【ELM】极限学习机
🗓 2018年01月18日 📁 文章归类: old_ann
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2018/01/18/elm.html
介绍
(不是ELMAN)
极限学习机(Extreme Learning Machine), 是一种前向型的神经网络(feedforward),弥补了BP的以下缺点:
- 训练速度慢,需要多次迭代。
- 容易陷入局部极小点
- 学习率选择困难
ELM的特点:
- Ease of use. No parameters need to be manually tuned except predefined network architecture.只有隐含层神经元个数需要我们设定
- Faster learning speed. Most training can be completed in milliseconds, seconds, and minutes.因为没有迭代计算
- Higher generalization performance. It could obtain better generalization performance than BP in most cases, and reach generalization performance similar to or better than SVM.
- Suitable for almost all nonlinear activation functions.. Almost all piecewise continuous (including discontinuous, differential, non-differential functions) can be used as activation functions.
- Suitable for fully complex activation functions. Fully complex functions can also be used as activation functions in ELM.很多函数都可以作为激活函数,甚至不可微函数也可以
- 看到一些材料上记载,为什么ELM效果良好还在学术讨论中
模型结构
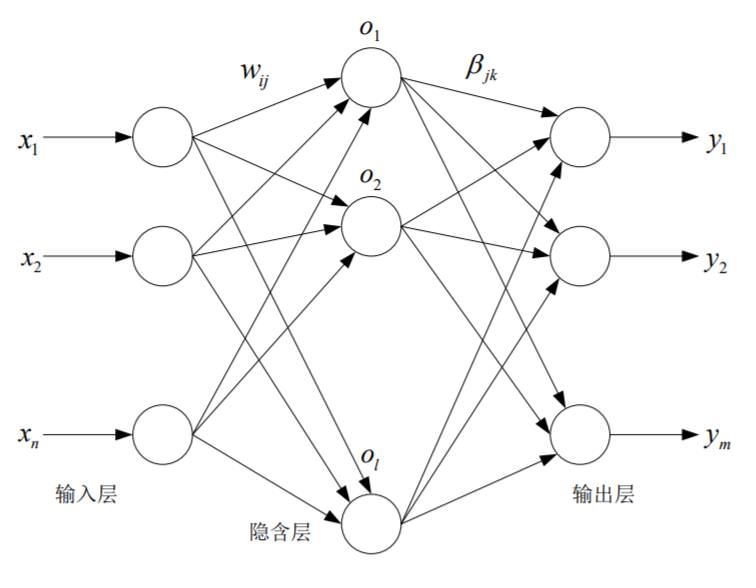
有以下特点:
隐含层到输出层的参数直接解方程的方法得到(而不是迭代)$\hat\beta=H^+T’$
输入层到隐含层的参数随机生成。
定理1
Q个样本,激活函数g无限可微,那么,
对于含Q个神经元的隐含层,对任意赋值的$W,\beta$,有这个结论:
隐含层输出矩阵H可逆,并且$\lVert H\beta-T\rVert=0$
定理2
Q个样本,激活函数g无限可微,给定任意误差$\varepsilon$,那么存在一个含K$(K<Q)$个神经元的隐含层,使得对于任意W和b,都有$\lVert H\beta-T\rVert < \varepsilon$

参考文献
《Matlab神经网络原理与实例精解》陈明,清华大学出版社
《神经网络43个案例》王小川,北京航空航天大学出版社
《人工神经网络原理》马锐,机械工业出版社
白话深度学习与TensorFlow,高扬,机械工业出版社
《TensorFlow实战》中国工信出版集团
您的支持将鼓励我继续创作!
