【spark, Hive, Hadoop, yarn】汇总
🗓 2018年03月27日 📁 文章归类: 0x11_算法平台
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2018/03/27/spark.html
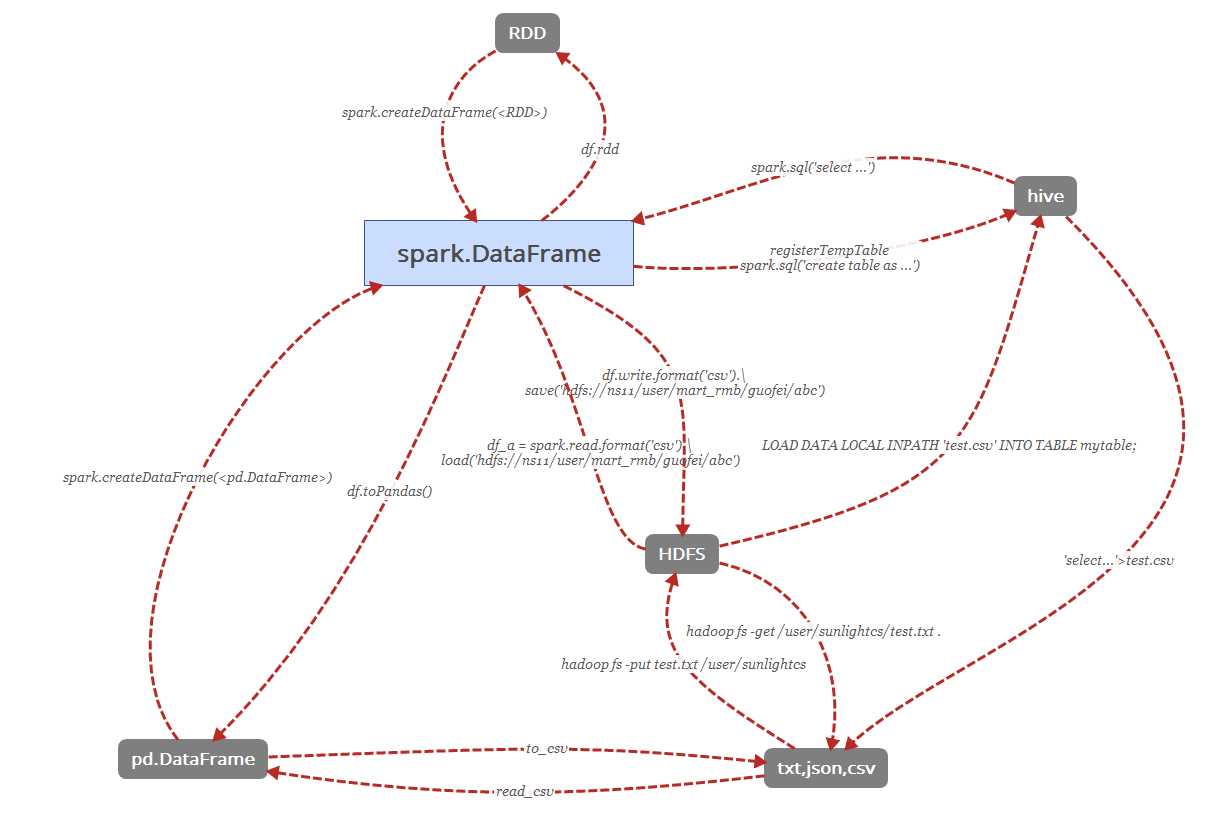
Spark
spark基本配置
from pyspark.sql import SparkSession
import os
os.environ['PYSPARK_PYTHON']="/usr/bin/python"
os.environ['PYSPARK_DRIVER_PYTHON']="/usr/bin/python"
spark = (SparkSession
.builder
.appName("mytest")
.enableHiveSupport()
.config("spark.executor.instances", "50")
.config("spark.executor.memory","4g")
.config("spark.executor.cores","2")
.config("spark.driver.memory","4g")
.config("spark.sql.shuffle.partitions","500")
.getOrCreate())
spark.sparkContext.uiWebUrl # Spark Web UI
spark.sparkContext.applicationId
cluster 模式下,想要提交多脚本,除了提交时附加外,还可以这样 spark.sparkContext.addPyFile('你的文件.py')
Hive to Spark
spark.sql('select ...')
Spark to Hive
- 插入普通表
df_data.registerTempTable('table2') spark.sql('create table tmp.tmp_test_pyspark2hive as select * from table2') - 静态插入分区表
df_data.registerTempTable('table2') spark.sql(''' INSERT OVERWRITE TABLE tmp.tmp_test PARTITION(dt='2018-05-02') select * from tmp_test ''') - 动态插入分区表
# 需要先把partition.mode配置为nonstrict spark.conf.set("hive.exec.dynamic.partition", "true") spark.conf.set("hive.exec.dynamic.partition.mode", "nonstrict") # 也可以在启用 SparkSession 时设置 # spark=SparkSession.builder.appName("tmp_test").\ # config("hive.exec.dynamic.partition", "true").\ # config("hive.exec.dynamic.partition.mode", "nonstrict").\ # enableHiveSupport().getOrCreate() df_data.registerTempTable('table2') spark.sql(''' INSERT OVERWRITE TABLE tmp.tmp_tmp_test PARTITION(a,b) SELECT c,d,e,a,b FROM tmp_test ''') - saveAsTable
df1_2.write.mode('overwrite').format('orc').partitionBy('dt').saveAsTable('tmp.tmp_test_guofei') # `append`, `overwrite`, `errorifexists`, `ignore` # 'overwrite' :普通表:被覆盖,分区表所有分区被覆盖(相当于先清除数据,然后写入数据) # 'append' : 无论是普通表还是分区表,原数据不会丢失,新数据也不会少 # 往往想要覆盖所涉及的分区,未涉及到的分区不变,两种方法: # 1. 上面的sql语句去 overwrite # 2. 先用命令drop相关分区,然后 append : # spark.sql(''' # ALTER TABLE tablename DROP IF EXISTS PARTITION(dt='{cal_dt_str}') # '''.format(cal_dt_str=cal_dt_str)) # 项目上,往往需要在建表后添加个人信息,spark.sql("ALTER TABLE tmp.tmp_test SET TBLPROPERTIES ('author' = 'guofei')") - insertInto
df.repartition('col1').write.insertInto('app.app_guofei8_test9', overwrite=True) # 1. 表必须已经存在 # 2. 其它效果与 saveAsTable 一样
Spark与pandas
df_data.toPandas() # 返回 pandas.DataFrame 类型
spark.createDataFrame(<pd.DataFrame>) # 返回 spark.DataFrame 类型
DataFrame 与 RDD
rdd1=df_data.rdd
spark.createDataFrame(rdd1)
Spark与HDFS
df.write.save(path="/user/mart_rmb/user/guofei8/skulist_test.csv", format='csv', mode='overwrite', header=True)
df_a = spark.read.load(path="/user/mart_rmb/user/guofei8/skulist_test.csv", format="csv", header=True)
TODO: 这个版本,比之前写的版本要简洁,但脑图还没更新
spark与硬盘文件
<pd.DataFrame>.to_csv('') # pandas 存储到本地csv
os.system("hive -e 'select * from ...'>test.csv") # hive存储到本地csv
Hive
bash中的hive基本操作
hive -e "select * from table1" # 把查询的结果打印在控制台上。
# `-e` SQL from command line
# `-S` Silent mode
hive -e "select * from table1" > data.csv #会将查询的结果保存到 data.csv
hive -S -e "select * from table1" > data.csv
# `-S` Silent mode,效果是不会在屏幕上打印OK和数据条数
hive -f sqlfile.sql # 执行文件中的sql
# `-f` SQL from files
硬盘文件到hive
create table if not exists mytable(key INT,value STRING)
ROW FOWMAT DELIMITED FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH 'test.csv' INTO TABLE mytable;
Hive常用命令
- 添加一列
alter table dev.table_name add COLUMNS (col1 double COMMENT '注释1', col2 double COMMENT '注释2' );
hadoop hdfs常用命令
hadoop fs # 查看Hadoop HDFS支持的所有命令
hadoop fs -ls # 列出目录及文件信息
hadoop fs -ls /user/abc # 列出指定目录信息
hadoop fs -ls -R # 循环列出目录、子目录及文件信息
# 本地复制
hadoop fs -put test.txt /user/sunlightcs
# 将本地文件系统的test.txt复制到HDFS文件系统的/user/sunlightcs目录下
hadoop fs -get /user/sunlightcs/test.txt
# 将HDFS中的test.txt复制到本地文件系统中,与-put命令相反
# 查看内容
hadoop fs -cat /user/sunlightcs/test.txt
# 查看HDFS文件系统里test.txt的内容
hadoop fs -tail /user/sunlightcs/test.txt
# 查看最后1KB的内容
# mkdir
hadoop fs -mkdir <path>
# 删除
hadoop fs -rm /user/sunlightcs/test.txt
# 从HDFS文件系统删除test.txt文件,rm命令也可以删除空目录
hadoop fs -rm -R /user/sunlightcs
# 递归删除(删除/user/sunlightcs目录以及所有子目录)
# 复制
hadoop fs -cp SRC [SRC …] DST
# 将文件从SRC复制到DST,如果指定了多个SRC,则DST必须为一个目录
# 移动
hadoop fs -mv URI [URI …] <dest>
# 把一个路径移动到另一个路径
# 统计文件数量
hadoop fs -count [-q] PATH
# 查看PATH目录下,子目录数、文件数、文件大小、文件名/目录名
# TODO: 还不知道-q什么效果
hadoop fs -du PATH
# 显示该目录下每个文件或目录的大小(只显示下一级目录和文件)
hadoop fs -du -s PATH
# 类似于du,PATH为目录时,会显示该目录的总大小(只显示一个目录)
# hadoop fs -chgrp [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录所属群组,选项-R递归执行,跟linux命令一样
#
# hadoop fs -chown [-R] /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录拥有者,选项-R递归执行
#
# hadoop fs -chmod [-R] MODE /user/sunlightcs
# 修改HDFS系统中/user/sunlightcs目录权限,MODE可以为相应权限的3位数或+/-{rwx},选项-R递归执行
#
# hadoop fs -expunge
# 清空回收站,文件被删除时,它首先会移到临时目录.Trash/中,当超过延迟时间之后,文件才会被永久删除
#
# hadoop fs -getmerge SRC [SRC …] LOCALDST [addnl]
# 获取由SRC指定的所有文件,将它们合并为单个文件,并写入本地文件系统中的LOCALDST,选项addnl将在每个文件的末尾处加上一个换行符
#
# hadoop fs -touchz PATH
# 创建长度为0的空文件
#
# hadoop fs -test -[ezd] PATH
# 对PATH进行如下类型的检查:
# -e PATH是否存在,如果PATH存在,返回0,否则返回1
# -z 文件是否为空,如果长度为0,返回0,否则返回1
# -d 是否为目录,如果PATH为目录,返回0,否则返回1
#
# hadoop fs -text PATH
# 显示文件的内容,当文件为文本文件时,等同于cat,文件为压缩格式(gzip以及hadoop的二进制序列文件格式)时,会先解压缩
#
# hadoop fs -help ls
# 查看某个[ls]命令的帮助文档
yarn: Hadoop 的资源管理系统
yarn application -kill application_id # 杀掉一个 job
批量提交任务
实现功能:
- submit时传入参数 用sys.argv来读取submit时附加的参数
- 脚本中调用别的包
- 串行和并行提交重跑,基本不用改代码
- 提交的spark脚本全部运行完毕后,打印每个脚本的返回码、运行时间、运行开始时间、运行结束时间
- 如果有脚本运行失败,退出时返回错误码
1. 被提交脚本
重点看一下传入参数的设计 app_1_2_1.py(被提交的spark脚本):
# coding=utf-8
from pyspark.sql import SparkSession
import os
import sys
import numpy as np
# 读取入参
arrs = sys.argv
cal_dt_str = eval(arrs[1])['cal_dt_str']
spark = SparkSession.builder.appName("app_name_"+cal_dt_str).enableHiveSupport().getOrCreate()
# %% 下面放你的代码
df = spark.createDataFrame([[cal_dt_str, np.random.randint(5)]], schema=['dt', 'rand_num'])
df.write.mode('overwrite').format('orc').partitionBy('dt').saveAsTable('app.app_test_guofei8')
spark.sql("ALTER TABLE app.app_test_guofei9987 SET TBLPROPERTIES ('author' = 'guofei9987')")
2. 串行提交
command1 = '''
spark-submit --master yarn \
--deploy-mode {deploymode} \
--driver-memory 6g \
--executor-memory 10g \
--num-executors 400 \
--executor-cores 6 \
--py-files ../your_py_files.zip \
{pyfile} "{arrs}"
'''
# --master:
# spark://host:port 独立集群作为集群url
# yarn yarn作为集群
# local 本地模式
# local[N] 本地模式,n个核心
# local[*] 本地模式,最大核心
# --deploy-mode:
# client本地,cluster集群
# --executor-memory 执行器的内存
# --driver-memory 驱动器的内存
import os
import datetime
cal_dt_str = (datetime.datetime.now() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')
# cal_dt_str='2019-05-05'
print('开始计算' + cal_dt_str + '的数据')
input_file = [
{'deploymode': 'cluster', 'pyfile': 'app_1_1.py', 'arrs': {'cal_dt_str': cal_dt_str}},
]
def func_run(args):
start_time = datetime.datetime.now()
code = os.system(command1.format(**args))
end_time = datetime.datetime.now()
return args['pyfile'], code, (end_time - start_time).seconds, \
start_time.strftime('%Y-%m-%d %H:%M:%S'), end_time.strftime('%Y-%m-%d %H:%M:%S')
result_code_list = [func_run(args=args) for args in input_file]
for i in result_code_list: print(i)
# for i in result_code_list:
# if i[1] != 0:
# raise error
3. 并行提交
# !/usr/bin/python
# coding=utf-8
# 并行回溯历史数据
import os
import datetime
import subprocess
import time
right_dt = datetime.datetime(year=2019, month=7, day=31)
left_dt = datetime.datetime(year=2019, month=7, day=1)
pyfile = 'app_1_1.py' # 你的待提交代码
step = -1 # 运行间隔
job_num = 5 # 同时提交这么多个
# 先把待提交的参数算出来
one_day = datetime.timedelta(days=1)
cal_dt_str_list = [(left_dt + i * one_day).strftime('%Y-%m-%d') for i in range((right_dt - left_dt).days + 1)][::step]
input_arr_list = [{'deploymode': 'client', 'pyfile': pyfile, 'arrs': {'cal_dt_str': cal_dt_str}}
for cal_dt_str in cal_dt_str_list
]
command1 = '''
spark-submit --master yarn \
--deploy-mode {deploymode} \
--driver-memory 6g \
--executor-memory 10g \
--num-executors 400 \
--executor-cores 6 \
--py-files ../core_code.zip \
{pyfile} "{arrs}"
'''
from IPython.display import clear_output # 这个是在jupter中显示方便
def paral_submit(input_arr_list, job_num=10):
# log是运行完的,subjob 是正在运行的,input_arr_list 是待运行的
log, subjob = [], dict()
while len(input_arr_list) > 0 or len(subjob) > 0:
if len(subjob) < job_num and len(input_arr_list) > 0:
input_arr = input_arr_list[0]
cal_dt_str = input_arr['arrs']['cal_dt_str']
subjob[cal_dt_str] = subprocess.Popen(command1.format(**input_arr), shell=True)
input_arr_list = input_arr_list[1:]
subjob_status = [[cal_dt_str, subjob[cal_dt_str].poll()] for cal_dt_str in subjob]
subjob_status_finished = [[cal_dt_str, status] for cal_dt_str, status in subjob_status if status is not None]
for i, j in subjob_status_finished:
subjob.pop(i)
log.extend(subjob_status_finished) # 完成的 job 加入log
time.sleep(1) # 每秒检测一次
clear_output() # jupyter 中显示方便,每次抹除
print('finished:', log)
print('running:', subjob.keys())
print('not running:', [i['arrs']['cal_dt_str'] for i in input_arr_list])
time.sleep(1) # 每秒检测一次
print('并行模块执行完毕,返回码如下:', log)
return log, [i for i in log if i[1] != 0]
paral_submit(input_arr_list,job_num=10)
批量处理hive表
import subprocess
tables_all=subprocess.check_output('''
hive -e 'use app;show tables'
''',shell=True).decode('utf-8').split('\n')
table_guofei=[table for table in tables_all if table.find('guofei')>=0]
for table in table_guofei:
drop_code=subprocess.check_output('''
hive -e 'drop table app.{table}'
'''.format(table=table),shell=True)
print(drop_code,table)
串行循环
调研数据时,往往需要循环写表。
import datetime
right_dt = datetime.datetime(year=2019, month=8, day=1)
left_dt = datetime.datetime(year=2019, month=2, day=1)
pyfile = 'long_1.py'
step = 1 # 运行间隔
job_num = 1
IsFirstLoop=True
oneday=datetime.timedelta(days=1)
# paral_run.paral_submit(left_dt=left_dt, right_dt=right_dt, pyfile=pyfile, step=step, job_num=job_num)
cal_dt = left_dt if step > 0 else right_dt
while True:
if cal_dt>right_dt or cal_dt<left_dt:break
cal_dt_str=cal_dt.strftime('%Y-%m-%d')
submit(cal_dt_str,spark,IsFirstLoop)
print(cal_dt_str+' done@'+datetime.datetime.now().strftime('%H:%M:%S')+', ')
IsFirstLoop=False
cal_dt+=step*oneday
print('All done!')
你的脚本
def submit(cal_dt_str, spark, IsFirstLoop):
if IsFirstLoop:
write_mode='overwrite'
else:
write_mode='append'
# 这里是你的脚本
# 然后写表:
df.write.mode(write_mode).format('orc').partitionBy('dt').saveAsTable('app.app_guofei8_test')
if IsFirstLoop:
spark.sql("ALTER TABLE app.app_guofei8_test_data_0909 SET TBLPROPERTIES ('author' = 'guofei8')")
参考文献
https://blog.csdn.net/wy250229163/article/details/52354278
https://databricks.com/blog/2016/08/15/how-to-use-sparksession-in-apache-spark-2-0.html
https://blog.csdn.net/gz747622641/article/details/54133728
您的支持将鼓励我继续创作!
