【读论文】深度学习的泛化性
🗓 2019年11月02日 📁 文章归类: 0x00_读论文
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2019/11/02/nn_paper_understanding.html
Understanding / Generalization / Transfer
- Distilling the knowledge in a neural network (2015), G. Hinton et al. [pdf]
- Deep neural networks are easily fooled: High confidence predictions for unrecognizable images (2015), A. Nguyen et al. [pdf]
- How transferable are features in deep neural networks? (2014), J. Yosinski et al. [pdf]
- CNN features off-the-Shelf: An astounding baseline for recognition (2014), A. Razavian et al. [pdf]
- Learning and transferring mid-Level image representations using convolutional neural networks (2014), M. Oquab et al. [pdf]
- Visualizing and understanding convolutional networks (2014), M. Zeiler and R. Fergus [pdf]
- Decaf: A deep convolutional activation feature for generic visual recognition (2014), J. Donahue et al. [pdf]
1. Distilling the Knowledge in a Neural Network
- Distilling the knowledge in a neural network (2015), G. Hinton et al. pdf
abstract&introduction
ensemble 方法确实不错,但太消耗算力。这里提出一种 Distilling the Knowledge 的方法,使训练快速、并行。
我们可以训练一个笨重的(cumbersome)模型,然后用 Distilling the Knowledge 的方法,最终在部署阶段部署一个轻量的模型。
在很多个class的多分类模型中,有些class的概率很低,但objective function仍然要计算他们。
模型
先用 cumbersome model 拟合,得到softmax层,
$p_i=\dfrac{\exp(v_i/T)}{\sum\exp(v_i/T)}$
这一步与我们一般的理解一样。
下一步做distillation,就是把上一步的$p_i$作为y,因为这一步和上一步都用交叉熵作为cost function,我们得到 $\dfrac{\partial C}{\partial z_i}=\dfrac{1}{T}(q_i-p_i)=\dfrac{1}{T}(\dfrac{\exp(z_i/T)}{\sum_j\exp(z_j/T)}-\dfrac{\exp(v_i/T)}{\sum\exp(v_j/T)})$
近似 当T足够大时:
$\dfrac{\partial C}{\partial z_i}\approx \dfrac{1}{T}(\dfrac{1+z_i/T}{N+\sum_j z_j/T}-\dfrac{1+v_i/T}{N+\sum_j v_j/T})$
在假设logits 是 zero-meaned
$\dfrac{\partial C}{\partial z_i}\approx \dfrac{1}{NT^2}(z_i-v_i)$
实验
使用了 MNIST,speech recognition 做了实验,效果良好。
我的理解
模型描述起来其实简答,但要理解为什么work,就要费一定的功夫了。
关于 T(temperature)
写了个代码去模拟
import numpy as np
import matplotlib.pyplot as plt
z=np.random.rand(5,1)*20
T=np.arange(1,10).reshape(1,9)
tmp=np.exp(z/T)
p=tmp/tmp.sum(axis=0)
plt.plot(p.T)
plt.show()
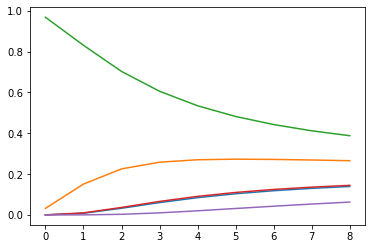
关于为什么work
下面是我的粗浅理解。
可以看成是一种 data augmentation,举例来说,你某次训练的标签是 [BMW, 卡车, 猫],对应的label是[1,0,0],用大模型生成的是[0.9,0.099,0.001],得到了类与类之间的相似性,或者说更多的信息(使用小网络时,减少了信息丢失)。
然后 temperature 这个 trick可以让这个信息更明显。
2. Deep neural networks are easily fooled
- Deep neural networks are easily fooled: High confidence predictions for unrecognizable images (2015), A. Nguyen et al. [pdf]
- 镜像地址 pdf
DNN识别图片,已经达到 near-human-level,我们想知道算法与人脑的区别。
观察到这些现象:
- 一副狮子图片,稍加变化,就会被识别成其它东西。这个变化对人类来说微乎其微。
- 有时候,会把一些对人类无意义的图片,识别成某些类,with 99.99% confidence(叫做 fooling images)(论文给出了一些图片例子,可以看一眼)
- 把 fooling examples 作为新标签去训练,得到的新DNN,同样无法避免 fooling example 的现象。
Methods
主要选用 AlexNet 做实验。此外还用 LeNet 做了验证。
生成新图片(novel images)的算法是 evolutionary algorithms (EAs) Traditional EAs 在单目标或少数目标优化中表现良好。我们用一套新算法, the multi-dimensional archive of phenotypic elites MAP-Elites
MAP-Elites
MAP-Elites 的特点,按原文说是:
MAP-Elites works by keeping the best individual found so far for each objective.
(我理解这应该是选择算子的特点)
fitness:把image放入DNN,if the image generates a higher prediction score for any class than has been seen before, the newly generated individual becomes the champion in the archive for that class.
(这个在细节上可以有多个理解,就不翻译了)
作者提供了两种encoding技术(用基因表示图片的技术)
1. direct encoding
例如MNIST用28×28的灰度整数,ImageNet用256×256的三色整数(H.S.V).每个位置的变异率是10%,每1000代变异率减半。用polynomial mutation operator(这个不太明白)with a fixed mutation strength of 15.
2. indirect encoding
处理regular images,这种编码的特点是进行了一些压缩,所以某一基因,可能对应图片上的多个部分。
具体的,用了一种叫做 compositional pattern-producing network (CPPN) 的方法。
(其实CPPN这一块没看太明白,回头多看几遍再来补)
结论
结论1泛化性:用了两种情况
- DNNA和DNNB have identical architecture,但初始化不一样。
- DNNA和DNNB have different architecture,但使用同样的训练集。
有些图片会在DNNA上得到高分,但在DNNB上没有得高分。
结论2:用 fooling image 作为标签训练新模型
- 新模型有n+1个label,训练完后,发现新模型自己也有 fooling image
结论3:梯度上升法
- 第三种找到 fooling image 的方法。
3. How transferable are features in deep neural networks
Transferability 受两种 issue 的负面影响
- 做一个任务的网络,用到另一个任务上,而两个任务目的有差别
- 优化困难。
很多做图像 DNN 都有这么一个特点:第一层很像 Gabor filters and color blobs。这些DNN如此相似,以至于如果看到不相似的,人们第一怀疑是不是参数给错了,或者代码bug了。
而且这一现象普遍存在于不同的 datasets,training objectives,甚至是不同的网络:(supervised image classification, unsupervised density learning, unsuperived learning of sparse represetations)。
除此之外,网络的最后一层显然没有这个现象,比如做分类,最后一层是softmax层,那么每一个 output 对应一个你事先规定好的label。
我们把有这个现象叫做 general,例如前面提到的神经网络第一层。没有这个现象叫做 specific,例如前面提到的神经网络最后一层。
自然想要提出几个问题:
- general 和 specific 的程度如何量化(quantify)
- transition 是在一层出现的,还是在多层出现的(Does the transition occur suddenly at a single layer, or is it spread out over several layers?)
- transition 在哪里出现:第一层附近,中间,还是最后几层?
对这些问题的研究,有助于 transfer learning 的研究。
transfer learning
文章第二页介绍了 transfer learning 的做法,不多说。注意两个叫法:先训练的数据集叫做 base dataset,后训练的数据集叫做 target dataset
显然,如果target datasets 的数量远少于 base datasets ,transfer learning 是一个很好用的手段,且能防止过拟合。
transfer learning 可以这样: 保留前n层,后面的层可以重新设计(也可以用base network的),然后后面的层初始化,然后
- 一起训练(fine-tuned )。
- 前n层不参与训练(frozen)
使用哪一种方法取决于 target datasets 的大小和前n层的参数的个数。
- 如果 target datasets 太小,前n层参数太多,用 fine-tune 可能导致 overfitting
- 如果 target datasets 较大,前n层参数不多,用 fine-tune 可以提升表现。
- 当然,如果 target datasets 很大,你也用不着 transfer learning 了,直接训练一个新模型也可以。
Generality vs. Specificity Measured as Transfer Performance
ImageNet有1000个class,随机分成2组,各500个class,分别训练两个8层CNN
起名叫 baseA, baseB
n从1到7,构造如下的网络:(下面以n=3为例)
- B3B。取 baseB 的前3层,frozen 的方式做 transfer learning,训练用B组数据(控制组)
- A3B。取 baseA 的前3层,frozen 的方式做 transfer learning,训练用B组数据。如果A3B的表现和baseB一样良好,那么有理由相信,前三层是 general 的(至少对于B组数据是的)。
论文作者又做了下面这些实验
- n从1到7
- A,B两组颠倒过来再做一套
- 不用 frozen 的方式,二用 fine-tuned(得到的网络起名为B3B+, A3B+)
下面是论文里的图,表示的就是上面写的这个,还是挺一目了然的。
![]()
结果分析
![]()
- baseB 的 top-1 error 是比1000个class的网络低的,这是因为只有500个class
- 看BnB。当n为1,2 的时候,performance都和baseB一致,但3,4,5,6 的 performance 会变差。文章给出的解释是 fragile co-adapted features,feature 之间复杂的交互作用,不能仅靠后面的层来学习。(features that interact with each other in a complex or fragile way such that this co-adaptation could not be relearned by the upper layers alone.)这个我也是想了一会儿才理解,例如,baseB 本来后面的层学习到了一些比较奇怪的 feature 组合方法,但做BnB的时候,初始化没了,前n层又是固定的,所以学不出来了。
后面6,7层,performance 又变好了,这是因为结构简单了(一两层的神经网络),奇怪的 feature 组合方式也能学出来。 - BnB+ 作为 control ,证明 fine-tuned 的 performance 和 baseB 一样。
- AnB 1,2,3的 performance 稍有下降,4~7下降比较厉害,有上面对BnB的分析,我们知道原因有两个:the drop from lost co-adaptation and the drop from features that are less and less general. On layers 3, 4, and 5, the first effect dominates, whereas on layers 6 and 7 the first effect diminishes and the specificity of representation dominates the drop in performance.
- AnB+ 的情况让人惊讶。
- 以前觉得原因是规避了小数据上的过拟合,但这个结果显示,即使是大数据,表现也会变好。
- 这一结果的原因,也不能归结于训练次数的增多,因为 BnB+ 的训练次数也同样增多了,但结果并没有变好。
- 一个合理的解释是,baseA的学习结果还逗留在神经网络中,提升了泛化性。(原文the effects of having seen the base dataset still linger, boosting generalization performance. It is surprising that this effect lingers through so much retraining.)
换一下数据集看看
![]()
左上角的图,A,B这两个数据集不再随机分割,而是分为man-made/natural ,标签数量是449对551。然后话AnB和BnA图
右上角的图,是为了对2004和2009年两个大神的结论做进一步研究。当时的结论是,random convolutional filters, rectification, pooling, and local normalization 的组合,也能 work。
这里看到n=1,2 时,表现下降,并在n=3时表现变成0
4. CNN features off-the-Shelf: An astounding baseline for recognition
- CNN features off-the-Shelf: An astounding baseline for recognition (2014), A. Razavian et al. [pdf]
- 镜像地址 pdf
最近的研究表明,从CNN中提取的generic descriptors很强大,这篇论文进一步实锤了。
本文使用 OverFeat 模型(一种CNN模型),这个模型:
- 有96-1024个3×3-7×7的卷积核
- 激活函数是 Half-wave rectification
- Max Pooling是 3×3和5×5的
Visual Classification
- feature vector 做了 L2 normalize然后在这上面做SVM,这叫做CNN-SVM
- 训练集增强(方法是对样本进行裁切和旋转),这叫做CNNaug-SVM
- 这里用了 1-against-all 策略,但其他地方用 1-against-1 策略
- 数据有两组:Pascal VOC(1万张图片,20个类) 和 MIT-67 indoor scenes(1.5万张图片)
结论是,CNN-SVM 能良好的工作,CNNaug-SVM的表现更为良好
然后,论文又在 Object Detection 上做了实验,再其他数据集上也是。
结论
CNN在提取特征上,很有竞争力。
5. Learning and transferring mid-Level image representations using convolutional neural networks
- Learning and transferring mid-Level image representations using convolutional neural networks (2014), M. Oquab et al. [pdf]
- 镜像地址 pdf
CNN最近获得了成功,这得益于它能学到大量的 mid-Level image representations,而不是手动设计的低级特征。
然而,CNN需要巨大的参数量,以及大量的标记图片,限制了CNN在有限训练集上的应用。
这篇论文展示了,可以在一个训练集上训练得到数据,然后 transfer 到其它训练集。
(相关进展)名词:原本的训练叫做 source task,后来的训练叫做 target task
1. transfer learning 有一些用法:
- 弥补某些类别数据不足的问题
- 同一类别,source domain和target domain 数据情况不一致(例如图片的亮度、背景和视角不一样)
2. visual object classification
例如,一些 clustering 方法,(K-means,GMM),Histogram encoding,spatial pooling,等。
这些方法实践证明挺好,但还不清楚是否是最优的方案。
3. Deap Learning
不多说
transfering CNN weights
CNN 有 60M parameters,所以往往需要 transfer learning 来训练它
- 显式的做一个映射,把 source task 的 label 映射到 target task
- 借助一些 sliding window detectors 方法,下面会详细说
举例来说,你的 source task 是识别不同狗的种类,而 target task 仅需要把狗识别出来。
那么具体做法是,把最后一层softmax层(记为FC8)拿掉,然后加上一层ReLU(FCa)和一层softmax(FCb)
论文实验中用的 source task 的数据源图片是位于中心、背景噪声极低的。而target task 的数据源图片则未必在中心,且背景复杂。
训练时用了上面说的 sliding window detectors ,具体做法是,按不同比例裁剪图片,每个原始图片得到很多样本。
(具体裁剪比例就不摘抄了)
一些细节处理:
- 有些图片的某些裁剪,让背景中的物体变成图片的主要部分。论文用共同覆盖比例来解决。
- 裁剪出来的大多数图片,其实来源于背景。这导致训练集 unbalanced,可以是改变 cost function 的权重,但这里用的是重抽样。
训练
这部分是论文主要工作内容,是对各种数据集的验证结果,以及很多细节。最终结论是 transfer learning 是一个挺靠谱的事儿。
这部分就不摘抄了。
6. Visualizing and understanding CNN
最近人们发现,CNN的效果很好,但没人知道:
- 为什么表现好
- 如何提升效果
这篇论文就是要解决这个问题。并提出了一些创新的可视化方法。
做法
这篇文章用的是这种CNN:ReLU、带max pooling、(有时)有正则化。
(原文不够详细,我又查了其它资料)
deconvnet
1. Unpooling
pooling是不可逆的,因此需要一定的期缴来处理。在做pooling时,额外记最大的坐标,然后unpooling的过程中,把相应坐标填进去,其余格子置为0
下面这个示意图是在其他地方找的:
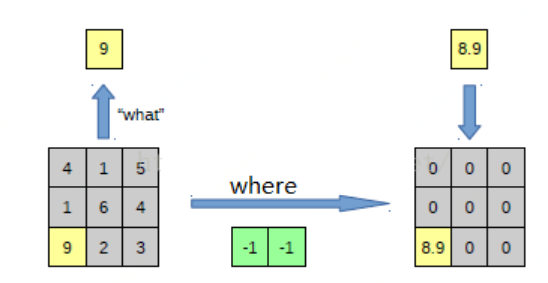
2. Rectification
因为用的激活函数是ReLu,因此反激活过程也是ReLu
3. Filtering
反卷积
训练:用的是 ImageNet 2012,细节就不摘抄了。
可视化:用前面写的 deconvnet,对某个激活值,不是给出最大的图片,而是给出top9
7. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
DeCAF 神经网络计算框架
您的支持将鼓励我继续创作!
