【OpenCV1】读写、空间变换
🗓 2018年10月30日 📁 文章归类: 0x25_CV
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2018/10/30/cv.html
总揽
pip install opencv-python
系列文章
- io/运算/色彩变换/几何变换
- 滤波/形态学操作/图像梯度/边缘检测/图像金字塔/图像轮廓
- 直方图/傅立叶变换/霍夫变换
- 图像分割
贡献库是社区开发的算法 pip install opencv-contrib-python,文档
- bioinspired:生物视觉模块。
- datasets:数据集读取模块。
- dnn:深度神经网络模块。
- face:人脸识别模块。
- matlab:MATLAB 接口模块。
- stereo:双目立体匹配模块。
- text:视觉文本匹配模块。
- tracking:基于视觉的目标跟踪模块。
- ximgpro:图像处理扩展模块。
- xobjdetect:增强 2D 目标检测模块。
- xphoto:计算摄影扩展模块。
简单的成像模型
$f(x,y)=i(x,y)r(x,y)$
- x,y 是坐标
- $i(x,y)$ 入射分量,取决于光源
- $r(x,y)$ 反射分量,取决无物体的材质
数字图像表示 现实中的坐标 $x,y$ 和值 $f(x,y)$ 都是连续的。数字图像中是连续的(叫做 采样)
这样就产生了一系列的概念。
- 饱和度。实际图像灰度值超出饱和度,被剪成最高值。
- 噪声。较暗的区域。
- 分辨率
- 灰度分辨率。灰度级可分辨的最小变化。
读写图像
import cv2
# 读
img = cv2.imread('img.jpg')
img = cv2.imread('img.jpeg', flags=cv2.IMREAD_UNCHANGED)
# 显
cv2.imshow(winname='title', mat=img)
cv2.waitKey(delay=0) # 单位是毫秒,0代表无限等待。若在等待时间内按下任意键则返回按键的ASCII码,程序继续运行。若没有按下任何键,超时后返回-1
cv2.destroyAllWindows()
# cv2.destroyWindow('title') # 也可以
# 写
cv2.imwrite('filename',img)
# 可以指定图像质量
cv2.imwrite(filename='img.jpg', img=img, params=[cv2.IMWRITE_JPEG_QUALITY, i]) # i是0~100的整数,表示图像质量,默认95
cv2.imwrite(filename='img.png', img=img, params=[cv2.IMWRITE_PNG_COMPRESSION, i]) # i是0~9,表示压缩级别,默认3
# 读入为 bytes 然后用 opencv 读入 bytes
with open(filename, 'rb') as f:
img_bytes = f.read()
image = cv2.imdecode(np.frombuffer(img_bytes, np.uint8), cv2.IMREAD_GRAYSCALE)
| flag对应的值 | 含义 |
|---|---|
| cv2.IMREAD_COLOR | (默认)BGR 图像 |
| cv2.IMREAD_UNCHANGED | 读入完整图片,包括alpha通道 |
| cv2.IMREAD_GRAYSCALE | 单通道的灰度图像 |
| cv2.IMREAD_ANYDEPTH | 当载入的图像深度为 16 位或者 32 位时,就返回其对应的深度图像;否则,将其转换为 8 位图像 |
| cv2.IMREAD_ANYCOLOR | 以任何可能的颜色格式读取图像 |
注意:
- 默认读进来的通道顺序是 BRG
- 0是颜色最少,255是颜色最多。如果3个通道全是255代表白色,全是0代表黑色
- png 图片还有一个 alpha 通道,255 表示完全不透明,0表示完全透明
- 按照加法三原色做叠加,如下图:
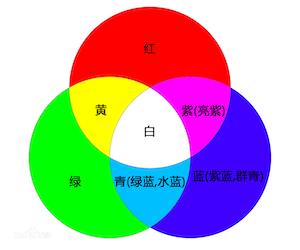
颜色变换
- GRAY(灰度图像)
- 8 位灰度图,其具有 256 个灰度级,像素值的范围是
[0,255] - RGB2GRAY 公式
Gray = 0.299 · 𝑅 + 0.587 · 𝐺 + 0.114 · 𝐵 - GRAY2RGB 公式
R = Gray; G = Gray; B = Gray
- 8 位灰度图,其具有 256 个灰度级,像素值的范围是
- XYZ 色彩空间
- 由 CIE(International Commission on Illumination)定义的,是一种更便于计算的色彩空间,它可以与 RGB 色彩空间相互转换。
- 转换是一个3x3矩阵
- YCrCb 色彩空间
- Y 代表亮度,Cr 表示红色分量,Cb 表示蓝色分量
- JPEG 压缩需要用到
- RGB2YCrCb(不同系统的公式不同):
Y = 0.299 * R + 0.587 * G + 0.114 * BCr = 0.5 * R - 0.418688 * G - 0.081312 * B + 128.0Cb = -0.168736 * R - 0.331264 * G + 0.5 * B + 128.0- 很多工程资料将其叫做 YUV,但实际上指的是 YCrCb,注意区分
- YUV 与 YCrCb 类似,但 YUV 主要用于模拟信号
- RGB2YUV(不同系统的公式不同):
Y = 0.299 * R + 0.587 * G + 0.114 * BU = -0.14713 * R - 0.28886 * G + 0.436 * B + 128.0V = 0.615 * R - 0.51499 * G - 0.10001 * B + 128.0
- HSV 色彩空间
- 是一种基于人眼视觉感知的色彩模型
- 色调(Hue,也称为色相)光的颜色:色调与混合光谱中的主要光波长相关,例如“赤橙黄绿青蓝紫”分别表示不同的 色调。如果从波长的角度考虑,不同波长的光表现为不同的颜色,实际上它们体现的是色调的差异。
- 色调的取值区间为[0, 360],对应颜色转盘上的值
- 饱和度(Saturation)色彩的深浅程度:指相对纯净度,或一种颜色混合白光的数量。纯谱色是全饱和的,像深红色(红 加白)和淡紫色(紫加白)这样的彩色是欠饱和的,饱和度与所加白光的数量成反比。饱和度取值范围 [0, 1],具体为所选颜色的纯度值和该颜色最大纯度值之间的比值。饱和度的值为 0 时,只有灰度。
- 亮度(Value)取值范围也是 [0, 1],人眼感受到的光的明暗程度:反映的是人眼感受到的光的明暗程度,该指标与物体的反射度有关。对于色彩来 讲,如果在其中掺入的白色越多,则其亮度越高;如果在其中掺入的黑色越多,则其亮 度越低。
- HLS 色彩空间
- 包含的三要素是色调 H(Hue)、光亮度/明度 L(Lightness)、饱和度 S (Saturation)。
- CIE(International Commission on Illumination):面向人眼感知的颜色模型
CIEL*a*b*色彩空间:均匀色彩空间模型。L*代表亮度,a*代表绿色到红色分量,b*代表蓝色到黄色分量- 适用于各种颜色转换、色彩匹配任务
- 颜色之间的距离,此模型与人眼感知一致
CIEL*u*v*:另一个三位颜色空间- 适用于灯光、色彩配方、色彩转换,尤其处理光源相关的颜色变化,适用于需要考虑亮度对颜色补偿、各种光照条件下的颜色感知,适用于显示器显示和根据加色原理进行组合的场合,
- 强调对红色的表示,即对红色的变化比较敏感,但对蓝色的变化不太敏感。
- Bayer 色彩空间(Bayer 模型)
- 广泛地应用在 CCD 和 CMOS 相机中
- BGRA 色彩空间
- 在 RGB 色彩空间三个通道的基础上,还可以加上一个 A 通道,也叫 alpha 通道,表示透明度。
- PNG 图像是一种典型的 4 通道图像
- alpha 通道的赋值范围是[0, 1],或者[0, 255],表示从透明到不透明。
- CMYK(CMY)空间,
- C:(Cyan,青色,蓝色),M(Magenta,品红,红),Y(Yellow,黄色),K(Key)黑色
- 是一种用于印刷的颜色模式。是一种减色模型(对比RGB是加色模型),颜色是通过吸收(减去)光纤来混合的。
- K:黑色用来调整颜色深度和对比度,以节省其它颜色的油墨
- CMY 模型没有黑色,不太常用
# 灰度化,并且变成单通道
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 灰度转RGB(实际仍然是灰度)
img_rgb = cv2.cvtColor(img_grey, code=cv2.COLOR_GRAY2RGB)
# 可以转来转去:
# cv2.COLOR_X2Y,其中X,Y = RGB, BGR, GRAY, HSV, YCrCb, XYZ, Lab, Luv, HLS
# BGR
通道拆分和合并
b, g, r = cv2.split(img)
bgr = cv2.merge([b, g, r])
图像阈值计算
img[img > 128] = 255
二值化
thresh_val, img2 = cv2.threshold(img, thresh=127, maxval=255, type=cv2.THRESH_BINARY)
# thresh_val 是域值,img2 是二值化后的图
# 可以输入单通道/3通道,对应返回单通道/3通道
自适应阈值 otsu:对于一些浅色或深色图,设定127作为阈值未必合适(如下图),可以用 ostu 来计算阈值
img = cv2.imread("a2.jpeg", 0)
t1, thd = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
t, otsu = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
cv2.imshow("img", img)
cv2.imshow("thd", thd)
cv2.imshow("otsu", otsu)

局部自适应阈值:对每个局部做阈值处理
img = cv2.imread("a.jpeg", 0)
t1, thd = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
athdMEAN = cv2.adaptiveThreshold(img
, maxValue=255 # 最大值
, adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C # 局部平均值作为阈值
, thresholdType=cv2.THRESH_BINARY # 阈值处理方式
, blockSize=5 # 块大小,通常是3,5,7
, C=3)
athdGAUS = cv2.adaptiveThreshold(img
, maxValue=255
, adaptiveMethod=cv2.ADAPTIVE_THRESH_GAUSSIAN_C # 局部按照距离的加权作为阈值
, thresholdType=cv2.THRESH_BINARY
, blockSize=5
, C=3)
cv2.imshow("原图", img)
cv2.imshow("二值化", thd)
cv2.imshow("自适应二值化", athdMEAN)
cv2.imshow("高斯二值化", athdGAUS)

空间变换
https://www.cnblogs.com/shizhengwen/p/8719062.html
大小
关于大小:
img.shape分别是行数、列数、通道数- 对比:操作系统显示分辨率时,用的是 (列数、行数)
img.dtype很多是uint8类型
缩放
图像内插:一种扩大像素的方法。
- 近邻内插法:把图像中近邻的灰度赋值给新位置
- 双线性内插:用4个最近位置去估计新位置的灰度。$v(x,y)=ax+by+cxy+d$,其中4个系数由4个近邻点列出方程解出来。
- 双三次内插:用16个近邻点估计新位置。$v(x,y)=\sum\limits_{i=0}^3\sum\limits_{j=0}^3 a_{ij}x^iy^j$ (双三次内插是商业软件的标准内插方法)
imag1=cv2.resize(imag,(100,100)) # 改变分辨率到 (100, 100)
cv2.resize(src=img, dsize=(0, 0), fx=0.5, fy=0.6,
interpolation=cv2.INTER_NEAREST)
# fx, fy 可以指定缩放比例
# interpolation 指定差值方法:
# INTER_NEAREST, cv2.INTER_CUBIC
# 加白边:案例是上下各加50像素点
cv2.copyMakeBorder(img, 50, 50, 0, 0,
cv2.BORDER_CONSTANT,
value=(0, 0, 0))
| interpolation | 解释 |
|---|---|
| cv2.INTER_LINEAR | 双线性插值(默认方式) |
| cv2.INTER_NEAREST | 最临近插值。选择目标像素最近的那个。 |
| cv2.INTER_CUBIC | 三次样条插值,4×4 近邻区域进行三次样条拟合 |
| cv2.INTER_AREA | 区域插值,类似最临近插值方式 |
| cv2.INTER_LANCZOS4 | 8×8 近邻的 Lanczos 插值方法 |
| cv2.INTER_LINEAR_EXACT | 位精确双线性插值 |
| cv2.INTER_MAX | 差值编码掩码 |
| cv2.WARP_FILL_OUTLIERS |
翻转
img_flip = cv2.flip(img, flipCode=0)
# flipCode>0 左右翻转
# flipCode=0 上下翻转
# flipCode<0 上下左右同时翻转
坐标的空间变换理论篇
坐标变换的一般形式:$(x,y)=T((v,w))$,把原图中某个坐标 $(v,w)$ 映射到新坐标 $(x,y)$
例如,$(x,y)=T((v,w))=(v/2,w/2)$,这是一个把图像在两个方向上缩小一半的变换。
最常用的空间坐标变换:仿射变换:
\[\left [\begin{array}{ccc} x\\y\\1 \end{array}\right] = M \left [\begin{array}{ccc} u\\w\\1 \end{array}\right] = \left [\begin{array}{ccc} a_{00}&a_{01}&b_0\\ a_{10}&a_{11}&b_1\\ 0&0&1\\ \end{array}\right] \left [\begin{array}{ccc} u\\w\\1 \end{array}\right]\]举例来说:
- 尺度变换 \(\left [\begin{array}{ccc} c_1&0&0\\ 0&c_2&0\\0&0&1\\ \end{array}\right]\)
- 旋转变换 \(\left [\begin{array}{ccc} \cos \theta &\sin \theta &0\\ -\sin \theta &\cos\theta&0\\ 0&0&1\\ \end{array}\right]\)
- 平移变换 \(\left [\begin{array}{ccc} 1 &0&t_x\\ 0 &1&t_y\\ 0&0&1\\ \end{array}\right]\)
- 垂直偏移变换 \(\left [\begin{array}{ccc} 1&s_v&0\\ 0&1&0\\ 0&0&1\\ \end{array}\right]\)
- 水平偏移变换 \(\left [\begin{array}{ccc} 1 &0&0\\ s_h&1&0\\ 0&0&1\\ \end{array}\right]\)
在代码中,M矩阵省略最后一行
# 沿着坐标轴放大,并平移
M = np.array([[1.6, 0, -150],
[0, 1.6, -240]])
img_aff = cv2.warpAffine(src=img, M=M, dsize=img.shape[1::-1])
# 顺时针旋转15度
theta = 15 * np.pi / 180
M = np.array([
[np.cos(theta), -np.sin(theta), 0],
[np.sin(theta), np.cos(theta), 0]
], dtype=np.float32)
img_aff = cv2.warpAffine(src=img, M=M, dsize=img.shape[1::-1])
# cv2 提供了一个函数:根据旋转中心和旋转角,计算对应的矩阵
M = cv2.getRotationMatrix2D(center=(cols / 2, rows / 2), angle=2, scale=1)
# center是旋转的中心,angle是旋转角,scale是缩放大小
cv2.warpAffine( src, M, dsize[, flags[, borderMode[, borderValue]]] )
- dsize 代表输出图像的尺寸大小。多余部分裁剪,少的部分填充。计算大小时,左上角为起点。
- flags 代表插值方法,默认为 INTER_LINEAR。
- borderMode 代表边类型,默认为 BORDER_CONSTANT。当该值为 BORDER_ TRANSPARENT 时,意味着目标图像内的值不做改变,这些值对应原始图像内的异常值。
- borderValue 默认填充方式,BGR,默认是
(0,0,0)。
透视
给定4个顶点对应的位置,得到整个图片的映射
h, w = img.shape[:2]
A = cv2.getPerspectiveTransform(
src=np.array([[0, 0], [w, 0], [0, h], [w, h]], np.float32),
dst=np.array([[w / 2, 0], [w, 0], [0, h], [w, h / 2.0]], np.float32))
img2 = cv2.warpPerspective(img, A, (w, h))
点的顺序分别是左上、右上、左下、右下
像素映射
cv2.remap( src, map1, map2, interpolation[, borderMode[, borderValue]] )
- 功能:可以指定每个像素映射到新图的哪个位置
- map1,map2,其实可以理解为 mapx,mapy,输出的shape和他们一样,表示新图每个位置的像素,在旧图的哪个位置。可以为小数
- Interpolation 插值方法,取值同上
- borderMode 边界模式,borderValue 边界值
举例理解:
img=
[[120 183 101 252 219]
[ 51 106 168 221 118]
[147 16 3 14 159]
[219 67 254 16 62]]
mapx=
[[3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3.]
[3. 3. 3. 3. 3.]]
mapy=
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
# 结果:(就是新图所有点都是:旧图中第0行第3列的元素)
rst=
[[252 252 252 252 252]
[252 252 252 252 252]
[252 252 252 252 252]
[252 252 252 252 252]]
进阶用法:通过改变 mapx,mapy,可以做到
- 图像缩放
- 图像翻转
下面是用remap做图像翻转+改变分辨率+缩放
length, height = 800, 800
map_x, map_y = np.zeros((800, 800), dtype=np.float32), np.zeros((800, 800), dtype=np.float32)
for i in range(length):
for j in range(height):
map_x[j, i] = j / length * img.shape[1] * 1.5
map_y[j, i] = i / height * img.shape[0] * 1.2
img2 = cv2.remap(img, map1=map_x, map2=map_y, interpolation=cv2.INTER_LINEAR)
添加文字和图
添加文字
# 入参分别是图片、文本、像素、字体、字体大小、颜色、字体粗细
imgzi = cv2.putText(img=img, text="guofei", org=(500, 500),
fontFace=font, fontScale=2.5, color=(0, 0, 0), thickness=2)
添加集合图像
import numpy as np
import cv2
np.set_printoptions(threshold='nan')
# 创建一个宽512高512的黑色画布,RGB(0,0,0)即黑色
img=np.zeros((512,512,3),np.uint8)
# 画直线,图片对象,起始坐标(x轴,y轴),结束坐标,颜色,宽度
cv2.line(img,(0,0),(311,511),(255,0,0),10)
# 画矩形,图片对象,左上角坐标,右下角坐标,颜色,宽度
cv2.rectangle(img,(30,166),(130,266),(0,255,0),3)
# 画圆形,图片对象,中心点坐标,半径大小,颜色,宽度
cv2.circle(img,(222,222),50,(255.111,111),-1)
# 画椭圆形,图片对象,中心点坐标,长短轴,顺时针旋转度数,开始角度(右长轴表0度,上短轴表270度),颜色,宽度
cv2.ellipse(img,(333,333),(50,20),0,0,150,(255,222,222),-1)
# 画多边形,指定各个点坐标,array必须是int32类型
pts=np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
# -1表示该纬度靠后面的纬度自动计算出来,实际上是4
pts = pts.reshape((-1,1,2,))
# print(pts)
# 画多条线,False表不闭合,True表示闭合,闭合即多边形
cv2.polylines(img,[pts],True,(255,255,0),5)
#写字,字体选择
font=cv2.FONT_HERSHEY_SCRIPT_COMPLEX
# 图片对象,要写的内容,左边距,字的底部到画布上端的距离,字体,大小,颜色,粗细
cv2.putText(img,"OpenCV",(10,400),font,3.5,(255,255,255),2)
a=cv2.imwrite("picture.jpg",img)
cv2.imshow("picture",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
还有(上下这两部分代码都没整理)
import numpy as np
import cv2
# 定义一块宽600,高400的画布,初始化为白色
canvas = np.zeros((400, 600, 3), dtype=np.uint8) + 255
# 画一条纵向的正中央的黑色分界线
cv2.line(canvas, (300, 0), (300, 399), (0, 0, 0), 2)
# 画一条右半部份画面以150为界的横向分界线
cv2.line(canvas, (300, 149), (599, 149), (0, 0, 0), 2)
# 左半部分的右下角画个红色的圆
cv2.circle(canvas, (200, 300), 75, (0, 0, 255), 5)
# 左半部分的左下角画个蓝色的矩形
cv2.rectangle(canvas, (20, 240), (100, 360), (255, 0, 0), thickness=3)
# 定义两个三角形,并执行内部绿色填充
triangles = np.array([
[(200, 240), (145, 333), (255, 333)],
[(60, 180), (20, 237), (100, 237)]])
cv2.fillPoly(canvas, triangles, (0, 255, 0))
# 画一个黄色五角星
# 第一步通过旋转角度的办法求出五个顶点
phi = 4 * np.pi / 5
rotations = [[[np.cos(i * phi), -np.sin(i * phi)], [i * np.sin(phi), np.cos(i * phi)]] for i in range(1, 5)]
pentagram = np.array([[[[0, -1]] + [np.dot(m, (0, -1)) for m in rotations]]], dtype=np.float)
# 定义缩放倍数和平移向量把五角星画在左半部分画面的上方
pentagram = np.round(pentagram * 80 + np.array([160, 120])).astype(np.int)
# 将5个顶点作为多边形顶点连线,得到五角星
cv2.polylines(canvas, pentagram, True, (0, 255, 255), 9)
# 按像素为间隔从左至右在画面右半部份的上方画出HSV空间的色调连续变化
for x in range(302, 600):
color_pixel = np.array([[[round(180*float(x-302)/298), 255, 255]]], dtype=np.uint8)
line_color = [int(c) for c in cv2.cvtColor(color_pixel, cv2.COLOR_HSV2BGR)[0][0]]
cv2.line(canvas, (x, 0), (x, 147), line_color)
# 如果定义圆的线宽大于半斤,则等效于画圆点,随机在画面右下角的框内生成坐标
np.random.seed(42)
n_pts = 30
pts_x = np.random.randint(310, 590, n_pts)
pts_y = np.random.randint(160, 390, n_pts)
pts = zip(pts_x, pts_y)
# 画出每个点,颜色随机
for pt in pts:
pt_color = [int(c) for c in np.random.randint(0, 255, 3)]
cv2.circle(canvas, pt, 3, pt_color, 5)
# 在左半部分最上方打印文字
cv2.putText(canvas,
'Python-OpenCV Drawing Example',
(5, 15),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(0, 0, 0),
1)
cv2.imshow('Example of basic drawing functions', canvas)
cv2.waitKey()
打开摄像头
import cv2
capture = cv2.VideoCapture(0)
print(capture.get(0))
while(True):
# 获取一帧
ret, frame = capture.read()
# ret 是布尔值,表示当前帧是否正确;frame是np.array
# 转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 显示
cv2.imshow('frame', gray) # 如果是 int8 类型,就是0~256,如果是float,就是0~1
if cv2.waitKey(1) == ord('q'):
break
cv2.destroyAllWindows()
capture.release()
获取属性
capture.get(propId) # 可以获取摄像头的一些属性
capture.set(propId,value)
width, height = capture.get(3), capture.get(4)
录视频
capture = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'MJPG')
outfile = cv2.VideoWriter('output.avi', fourcc, 25., (640, 480))
while(capture.isOpened()):
ret, frame = capture.read()
if ret:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
播放本地视频
capture = cv2.VideoCapture('demo_video.mp4')
while(capture.isOpened()):
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(30) == ord('q'):
break
matplotlib 相关
img = plt.imread('image.jpg') # 返回一个m*n*3 的 np.array 对象
# 图像数组可以是以下类型
# M*N 此时数组必须为浮点型,其中值为该坐标的灰度;
# M*N*3 RGB(浮点型或者unit8类型)
# M*N*4 RGBA(浮点型或者unit8类型)
# 对比,用cv2读取的是BGR
# 显示图像
plt.imshow(img)
plt.show()
PIL.Image
读写
from PIL import Image
# 读
img = Image.open(fp='img.png')
# 存
img.save('img_new.png')
# 显
img.show()
# 看格式
img.mode # 'RGBA'
img.convert("RGB")
# '1': 把图像转为二值图
# 'L':将图像转换为灰度图像。
# 'RGB':将图像转换为 RGB 彩色图像。
# 'RGBA':将图像转换为带有透明通道的 RGBA 图像。
# 'CMYK':将图像转换为 CMYK 颜色模式。
# 'HSV':将图像转换为 HSV 颜色模式。
# 'YCbCr':将图像转换为 YCbCr 颜色模式。
img.size # 图像大小
img.info # 图像信息
# ???img.load()
img.getpixel(xy=(6, 10)) # 返回指定位置的像素值
img.putpixel(xy=(6, 10), value=(5,6,255)) # 设定像素值
img.getchannel(0) # 某一个通道作为单独的图片返回
img.tobytes() # 返回二进制形式
img.frombytes(my_bytes) # 二进制转图片
np.array(img) # 转 ndarray
读取 base64 格式的图片
import base64
from PIL import Image
import io
import cv2
import numpy as np
# base64 格式的图片
with open('测试图片.png', 'rb') as f:
s_b64 = base64.b64encode(f.read()).decode('utf-8')
# 转回为 bytes 类型
image_data = base64.b64decode(s_b64)
# PIL.Image 需要借助 io.BytesIO 来读取
image = Image.open(io.BytesIO(image_data))
# opencv 需要借助 np.frombuffer 来读取
image = cv2.imdecode(
np.frombuffer(image_data, np.uint8)
, cv2.IMREAD_COLOR
)
ImageChops:复制和比较
from PIL import ImageChops
# 复制一份
img1 = ImageChops.duplicate(image=img)
# 比较两个图片的差
img_diff = ImageChops.difference(img, img1) # 也是 <Image> 类型,可以 img_diff.show()
ImageEnhance:调整亮度、对比度等
from PIL import ImageEnhance
enhancer = ImageEnhance.Brightness(image=img)
img1 = enhancer.enhance(factor=0.5) # 亮度减半
img1.show()
enhancer = ImageEnhance.Color(image=img) # 颜色增强
ImageEnhance.Contrast(image=img)
ImageEnhance.Sharpness(image=img)
您的支持将鼓励我继续创作!
