【读论文】神经网络的训练
🗓 2019年11月03日 📁 文章归类: 0x00_读论文
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2019/11/03/nn_papers_train.html
1. Improving neural networks by preventing co-adaptation of feature detectors
小数据用在大规模神经网络上的时候会有 overfiting
不过这个问题可以这样解决:每个训练样本随机忽略掉一半特征。这可以防止复杂的 co-adaptations,使每个神经元都要学习有用的特征。
dropout 可以看作是多个模型做平均。而用标准的方法做模型平均消耗很多计算资源。
Dropout 还可以看成是 Bayesian model averaging 的一种实现。Bayesian model averaging 的典型实现是 Markov chain Monte Carlo。Dropout 的优点是,在测试阶段全部通过就行了,无需对独立模型做平均。
Dropout 可以看成bagging,区别是bagging的众多模型是一次训练出来的。
Dropout的极端情况是 naive bayes,朴素贝叶斯的每个特征都是独自训练的。
Dropout 机理还可以类比“进化历史上性别的产生”,大量 co-adapted genes 在 robust 方面不如多替代的方式。另外,还降低了这种可能性:环境小变化导致适应性大降(这对应机器学习中的 overfitting)
2. Dropout: A simple way to prevent neural networks from overfitting
- Dropout: A simple way to prevent neural networks from overfitting (2014), N. Srivastava et al. [pdf]
Dropout 可以解决有效解决 overfiting,在视觉、语音、文本分类、生物任务上都有提升。
Overfiting 的问题可以用“训练很多模型求平均”来解决,但这样资源消耗很大。而且每个模型都需要大量的训练数据。Dropout可以同时解决这两个问题。
“dropout”指的是 dropping out units
训练一个带 dropout 的神经网络,相当于训练 2^n 个神经网络,并且它们有 shared weights
dropout 不止可以用于 feed-worward neural nets,可以以用于其它网络,例如 Boltzmann Machine
Motivation
Dropout 的想法来自进化论中的性别,看起来在进化中无性生殖是更好的方式,但实际上大多数高级生物都是有性生殖。
一个比较好的解释是,漫长的进化中,进化标准并非单体适应度,而是基因的综合能力。
如果基因与其它一组随机基因一起也表现良好,鲁棒性就更高。基因不能依靠一大组基因同时存在才能发挥作用,基因必须学会自己发挥作用或者与很少一组基因一起发挥作用。
按照这个理论,进化中性别的出现,不只是让有用的基因传播。而且还降低复杂的 co-adaptation,从而更可能提升单体适应度。与此相似,带 dropout 的神经网络节点必须学会与随机的其它节点合作,这让节点更加robust,并且迫使节点靠自己建立有用的特征,而不是依靠别的节点来修正自己的错误。
另一个角度:10个密谋每个密谋5个人参与,比1个密谋50个人参与更可能成功,因为后者需要每个人都表现良好。如果给充足的时间,后者可能会表现的更好,但环境变化后就不行了。complex co-adaptation 可以在训练集上表现良好,但新的测试集上可能就不行了。
Dropout可以被看成一种 regularize 方法,因为它给节点带来 noise.
引入noise的想法在 Denoisiong Autoencoders(2008) 提出过。这个模型的input添加noise,希望输出是去除掉 noise 的。
Dropout 已经大大提升效果了,它还可以配合 max-norm regularization, large decaying learning rates and high momentum
构建一个在固定球内的 weight vector,可以使得学习率非常大的情况下,不让 weight 飙升。进而 dropout 带来的 noise 可以让优化器探索更多的 weight space
max-norm regularization:限制 $\lVert w \rVert_2 \leq c$
比较
Bayesian neural networks (Neal, 1996)是一个做模型平均的正确方式,
- 它把先验和后验考虑到做平均值时的重要性中,而Dropout则用的简单平均。
- 它在面对小数据(如医疗类)非常有效,但面对大量数据的时候训练很慢,测试的时候也很消耗性能。但Dropout就快得多。
实测:在RNA预测细胞分化的样本上
- Bayesian Neural Network 效果最好
- Dropout 次之,但好于 SVM/PCA/early stopping
对特征的影响
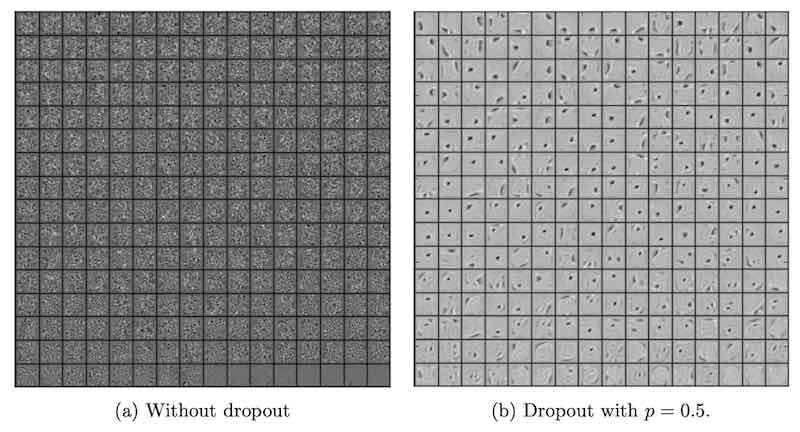
a和b两个模型在测试集上的准确率是一样的,但是显然b模型提取的是相对独立的特征。
如果没有 dropout,每个节点的功能会训练成为“修补其它节点错误”,这就是 complex co-adaptations, 它导致了 overfitting
【图】
加入dropout后,权重会变得稀疏,这也是好事
超参数
p作为超参数可以调整,在0.4-0.8之间的时候,测试集上的误差都小,超过这个范围的误差都大。
也可以pn固定,p变小时,网络规模n也变大。发现p=0.5是一个较好的值。
(后面又讲了RBMs)
3. Batch normalization: Accelerating deep network training by reducing internal covariate shift
- Batch normalization: Accelerating deep network training by reducing internal covariate shift (2015), S. Loffe and C. Szegedy [pdf]
训练深度神经网络复杂,是因为训练过程中,参数的分布一直在变化。就只好用较小的学习率和精心设计的初始化方法。
我们指出这个问题叫做 internal covariate shift,并且用 Batch Normalization 解决了这个问题。
而且它还是一种 regularizer, 有时候可以降低对 Dropout 的需求。
Batch Normalization 可以减少14倍的训练步骤,就可以达到原有的准确率。
4. Adam: A method for stochastic optimization
- Adam: A method for stochastic optimization (2014), D. Kingma and J. Ba [pdf]
Adam 是一种优化方式,它只需要一阶梯度和一点儿额外内存。
5. Training very deep networks
- Training very deep networks (2015), R. Srivastava et al. [pdf]
神经网络的深度非常重要,但是训练很深的网络比较困难,提出了一个新框架来解决此问题,叫做 highway networks。这从 LSTM 得到的启发,使用 adaptive gating units,使几百层的网络也能用梯度下降来训练。
原本一层是这样的:$y=H(x,w_T)$
加入 T (transform gate),C(carry gate),变成这样 $y=H(x,w_T)T(x,w_T)+xC(x,w_C)$
本文简化 $C=1-T$,简化为这样:
进而,做梯度下降的时候:
\[\frac{dy}{dx}=\left\{ \begin{array}{ccc} I& if&T(x,W_T)=0\\ H'(x,w_T)& if&C(x,W_T)=1 \end{array}\right.\]之后是实验结果
6. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification (2015), K. He et al. [pdf]
Rectified activation units 是前沿神经网络的必备部分,这里针对 image classification 任务,研究它
- 推广到 Parametric Rectified Linear Unit (PReLU) ,它能够更好的处理 cost 接近 0 的情况
- a robust initialization method,可以让我们训练极深的网络
CNN在 1000-class ImageNet 上的识别精度上已经超越人类了。
过去几年,我们见证了识别任务的巨大进步,它得益于两个方面1)更强大的模型 2)更好的策略去防止 overfitting。最近的一个突破是引入 ReLU
PReLU
不像传统激活函数,ReLU 不是一个 symmetric function,后果是输出值的平均不小于0,此性质影响
PReLU的公式:\(f(y_i)=\left\{ \begin{array}{ll} y_i & if & y_i>0\\ a_i y_i & if & y_i \leq 0 \end{array}\right.\)
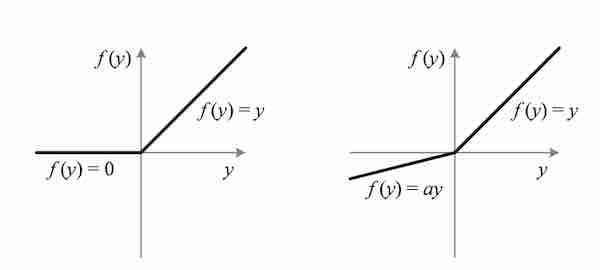
- 如果 $a_i=0$,它就是 ReLU
- 如果 $a_i$ 固定并且很小,它就是 Leaky ReLU (LReLU)
- 如果 $a_i$ 是可以训练的参数,它就是 Parametric ReLU (PReLU)
实测:
- 如果把所有的 ReLU 换成 PReLU,表现提升 1.2%
- 即使是把参数换成 channel shared (这只引入了13个额外的参数),表现也能提升1.1%
- 如果用 LReLU,并且 a=0.25,那么表现不会提升
initialization
Rectifier 比 sigmoid 更容易训练,但是如果初始化没做好,也会陷入到高阶非线性系统中,这里我们提出了robust initialization method.
之前用高斯分布做初始化,在 VGG 和我们的模型中,都遇到难以收敛的问题。为解决此问题,可以预训练一个8层卷积层的模型,但这样需要更多的训练时间,而且容易陷入局部最优。
基于 “Xavier” 初始化,本文提出了一种新的方法,用于 ReLU 和 PReLU
Xavier 初始化:
- 目的:使得新号强度不变,也就是说 $DY_i=DX_j$
- 为了可解,附加假设
- $\Delta Y,W$ 两两 iid
- $E\Delta Y=E W_{ij}=0$
- 结果: 如果是正态分布 $W_{ij} \sim N(0,\dfrac{2}{u+d})$;如果是均匀分布 $W_{ij} \sim U(-\sqrt{\dfrac{6}{u+d}},\sqrt{\dfrac{6}{u+d}})$。其中 u 是本层输入值的维度,d 是本层的节点个数
Xavier 假设网络中没有激活函数,而 Kaming initialization 考虑激活函数为 ReLU
结论:
- 如果是正态分布 $W_{ij} \sim N(0,\dfrac{2}{u})$;
- 如果是均匀分布 $W_{ij} \sim U(-\sqrt{\dfrac{6}{u}},\sqrt{\dfrac{6}{u}})$
Random search for hyper-parameter optimization
- Random search for hyper-parameter optimization (2012) J. Bergstra and Y. Bengio [pdf]
Grid Search 和手动搜索是用途广泛的超参数优化策略。
此文在实践和理论上证明随机法比 grid search 更为有效。grid search 浪费太多算力在不重要的维度/不重要的区域
Random Search 的优点:
- 可以随时停下来,之前跑过的 trials 仍然构成一个完整的 Random Search
- 可以新增trails,与之前的 trials 一起构成一个更大的实验
- 每个 trials 可以并行运行
- 任意一个 trial 失败,可以重启或者丢弃,不威胁蒸锅实验
未来:Random Search 策略未考虑结果,也没有自适应。未来的算法可以考虑这一点
您的支持将鼓励我继续创作!
