【CNN】理论篇
🗓 2017年12月16日 📁 文章归类: 0x25_CV
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2017/12/16/cnn.html
介绍
卷积神经网络(CNN,Convolutional neural network)由日本人福岛邦彦与1990s首先提出。
CNN之父Yann LeCun于1997年提出LeNet-5,有效实现了手写识别。
卷积神经网络的概念出自1960s科学家提出的感受野(Receptive Field),发现每个视觉神经元只会处理一小块区域的视觉图像
用全连接层的方法训练MNIST数据集时,把每张图摊平成为一个$784\times 1$的向量。仔细推敲会发现有些奇怪,因为这样没有考虑图像的空间结构,它以完全相同的基础对待相距很远和相距很近的像素点。
CNN可以充分利用空间结构。
CNN有三个基本概念:局部感受野(local receptive fields),共享权重(shared weights),pooling
是一种前馈神经网络,与其它前馈神经网络最大的区别是,并不是全连接网络(full connect network)
有两个大的特点:
- 至少一个卷积层,用来提取特征
- 卷积层权值共享,大大减少权值数量,提高收敛速度。
主要用来识别位移、缩放、其他形式扭曲不变性的二维图像。
避免了显式的特征抽取。
也可以用于时间序列信号,例如音频信号、文本数据
结构
1. 卷积
数学中卷积的定义:$f(x) * g(x)=\int_{-\infty}^{\infty} f(t)g(x-t)d t$
神经网络种,一个卷积核一次输出为$\sigma(b+\sum\limits_{l=1}^3\sum\limits_{m=1}^3 w_{lm} a_{j+l,k+m})$
神经网络中卷积有这几个参数:
- Padding
- Striding
- 卷积核大小
- (所在的这一层)卷积核的个数
实践中,卷积核大小一般做成奇数,既方便 padding,也方便定义卷积前后的中心。
1.1 Padding
边界有多少个像素,(通常,低像素图像填充0个像素点,高像素图像填充5~10个像素点)
按照惯例,填充0
目的:
- 保持图像大小一致
- 保持边界信息不减少太多,否则边缘的像素扫描了一遍,而中间的像素扫描了多次,导致信息参考程度不同。
- 如果输入图片的尺寸有差异,可以用Padding补齐
1.2 Stride
每次滑动的单位,通常Stride=1,细密程度最好。
也可以取别的值,例如Stride=3,表示每次移动3像素,粗糙了一些。
1.3 Convolutions Over Volume
主要是多channel的操作, 例如,原图像shape (6,6,3) ,kernel的shape是 (3,3,3),一次卷积运算后的结果是(4,4)的
- 不padding,不Stride
- kernel 的channel数量必须与原图像channel数量一样(3)
输出的大小
符号
- 输入层为$n^{[l-1]}\times n^{[l-1]}\times n_c^{[l-1]}$
- filter大小为$f^{[l]} \times f^{[l]} \times n_c^{[l-1]}$
- padding 为 $p^{[l]}$
- stride为$s^{[l]}$
卷积运算后,大小为floor$((n-f+2p)/s+1)$(没考虑输入层长宽不一样的情况,但类似)
加入channel后,怎样呢?自己画画看看吧。
矢量化运算符号约定
- $a^{[l]}, n_H^{[l]}\times n_W^{[l]}\times n_C^{[l]}$
- $A^{[l]}, m\times n_H^{[l]}\times n_W^{[l]}\times n_C^{[l]}$
- weights $f^{[l]}\times f^{[l]}\times n_C^{[l-1]}\times n_C^{[l]}$
- bias $n_C^{[l]},(1,1,1,n_C^{[l]})$
2. Pooling Layer
池化层(Pooling Layer),一些旧的CNN网络喜欢使用的一种处理层。
常见两种:
- Max Pooling
- Mean Pooling(效果普遍比 max pooling 差,已极少见)
在卷积的基础上,不是做加,而是求Max/Mean
- 最常用的是max-Pooling,就是简单取$m \times n$区域内最大的像素点
- L2 pooling 也比较常用,是取$m\times n$区域内所有像素点平方和的平方根
- average Pooling 有时也用
没有参数,超参数有两3个 size(f), stride(s),算子。(padding极为少见)
对于多 channel ,各自独立做Pooling,叠起来(不影响 channel 数量)
有效的原因是提取块中最大的特征,实践中运行良好。但没人知道更深层的原因是什么(来自吴恩达的说法)。有可能本质上是一种降采样,可以有效降低模型大小。
3. Fully connected layers
FC
tips
没必要对卷积层进行Dropout操作
卷积层可以减少参数的原因
- Parameter sharing
- sparsity of connections. 只与局部有关(同时也有 translation invariance 效果)
对手案例集
实验发现,某些图像加上噪声后,神经网络会误分类,加上噪声后的图像叫做对手案例。
对手案例出现概率低,但稠密(类似有理数),几乎每个图像周围都可以找到对手案例。
尽管神经网络对应的函数理论上都是连续的,但对手案例集的存在,证明神经网络以背离我们直觉的方式变得不连续。另外,现在对这种不连续性出现的原因还没有搞清楚:是跟损失函数有关么?或者激活函数?又或是网络的架构?还是其他?我们一无所知。
经典CNN:LeNet-5
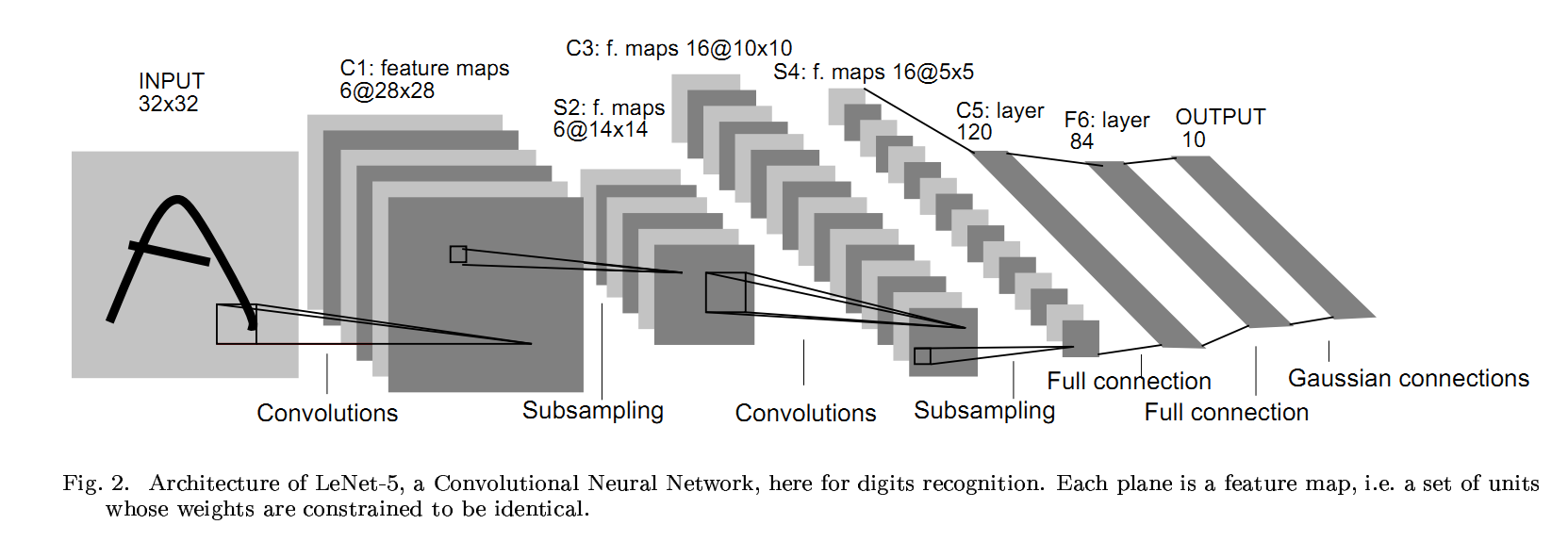
LeCun于1997年提出
输入层→(卷积层+→池化层?)+→全连接层+
卷积层+表示可以连续使用卷积层,一般最多连续使用三层
池化层?表示可有可无
原论文的一些特点(后来改进了)
- avg pool,f=2,s=2
- 没有 padding
- 激活函数是 sigmoid/tanh
4种现代经典CNN
ImageNet由斯坦福大学华人教授李飞飞创办,有1500万张标注过的图片,总共22000类
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛
| 模型名 | 奖项 | Top-5错误 | 层次 |
|---|---|---|---|
| AlexNet | 2012冠军 | 16.40% | 8 |
| VGGNet | 2014亚军 | 7.30% | 19 |
| Google Inception Net | 2014冠军 | 6.70% | 22 |
| ResNet | 2015冠军 | 3.57% | 152 |
| 人眼 | 5.10% |
1. AlexNet
AlexNet实现
Hitton的学生Alex Krizhevsky提出。
包含6亿3000万个连接,6000万个参数,65万个神经元。
5个卷积层,其中3个卷积层连接了maxpool,最后3个全连接层。
AlexNet在神经网络低谷期第一次发声,确立了深度卷积网络在计算机视觉中的统治地位。
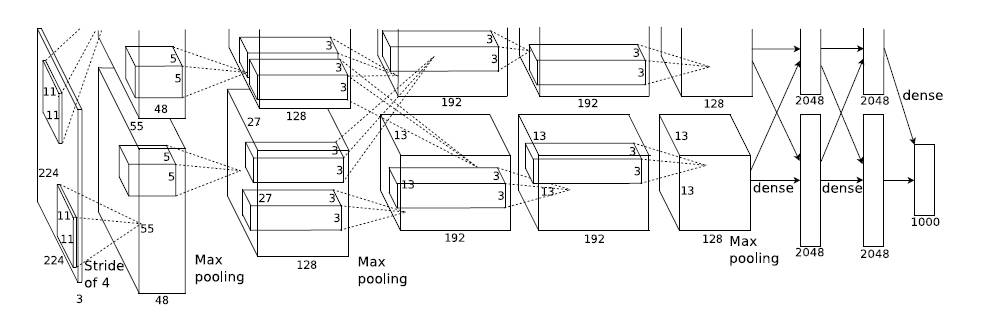
AlexNet将LeNet的思想发扬光大。新技术点如下:
- ReLU作为CNN的激活函数,并验证其在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。ReLU很早被提出,在AlexNet出现才开始发扬光大
- 使用Dropout. Dropout虽然有单独论文阐述,但AlexNet将其实用化
- 使用Maxpool,此前普遍使用Meanpool。提出步长小于池化核的尺寸,使输出有重叠和覆盖,提升特征丰富性。
- 提出LRN层(Local Response Norm),对局部神经元的活动创建竞争机制,提高泛化能力。后来的研究发现这无用
- 使用CUGA加速训练。设计GPU通讯。(原文用2块GPU,所以图中分为两块,且两块独立)
- 数据增强。随机从$256\times 256$图像中截取$224\times 224$,并加上水平翻转,相当于增加了$(256-224)^2\times 2=2048$倍数据量。防止相对于数据,参数太多导致的过拟合
现代观点:
- kernel 大小为 11x11 。stride=4,pad=0。现代一般为 3x3, stride=1,有 pad
- LRN 被证明无用
Alex Net 有个缺点,就是 hyperparameters 太多了,我们看VGGNet:
2. VGGNet
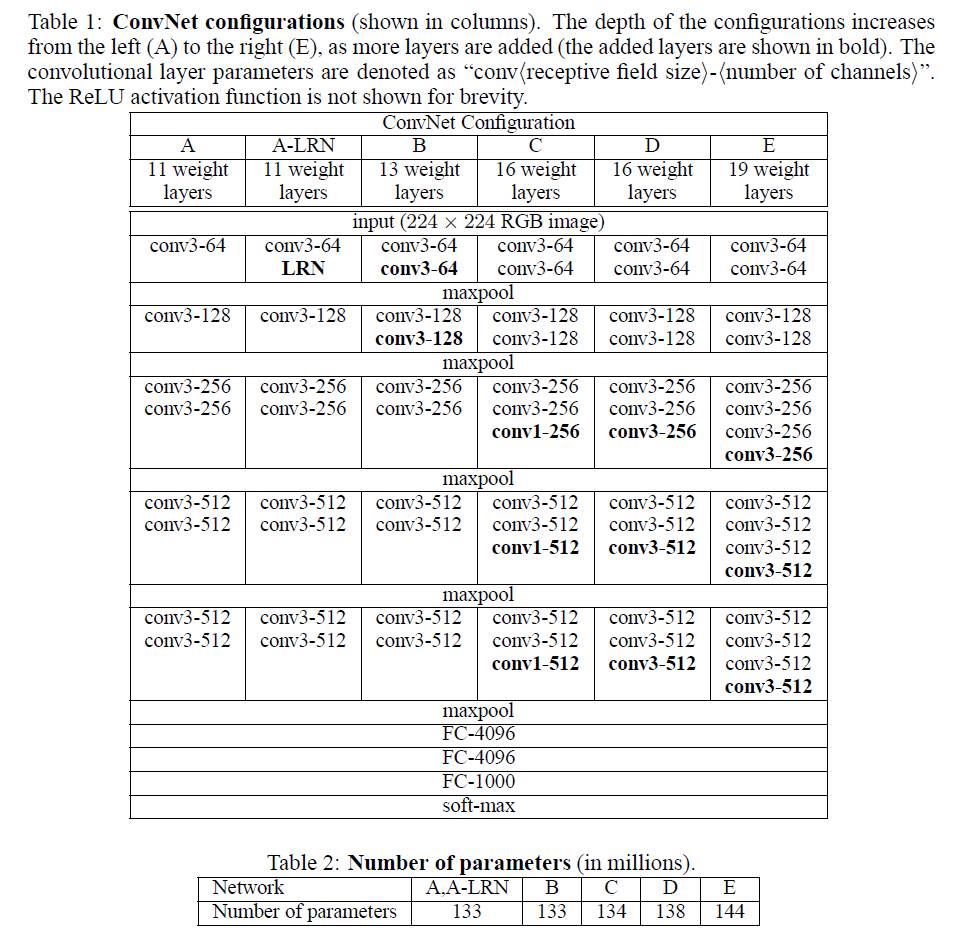
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司研究院合作研发的深度卷积神经网络。
其特点是反复堆叠:
- $3\times 3,stride=1,SAME$小型卷积核,
- $2\times 2, stride=2$ 的 Maxpool,
- 深度为16~19层
- 图中的D被称为
VGG-16(最常用) ,E被称为VGG-19
卷积层串联可行的原因:
- 2个$3\times 3$小型卷积核串联,感受野相当于1个$5\times 5$
- 3个$3\times 3$小型卷积核串联,感受野相当于1个$7\times 7$。
- 前者参数333=27个,后者参数7*7=49个
- 前者可以有更多非线性变换(可以每层都加上ReLU),后者需要只能加1个ReLU
其它技巧:
- 对原始数据,也使用了随机裁切
- 先训练A网络,复用A网络训练更复杂的模型,这样训练速度更快
评价
- 与 AlexNet 比较,准确上升 15%,但训练时间从 8 小时上升到 3天
- VGG 的深度更深的时候,准确率反而下降。所以出现了 ResNet
3. Google Inception Net
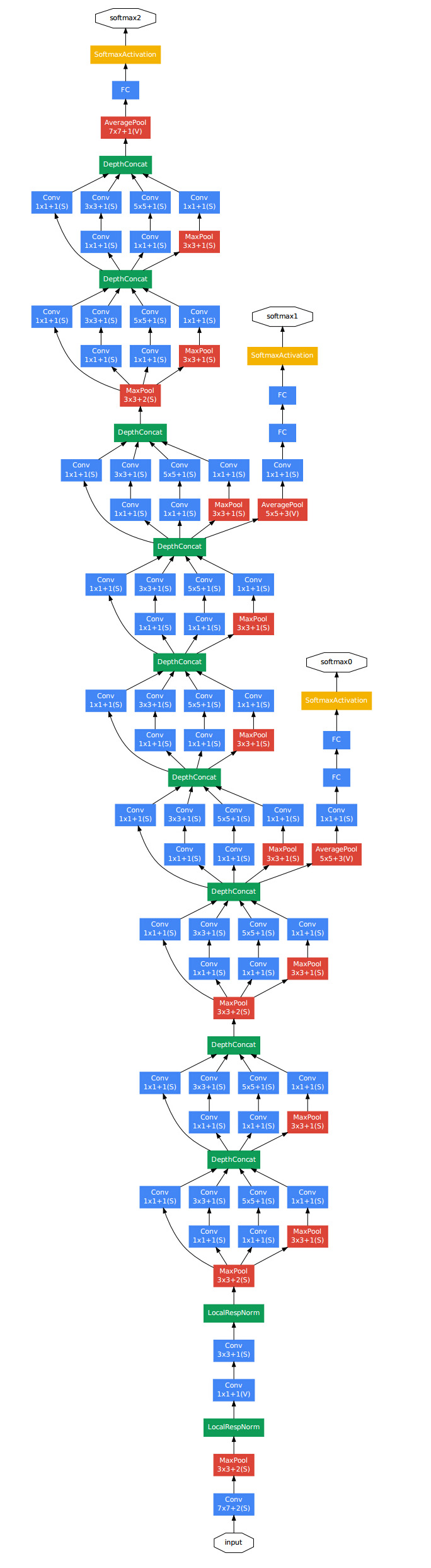
最大的特点是大大减少了参数和计算量
去除了最后的全连接层,改用MeanPooling
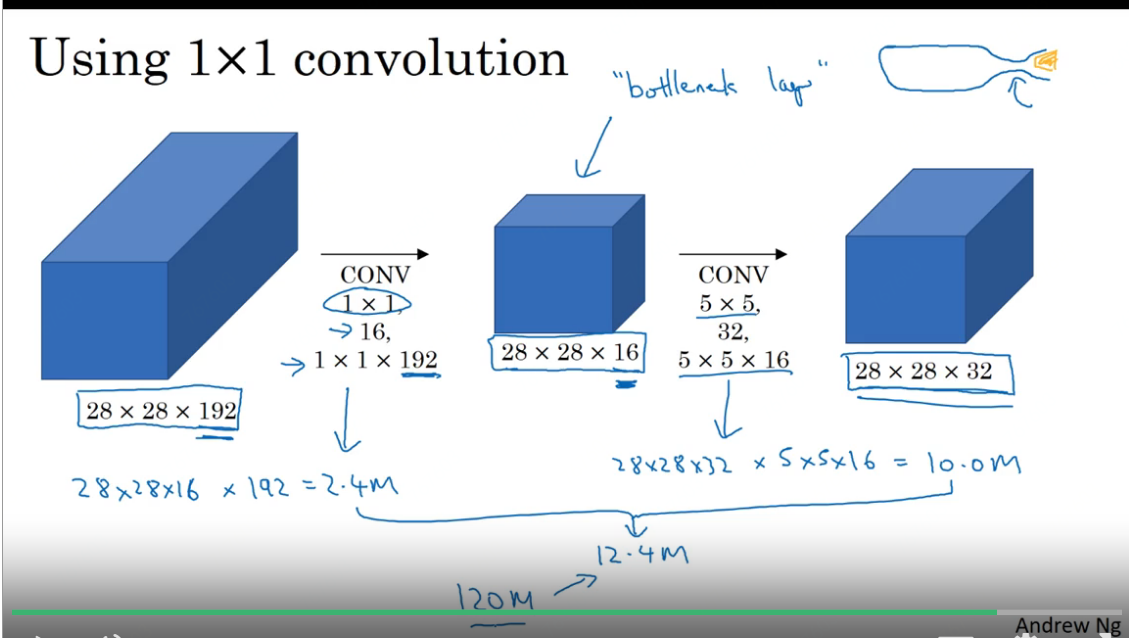
设计Inception Module提高参数利用效率
- 1x1 filter 的用途。
- 缩小 channel 个数
- 相当于像素级别的全连接
- 1x1 filter 后接5x5 filter,有一个 bottleneck 效果,极大减少乘法数量和参数数量
盗一张图
- DepthConcat 的效果是,把各种尺度的 filter 结果,沿着 channel 维度,拼接起来。
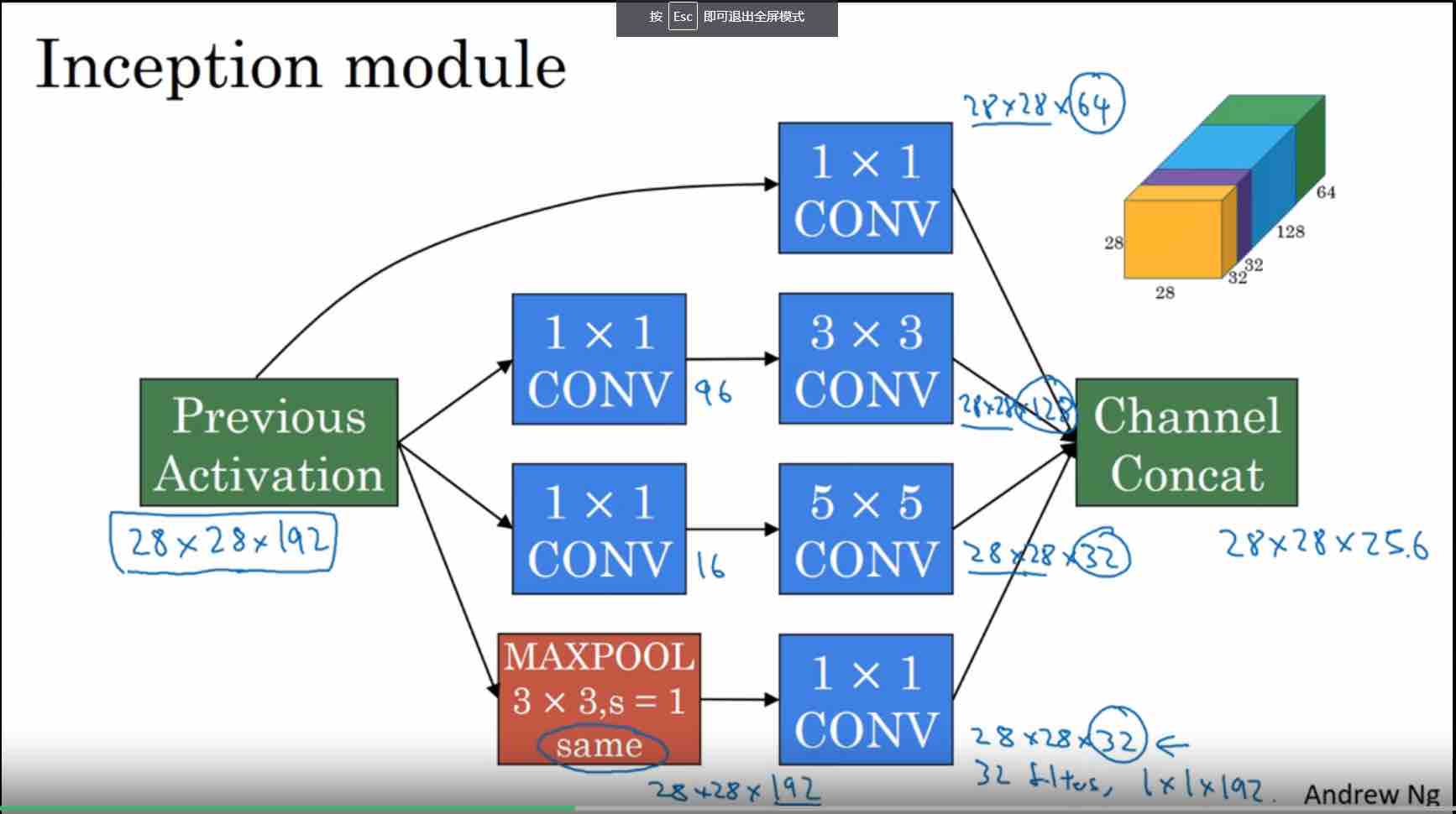
- 还有一个 trick,几个 hidden layer 也连接 output layer
4. ResNet

细节:
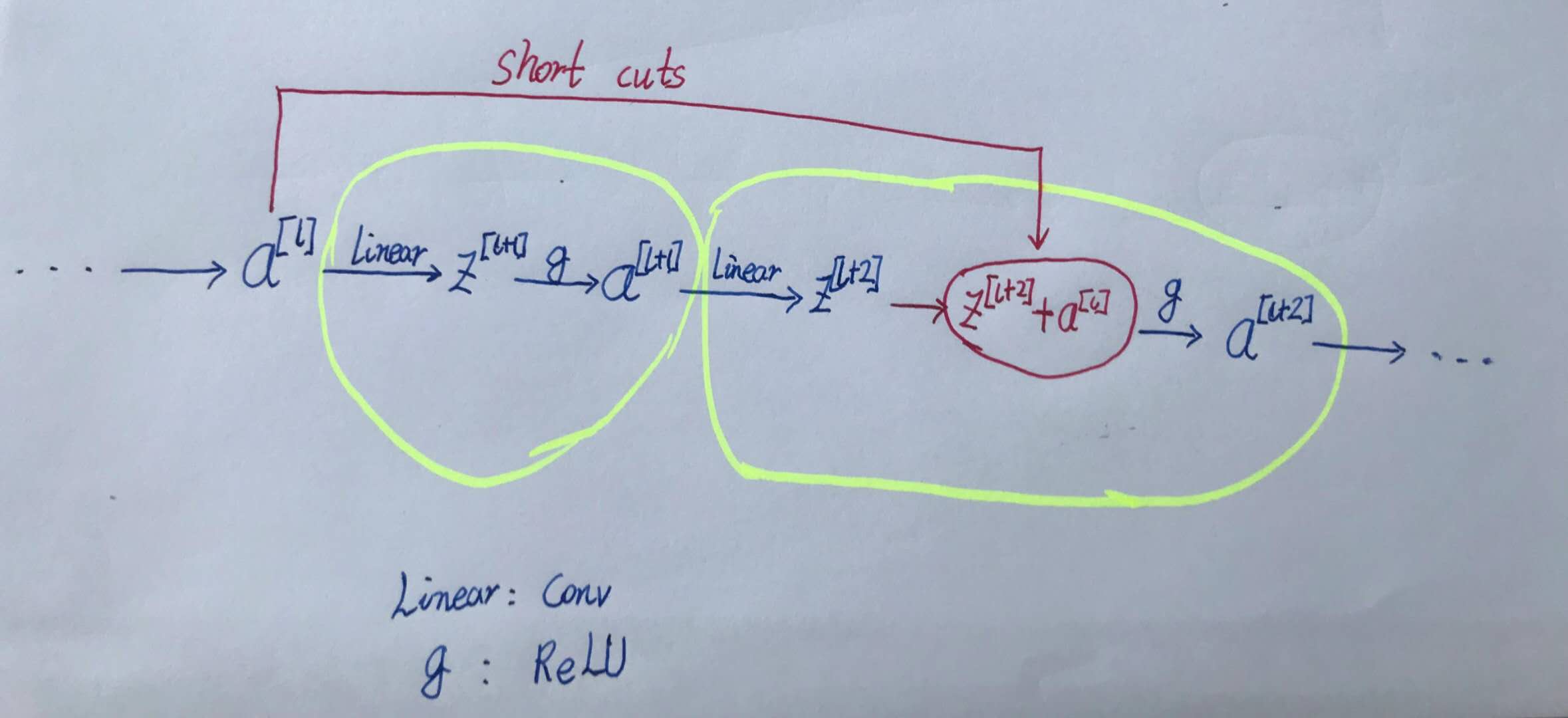
有些资料把这个模型叫做Deep Residual Learning
微软研究院的Kaiming He等4名华人提出,使用Residual Unit.
特点
- 参数量比VGGNet少,推广性很好
- ResNet出自这个问题:不断增加深度时,准确率先上升在下降,而且问题不是来自过拟合,而是来自训练难度增加。ResNet成功解决了这个问题。
- 使用了Highway Network,使得理论上任意深的神经网络都可以直接使用梯度下降法训练。
- ResNet 在竞赛和工业上被证明是很好的模型。
特点2
- 传统神经网络的某些片段,输入x,输出$H(x)$。
- ResNet的学习目标是$F(x)=H(x)-x$,学习的目标不是完整的输出$H(x)$,而是$H(x)-x$残差。
特点3
- ResNet类似一个没有gates的LSTM网络
practical advice
- Open-Source Implementation(github)
- 例如,deep-residual-networks
- 因为往往有很多细节,需要很多算力,需要很多data
- Transfer Learning
- 步骤
- 下载开源模型,别忘了 weights
- 拿掉最后一层 softmax 层,换成你自己的
- 只训练最后一层,前面的 weights 不去训练(freeze=1,TrainableParameter=0)
- 建议
- 事实上,你先把你的数据放模型中,算出$A^{L-1}$,存下来。然后在此基础上训练一个 softmax 回归。
- 如果你的数据很多,可以freeze 前 L-m 层。然后你可以在后m层weights的基础上继续训练。或者拿掉最后m层,换成你自己的。
- 如果你有海量的数据,最后一层softmax换成你自己的。然后在原有 weights 基础上,训练全部 weights。
- 步骤
- Data Augmentation:
- rotation,shearing,local warping
- color shifting:RGB 各个channel 分别增加或减少某个数值
- PCA color augmentation:例如,图片RB多,G少,可以用PCA增强G
- 数据增强后的结果不用存到硬盘,开一个CPU进程实时处理即可。
- 一些建议
- 2 source of knowledge:
- labeled data
- Hand engineered features/network architecture/other components
- 第一个不够,第二个来凑。但第二个很skillful,需要很多 insight.
- Tips for benchmarks/competitions
- ensembling
- multi-crop at test time
- use open source code(use architectures of networks published in the literature)
- use pretrained models and fine-tune on your dataset
- 2 source of knowledge:
应用领域
- 图像识别:分类问题
- 物体检测:一张图中有很多物体。R-CNN,YOLO
- 图像切割:类似“抠图”,U型网络(一个生成式模型)
- 图像聚类:以图搜图。使用CNN的中间层所提取的特征,做Kmeans聚类
- 降噪:auto-encoder,GAN
- 图像翻译:GAN,CycleGan
- 生成图片:GAN,DCGAN
人脸识别
两种任务:
- verification(1:1)
- recognition(1:K)
难点:One Shot Learning
- 训练集极小(数据库里每人只有1张照片)
- 有新人加入数据库后,output layer就要多一个维度
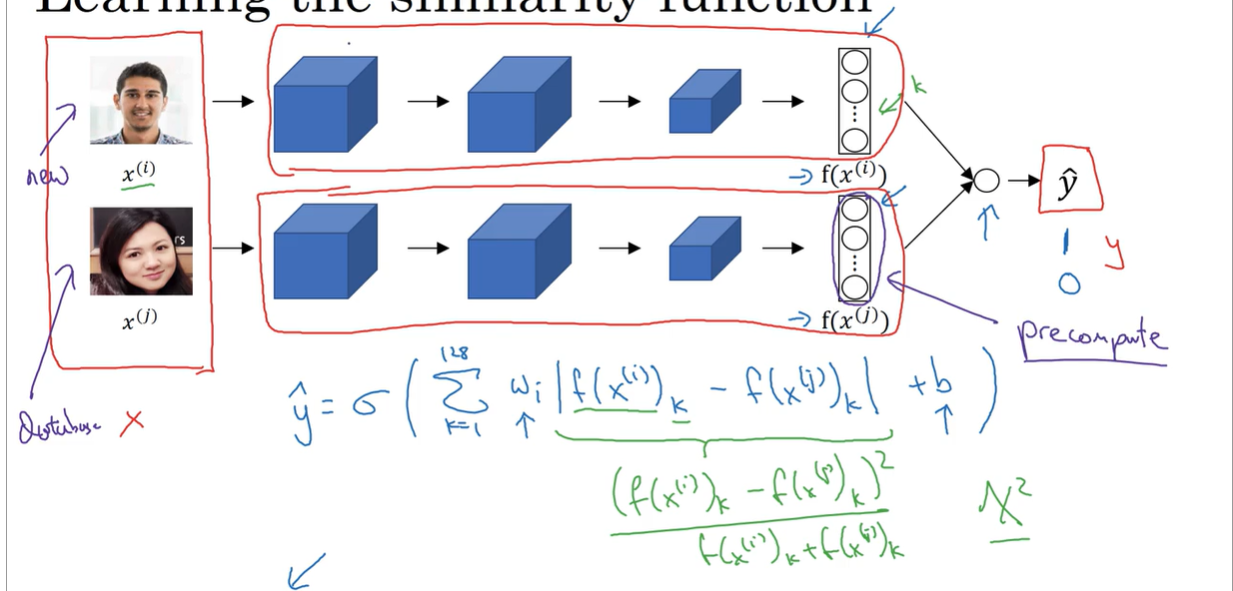
难点解决解决: learning a “similarity” function
Siamese network
- 预测阶段:两张照片,用同一个CNN,生成两个(n,1)向量。然后判断向量的距离,较近是同一个人,较远是不同人
- 训练阶段:如果是不同人,使距离大;如果是同一人,希望距离小
Triplet Loss
- 定义 Anchor 是一张照片,Positive 是同一人的另一张照片,Negative 是不同人的照片
- 我们希望 $\mid\mid f(A)-f(P)\mid\mid^2 \leq \mid\mid f(A)-f(N)\mid\mid^2$
- 也就是 $\mid\mid f(A)-f(P)\mid\mid^2 - \mid\mid f(A)-f(N)\mid\mid^2 +\alpha \leq 0$ 加入 $\alpha$是为了防止神经网络的输出恒为0
- loss function $L(A,P,N)=\max(\mid\mid f(A)-f(P)\mid\mid^2 - \mid\mid f(A)-f(N)\mid\mid^2 +\alpha,0)$
- cost function $J=\sum L(A,P,N)$
- 如果 A, P, N 随机选择,那么$\mid\mid f(A)-f(P)\mid\mid^2 - \mid\mid f(A)-f(N)\mid\mid^2 +\alpha \leq 0$很容易满足,所以选择的时候应当优先用不满足的。(郭飞:我理解这也是用 $\max(d1-d2+\alpha,0)$,而不是直接用$d1-d2$去训练的原因。因为已经合适的triplet,强行输入也没有梯度)
- 用batch learning
另一种算法:
Object Localization
难度排列
- image classification
- classification with localization
- detection(multiple objects)
classification with localization
纯classification 最后一层是 softmax 层。但classification 除了softmax 层之外,还输出一个bounding box(bx,by,bh,bw),分别代表中心、宽高
$y^T$=[pc,bx,by,bh,bw,c1,c2,c3,…,cn]
其中pc代表是否有目标物品,ci代表label
\(L(\hat y,y)=\left \{ \begin{array}{lll}
\sum(\hat y_i-y_i)^2 & if y_1=1\\
(\hat y_1-y_1)^2 & if y_1=0
\end{array}\right.\)
当然你也可以分别用square error(坐标部分)+log-likelyhood error
Landmark Detection
- 目的:你想让算法识别并输出脸上的各个关键点的位置。做法:把坐标作为y来学习
sliding windows detection
用已经训练好的 CNN 算法扫描图片的每一部分。
缺点是计算量极大。
分析扫描过程发现,其实有很多计算是重复的,那么可以用下面的方法来节省算力:
- FC实际上可以看成一个卷积层。
- 用原本的卷积网络就可以了

注意,原模型的 stride 相当于扫描的 stride
缺点是不能找到精确的位置(精度取决于算法结构中的 stride)
Bounding Box Predictions
YOLO algorithm(you only look once)
Y做成这样:$19198$,其中$19*19$对应原图片上的每个 grid,8对应的是 $y^T$=[pc,bx,by,bh,bw,c1,c2,c3,…,cn]
注意:
- 如果某个物体跨越多个 grid,也只有一个grid 对应的 y 的pc是1.
- 每个grid 的左上是(0,0),右下是(1,1)
- bh,bw也是相对于边界长度的,可以大于1
技巧
- Intersection Over Union(IOU)算法画出的边界,和ground truth 画出的边界,两者的交集除以两者的并集。
- 完全正确,则IOU=1,
- 一般认为0.5以上是“正确”,你也可以用其它阈值。
- Non-max Suppression. 有可能一辆车覆盖很多 grid,然后很多grid 都各自预测出一辆车的位置。Pc是概率,选出一个概率最大的。
- step1 discard all boxes with $p_c\leq 0.6$
- step2 pick the largest $p_c$
- step3 discard any remaining box with IoU$\geq 0.5$with the box output in step2
- step4 back to step2
- Anchor Boxes. 如果某个grid 有多个物体,怎么办?y多倍
R-CNN
- region-CNN:先运行一个 segment algorithm,然后每个区域上做label+bounding box
- Fast R-CNN:先运行一个 segment algorithm,然后每个区域上做label+bounding box,但是用卷积的方法
- Faster R-CNN:用卷积
但是 Faster R-CNN还是比YOLO慢一些
参考文献
deeplearning.ai
Neural Networks and Deep Learning
《Matlab神经网络原理与实例精解》陈明,清华大学出版社
《神经网络43个案例》王小川,北京航空航天大学出版社
《人工神经网络原理》马锐,机械工业出版社
白话深度学习与TensorFlow,高扬,机械工业出版社
《TensorFlow实战》中国工信出版集团
您的支持将鼓励我继续创作!
