随机划分成两个不相交的子集,把训练数据变换为二类问题,然后重新标记过的数据训练一个基分类器,重复多次,得到一组基分类器。
典型:
错误-纠正输出编码(error-correcting output coding)
4. 处理学习算法
在同一个训练数据集上多次执行算法可能得到不同的模型。
如:改变 神经网络 拓扑结构或各个神经元之间的连接的权重,就可以得到不同的模型。
前三种属于一般性方法,适用于任何分类器,第四种方法依赖于使用的分类器类型。
bagging
bagging ,又叫 bootstrap aggregating
有n个样本,每个基分类器需要m个数据,bagging方法如下:
setp1:从n个样本中 有放回 的抽m个数据,做一次基分类器
step2:重复step1, 重复k次,得到k个基分类器
step3:这k个基分类器投票得到最终的结果
bagging的基分类器是decision tree的话,又叫random forest
评价
bagging增强了目标函数的表达功能,通过减低基分类器方差改善了泛化误差,bagging的性能依赖于基分类器的稳定性。
- 如果基分类器不稳定,bagging有助于减少训练数据的随机波动导致的误差;
-
如果基分类器稳定,即对训练数据中的微小变化是鲁棒的,则组合分类器的误差主要有基分类器的偏倚所引起。这种情况下,bagging可能不会对基分类器的性能有显著改善,甚至可能 降低 分类器的性能,因为每个训练集的有效容量比原数据集大约小37%。($(1-1/n)^n$)
- bagging用于噪声数据,不太受过分拟合的影响。
boosting
在bagging的基础上,逐渐放大上次预测错误的样本抽中的概率 关于boosting的研究很多,有很多算法,最有代表性的是AdaBoost算法(AdaBoost algorithm)1
算法(AdaBoost)
输入:训练集\(T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}\),其中 \(x_i\in \mathcal X \subset R^n, y\in \mathcal Y = \{ -1, +1\}\); 弱分类器;
输出:分类器$G(x)$
step1 : 初始化迭代次数$m=1$, 初始化数据权值分布$D_m=(w_{m1},…,w_{mi},…w_{mN}), \space w_{mi}=1/N, i=1,2,…N$
step2 : 学习第m个分类器$G_m$,使用$D_m \times T$来训练,得到\(G_m(x):\mathcal X \to \{-1,+1\}\)
step3 : 计算$G_m(x)$的分类误差率$e_m=P(G_m(x_i)\neq y_i)=\sum\limits_{i=1}^N w_{mi} I(G_m(x_i)\neq y_i)$
step4 : 计算$G_m(x)$的权重$\alpha_m=1/2\ln \dfrac{1-e_m}{e_m}$
step5 : 更新权值分布$D_{m+1}$,
其中$w_{m+1,i}=\dfrac{w_{mi}}{Z_m}\exp(-\alpha y_i G_m(x_i)), i=1,2,…N$
$Z_m=\sum\limits_{i=1}^Nw_{mi}\exp(-\alpha_m y_i G_m(x_i))$是为了使权值之和为1
step6: m=m+1,如果$m<=M$, 转到 step2
step7: 得到最终的分类器为$G(x)=sign(\sum\limits_{m=1}^M \alpha_mG_m(x))$
问题
- 样本的权重是无法放入CART中的
用$\dfrac{w_i}{\min\limits_i (w_i)}$去复制样本。优点是简单,缺点是样本数可能会很多。 - 错误率可以放入决策树。
提升树
第i+1个树的target,是$y-y_i$
梯度提升树
残差方向是沿着损失函数的负梯度方向。
bagging的基分类器偏差小,方差大,效果好,因此random forest要完全生长
boosting的基分类器适合方差小,偏差大,因此提升树不能完全生长
Python实现
abc = ensemble. AdaBoostClassifier(n_estimators=100)#100个树
abc.fit(train_data, train_target)
test_est_abc = logistic_model.predict(test_data)
test_est_p_abc = logistic_model.predict_proba(test_data)[:,1]
fpr_test_abc, tpr_test_abc, th_test_abc = metrics.roc_curve(test_target, test_est_p_abc)
rfc = ensemble.RandomForestClassifier(criterion='entropy', n_estimators=3, max_features=0.5, min_samples_split=5)
rfc.fit(train_data, train_target)
test_est_rfc = logistic_model.predict(test_data)
test_est_p_rfc = logistic_model.predict_proba(test_data)[:,1]
fpr_test_rfc, tpr_test_rfc, th_test_rfc = metrics.roc_curve(test_target, test_est_p_rfc)
参考文献:
您的支持将鼓励我继续创作!
