【HanLP】分词、词性标注、NER
🗓 2021年05月01日 📁 文章归类: 0x24_NLP
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2021/05/01/hanlp.html
介绍
相关项目
- HanLP:https://github.com/hankcs/HanLP
- 示例代码 Java:https://github.com/hankcs/HanLP/tree/v1.7.5/src/test/java/com/hankcs/book
- 示例代码 Python:https://github.com/hankcs/pyhanlp/tree/master/tests/book
- 模型文件下载, PKU1988语料下载
python版本安装
pip install pyhanlp
# 命令行试试(分词)
hanlp segment <<< '欢迎新老师生前来就餐'
Java
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.5</version>
</dependency>
词典
加载词典
TreeMap<String, CoreDictionary.Attribute> dictionary =
IOUtil.loadDictionary("data/dictionary/CoreNatureDictionary.mini.txt");
dictionary.size()
理论
给出了4种切分方法,代码
- 完全切分:找到全部可能的词,保留在词典种的那些
- 正向最长匹配:从左到右做最长的匹配。bad case:商品, 和服, 务
- 反向最长匹配:从右往左。bad case:项, 目的, 研究
- 双向最长匹配。把正向和反向都做一遍,按照这个规则选出最好的:1)选出词数最少的, 2)如果词数一样,选单字最少的
用最粗暴的遍历可以解决,为了提升性能,显然有些做法:
ArrayTrie 分词
HanLP 对上面的算法做了封装,直接拿来用即可:AC自动机+DoubleArrayTrie
String dict1="src/test/CoreNatureDictionary.mini.txt"; // 用户可以自定义词典
HanLP.Config.ShowTermNature = false; //不显示词性
AhoCorasickDoubleArrayTrieSegment segment = new AhoCorasickDoubleArrayTrieSegment(dict1);
System.out.println(segment.seg("江西鄱阳湖干枯,中国最大淡水湖变成大草原"));
[江西, 鄱阳湖, 干枯, ,, 中国, 最, 大, 淡水湖, 变成, 大, 草原]
还可以显示词性 DoubleArrayTrie
String dict1 = "src/main/data/dictionary/CoreNatureDictionary.mini.txt";
String dict2 = "src/main/data/dictionary/custom/上海地名.txt ns";
DoubleArrayTrieSegment segment = new DoubleArrayTrieSegment(dict1, dict2);
segment.enablePartOfSpeechTagging(true); // 激活数词和英文识别
HanLP.Config.ShowTermNature = true; // 显示词性
System.out.println(segment.seg("江西鄱阳湖干枯,中国最大淡水湖变成大草原"));
System.out.println(segment.seg("上海市虹口区大连西路550号SISU"));
// 显示每个词的词性:
for (Term term : segment.seg("上海市虹口区大连西路550号SISU")) {
System.out.printf("单词:%s 词性:%s\n", term.word, term.nature);
}
停用词
繁简体互转
https://github.com/hankcs/HanLP/blob/v1.7.5/src/test/java/com/hankcs/demo/DemoTraditionalChinese2SimplifiedChinese.java
System.out.println(HanLP.convertToTraditionalChinese("“以后等你当上皇后,就能买草莓庆祝了”。发现一根白头发"));
System.out.println(HanLP.convertToSimplifiedChinese("憑藉筆記簿型電腦寫程式HanLP"));
// 简体转台湾繁体
System.out.println(HanLP.s2tw("hankcs在台湾写代码"));
// 台湾繁体转简体
System.out.println(HanLP.tw2s("hankcs在臺灣寫程式碼"));
// 简体转香港繁体
System.out.println(HanLP.s2hk("hankcs在香港写代码"));
// 香港繁体转简体
System.out.println(HanLP.hk2s("hankcs在香港寫代碼"));
// 香港繁体转台湾繁体
System.out.println(HanLP.hk2tw("hankcs在臺灣寫代碼"));
// 台湾繁体转香港繁体
System.out.println(HanLP.tw2hk("hankcs在香港寫程式碼"));
// 香港/台湾繁体和HanLP标准繁体的互转
System.out.println(HanLP.t2tw("hankcs在臺灣寫代碼"));
System.out.println(HanLP.t2hk("hankcs在臺灣寫代碼"));
System.out.println(HanLP.tw2t("hankcs在臺灣寫程式碼"));
System.out.println(HanLP.hk2t("hankcs在台灣寫代碼"));
语言模型
一个句子出现的概率 $P(s) = p(w_1 w_2 … w_n) = p(w_1\mid w_0) p(w_2\mid w_0 w_1)…p(w_{k+1}\mid w_0 w_1…w_k)$
- 其中 $w_0 = $ BOS (Begin Of Sentence)
上面的模型是极难计算的,因此做一些简化:
- 假设满足马尔可夫性,也就是说 $p(w_t\mid w_0 w_1…w_{t-1}) = P(w_t\mid w_{t-1})$ ,于是 $P(s) = p(w_1\mid w_0) p(w_2\mid w_1)…p(w_{k+1}\mid w_k)$,称为 二元模型(bigram)
- n元语法(n-gram) 指的是每个单词的概率取决于之前的 n-1 个单词
- 1元语法(unigram) 其实就是记录每个单词的频率
平滑策略
n 越大,越有可能稀疏,我们可以用线性插值来平滑它。
例如 $p(w_t\mid w_{t-1})$ 很可能在语料中未出现,因此计算得到概率为0,但它的实际概率肯定不是0,这就是稀疏性。于是我们用一个平滑因子来平滑它 $p(w_t\mid w_{t-1}) := \lambda p(w_t\mid w_{t-1}) + (1-\lambda)p(w_t)$
分词语料库
- PKU 1998年《人民日报》语料库。误标率较高,不宜作为首选。
- MSR 微软亚洲研究院语料库。专有名词、姓名没有做切分,更符合认知
加载分词语料库
String MY_CWS_CORPUS_PATH = "src/main/data/test/my_cws_corpus.txt";
List<List<IWord>> sentenceList = CorpusLoader.convert2SentenceList(MY_CWS_CORPUS_PATH);
for (List<IWord> sentence : sentenceList) {
System.out.println(sentence);
}
语料库的例子:
商品 和 服务
商品 和服 物美价廉
服务 和 货币
Viterbi 分词训练和应用
public class DemoNgramSegment
{
public static void main(String[] args)
{
String TRAIN_PATH = "src/main/data/test/icwb2-data/training/msr_training.utf8";
String MSR_MODEL_PATH = "src/main/data/test/msr_cws_ngram";
// 训练模型
trainBigram(TRAIN_PATH, MSR_MODEL_PATH);
// 加载训练好的模型
Segment segment=loadBigram(MSR_MODEL_PATH);
// 模型的一些东西
CoreDictionary.getTermFrequency("商品");
CoreBiGramTableDictionary.getBiFrequency("商品", "和");
// 使用模型
System.out.println(segment.seg("商品和服务"));
}
/**
* 训练bigram模型
*
* @param corpusPath 语料库路径
* @param modelPath 模型保存路径
*/
public static void trainBigram(String corpusPath, String modelPath)
{
List<List<IWord>> sentenceList = CorpusLoader.convert2SentenceList(corpusPath);
for (List<IWord> sentence : sentenceList)
for (IWord word : sentence)
if (word.getLabel() == null) word.setLabel("n"); // 赋予每个单词一个虚拟的名词词性
final NatureDictionaryMaker dictionaryMaker = new NatureDictionaryMaker();
dictionaryMaker.compute(sentenceList);
dictionaryMaker.saveTxtTo(modelPath);
}
public static Segment loadBigram(String modelPath)
{
return loadBigram(modelPath, true);
}
/**
* 加载bigram模型
*
* @param modelPath 模型路径
* @param viterbi 是否创建viterbi分词器
* @return 分词器
*/
public static Segment loadBigram(String modelPath, boolean viterbi)
{
String MSR_MODEL_PATH = "data/test/msr_cws_ngram";
// HanLP.Config.enableDebug();
HanLP.Config.CoreDictionaryPath = modelPath + ".txt";
HanLP.Config.BiGramDictionaryPath = modelPath + ".ngram.txt";
return viterbi ? new ViterbiSegment().enableAllNamedEntityRecognize(false).enableCustomDictionary(false) :
new DijkstraSegment().enableAllNamedEntityRecognize(false).enableCustomDictionary(false);
}
}
训练过程:1)原理在上面贴了 2)保存下来的模型其实是如下的 2-gram 信息
橡胶@性能 1
橡胶@推进 2
...(几百万行)
预测过程:
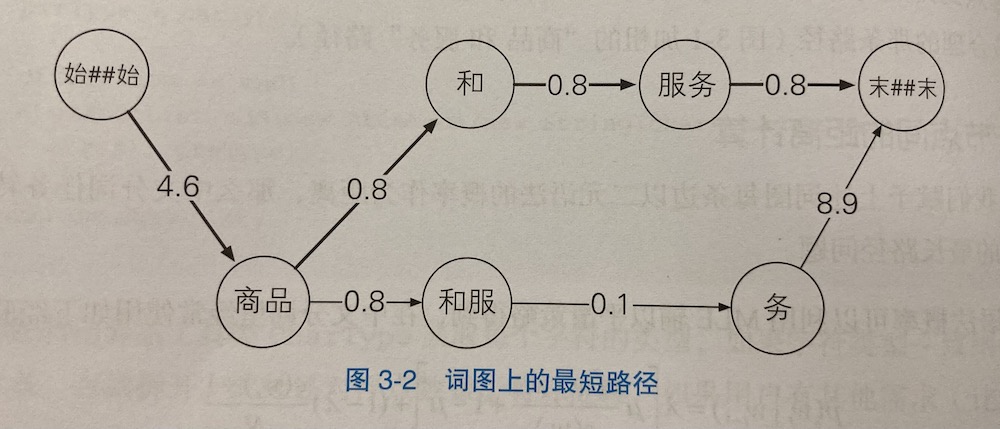
算法
- 用正向贪心算法和负向贪心算法都不合适
- 用 Viterbi 算法。原理:(感觉就是动态规划)
- 正向,获取起点到 i 的最小花费
- 逆向,从终点向前回溯,得到最短路径
分词中集成用户词典
原因:实际应用中,往往遇到某一专业领域的词语,而对应的语料却不足。因此用户自己整理一个词典,来弥补通用语料的不足。
// 关键点1:是否显示词性,默认为 true
HanLP.Config.ShowTermNature=true;
// 关键点2:加载用户词典(需要删除已缓存的同名的 bin 文件)
HanLP.Config.CustomDictionaryPath= new String[]{"src/main/data/dictionary/custom/CustomDictionaryF.txt"};
Segment segment = new ViterbiSegment();
String sentence = "社会摇摆简称社会摇";
segment.enableCustomDictionary(false);
System.out.println("不挂载词典:" + segment.seg(sentence));
// 关键点3:动态增加用户词典
CustomDictionary.insert("社会摇", "nz 100");
// 低优先级:仍然考虑词图距离最短,也就是把用户词典也作为概率图的一部分
segment.enableCustomDictionary(true);
System.out.println("低优先级词典:" + segment.seg(sentence));
// 高优先级:强制优先考虑用户词典
segment.enableCustomDictionaryForcing(true);
System.out.println("高优先级词典:" + segment.seg(sentence));
不挂载词典:[社会/n, 摇摆/vn, 简称/v, 社会/n, 摇/v]
低优先级词典:[社会/n, 摇摆/vn, 简称/v, 社会摇/nz]
高优先级词典:[社会摇/nz, 摆/v, 简称/v, 社会摇/nz]
额外:简单用法(一切用默认)
System.out.println(HanLP.segment("王国维和服务员"));
# [王国维/nr, 和/c, 服务员/n]
模型调优
- 增加关键词,例如姓名、机构名。加到
data/dictionary/custom/CustomDictionary.txt会生成一个 bin 文件。 ???我在原项目中成功了,在独立项目中没成功
隐马尔可夫模型
问题:根据上面的用法,我们可以把新词作为词典放到模型中,但有时候新词是很难穷举的。
例如:在某个项目中,我们希望把 “北京大学口腔医院” 或 “北京大学口腔医学研究所” 之类作为组织机构名不切分。而这种词在语料中几乎不会出现,更不要说整理出一份列表。
我们还需要从统计学系的角度找解决方案。
“我参观了北京大学口腔医院。”
- 分词结果 “我, 参观, 了, 北京大学, 口腔, 医院”
- 期望结果 “我, 参观, 了, 北京大学口腔医院”
序列标注:
- 对一个序列上每一个位置,预测其标签。
- 词性标注:这个标签是 词性
- 命名实体识别:标签是 BMES(Begin,Middle,End,Single)
推导到这里,可以看出,此任务非常适合隐马尔可夫模型
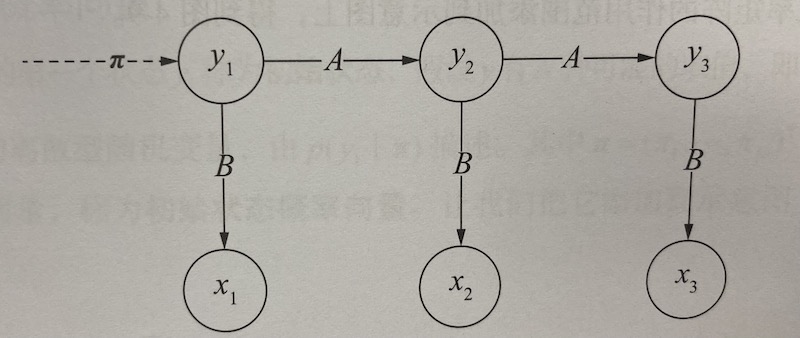
隐马尔可夫模型有三种用法:
- 样本生成问题,给定模型 $\lambda = (\pi,A,B)$,生成一个样本序列 $(x_1, y_1),…(x_n,y_n)$
- 模型训练问题,给定训练集,估计模型参数 $\lambda = (\pi,A,B)$
- 序列预测问题,给定模型 $\lambda = (\pi,A,B)$,并给定观测序列 $x_1,…, x_n$,求出最可能的序列 $y_1,…,y_n$
使用 例子
其父类实现了这些方法:
- generate:样本生成。用给定的 HMM,生成样本
- train:模型训练(因为是离散的,所以全都是用频率来估计概率)
- estimateStartProbability
- estimateTransitionProbability
- estimateEmissionProbability
- similar:评估两个 HMM 模型是否相似。原理是判断是否每个参数都差不多。
- predict:序列预测。训练完HMM后,我们知道 $P(x,y)$ 的所有的值了,接下来需要找一条概率最大的路径,这条路径就是最终的预测结果 (其实还是用 Viterbi 算法)
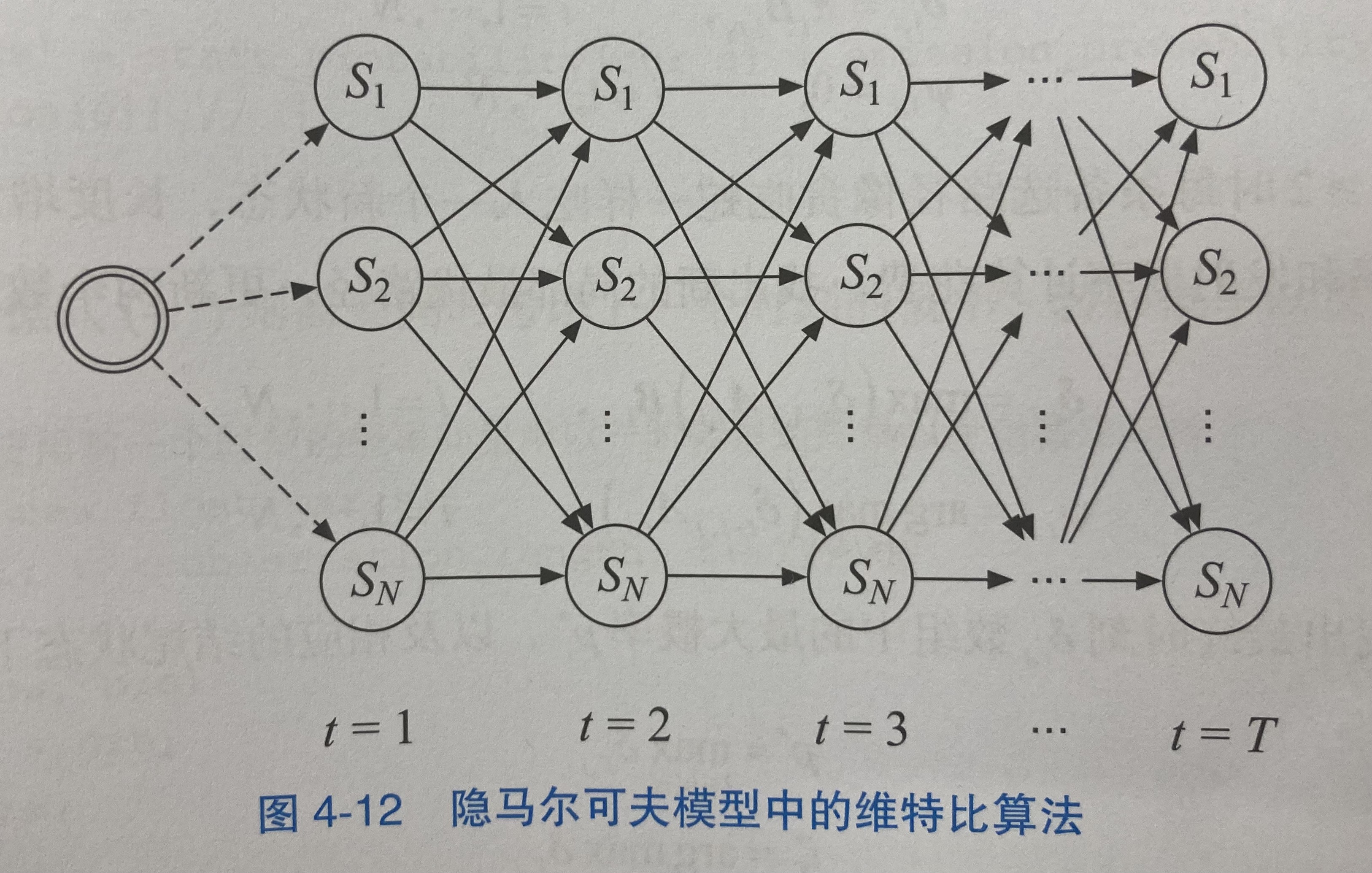
下面这个图看的更清楚:
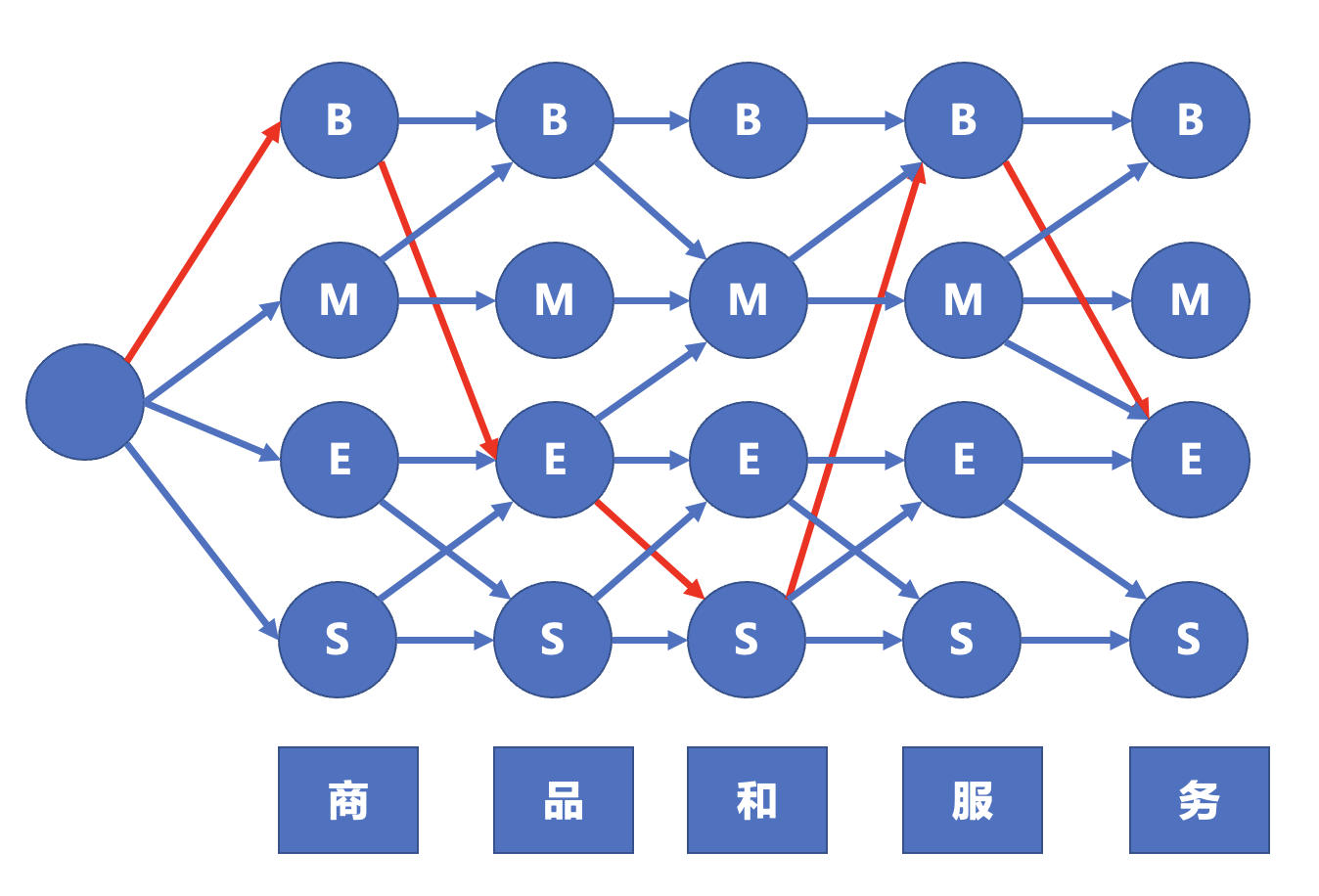
注:
- 其实每个圆圈都应当有箭头的,我给省了
- 红箭头是找到的最大概率
- 而二阶隐马尔可夫模型基于 $p(y_t=s_k\mid y_{t-1}=s_i,y_{t-2}=s_j)$,整体思路类似。
HMM分词的训练和预测
HanLP 在 HMMSegmenter extends HMMTrainer 这个类中已经整合了语料库格式转化、HMM训练、预测等,直接用就行了。
import com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel;
import com.hankcs.hanlp.model.hmm.HMMSegmenter;
import com.hankcs.hanlp.model.hmm.HiddenMarkovModel;
import com.hankcs.hanlp.model.hmm.SecondOrderHiddenMarkovModel;
import com.hankcs.hanlp.seg.common.CWSEvaluator;
import java.io.IOException;
public class CWS_HMM {
public static void main(String[] args) throws IOException {
trainAndEvaluate(new FirstOrderHiddenMarkovModel());
trainAndEvaluate(new SecondOrderHiddenMarkovModel());
}
public static void trainAndEvaluate(HiddenMarkovModel model) throws IOException {
// 训练
String trainPath = "src/data/test/icwb2-data/training/msr_training.utf8";
HMMSegmenter segmenter = new HMMSegmenter(model);
segmenter.train(trainPath);
// 使用
System.out.println(segmenter.segment("商品和服务"));
// 准召的评价
String TEST_PATH = "src/data/test/icwb2-data/testing/msr_test.utf8";
String OUTPUT_PATH = "src/data/test/msr_output.txt";
String GOLD_PATH = "src/data/test/icwb2-data/gold/msr_test_gold.utf8";
String TRAIN_WORDS = "src/data/test/icwb2-data/gold/msr_training_words.utf8";
CWSEvaluator.Result result = CWSEvaluator.evaluate(segmenter.toSegment(), TEST_PATH, OUTPUT_PATH, GOLD_PATH, TRAIN_WORDS);
System.out.println(result);
}
}
语料: 86k…[商品, 和, 服务]
P:78.49 R:80.38 F1:79.42 OOV-R:41.11 IV-R:81.44
语料: 86k…[商品, 和, 服务]
P:78.34 R:80.01 F1:79.16 OOV-R:42.06 IV-R:81.04
准召的评价:
- HMM 的 OOV(Out Of Vocabulary )大幅度提升到 40%,说明 40% 新词 被正确召回了
- 准召下降,说明出现了欠拟合
感知机
HanLP 实现了 线性模型
trainNaivePerceptron模型训练-
trainAveragedPerceptron模型训练 - ` model.compress(0.1)` 模型压缩
感知机用于分类
任务:训练一个分类模型:输入姓名,输出性别
语料:
赵伏琴,女
钱沐杨,男
孙竹珍,女
李潮阳,男
/*
HanLP 的继承结构:
AveragedPerceptron->LinearModel ,核心算法逻辑
PerceptronNameGenderClassifier->PerceptronClassifier 封装了 AveragedPerceptron,并且提供了特征清洗功能
8*/
运行结果
训练集准确率:P=83.80 R=83.12 F1=83.46
特征数量:5496
朴素感知机算法+简单特征模板 测试集准确率:P=82.14 R=82.26 F1=82.20
训练集准确率:P=92.43 R=81.38 F1=86.55
特征数量:5496
平均感知机算法+简单特征模板 测试集准确率:P=90.90 R=79.39 F1=84.75
训练集准确率:P=86.11 R=85.05 F1=85.58
特征数量:9089
朴素感知机算法+标准特征模板 测试集准确率:P=83.60 R=83.13 F1=83.36
训练集准确率:P=93.58 R=83.09 F1=88.03
特征数量:9089
平均感知机算法+标准特征模板 测试集准确率:P=90.89 R=80.18 F1=85.20
训练集准确率:P=100.00 R=99.99 F1=99.99
特征数量:146568
朴素感知机算法+复杂特征模板 测试集准确率:P=87.09 R=88.94 F1=88.00
训练集准确率:P=100.00 R=96.31 F1=98.12
特征数量:146568
平均感知机算法+复杂特征模板 测试集准确率:P=92.17 R=81.08 F1=86.27
注
- 简单特征:提取名字的2个汉字,去掉位置标记符
- 标注特征:提取名字的2个汉字
- 复杂特征:名1、名2、名12
- 如何保存模型:
model.save();
感知机用于序列标注
与前面的HMM其实原理差不多
HMM是用频率来计算转移矩阵,然后得到 $P(x,y)$ 的所有值,最后找到概率最大的路径。
这里用感知机来计算得到 $P(x,y) = P(x,y_t,y_{t-1})$,然后找到概率最大的路径
StructuredPerceptron->LinearModel
StructuredPerceptron#update 训练过程中更新参数
LinearModel#viterbiDecode
实用代码:分词模型的训练
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.model.perceptron.CWSTrainer;
import com.hankcs.hanlp.model.perceptron.PerceptronLexicalAnalyzer;
import com.hankcs.hanlp.model.perceptron.model.LinearModel;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.CWSEvaluator;
import org.junit.Test;
import java.io.IOException;
public class DemoPerceptronCWS {
static {
// 此 demo 不涉及词性
HanLP.Config.ShowTermNature = false;
}
public static String TRAIN_PATH = "src/data/test/icwb2-data/training/msr_training.utf8";
public static String TEST_PATH = "src/data/test/icwb2-data/testing/msr_test.utf8";
public static String GOLD_PATH = "src/data/test/icwb2-data/gold/msr_test_gold.utf8";
public static String MODEL_PATH = "src/data/test/msr_cws";
public static String OUTPUT_PATH = "src/data/test/msr_output.txt";
public static String TRAIN_WORDS = "src/data/test/icwb2-data/gold/msr_training_words.utf8";
public static void main(String[] args) throws IOException {
// 要点1: 模型训练
LinearModel model = new CWSTrainer().train(TRAIN_PATH, MODEL_PATH).getModel(); // 训练模型
Segment segment = new PerceptronLexicalAnalyzer(model).enableCustomDictionary(false);
// 要点2:模型评估
System.out.println(CWSEvaluator.evaluate(segment, TEST_PATH, OUTPUT_PATH, GOLD_PATH, TRAIN_WORDS)); // 标准化评测
// 要点3: 模型压缩和保存,入参分别是:模型路径,feature,压缩比例,是否导出为txt
model.save(MODEL_PATH, model.featureMap.entrySet(), 0.1, true);
// 要点4: 模型使用
System.out.println(segment.seg("商品和服务"));
}
@Test
public void loadAndEvaluate() throws IOException {
// 要点5: 加载已保存的模型,并使用
PerceptronLexicalAnalyzer segment = new PerceptronLexicalAnalyzer(MODEL_PATH);
segment.enableCustomDictionary(false);
System.out.println(segment.seg("与川普通电话"));
// 语料中没有 "川普",所以分词结果是 [与, 川, 普通, 电话]
// 要点6: 加入自定义词典
CustomDictionary.insert("川普", "nrf 1");
segment.enableCustomDictionaryForcing(true);
System.out.println(segment.seg("与川普通电话"));
// 看似结果是好的: [与, 川普, 通电话]
System.out.println(segment.seg("银川普通人与川普通电话讲四川普通话"));
// 但是出了新问题:[银, 川普, 通人, 与, 川普, 通电话, 讲, 四, 川普, 通话]
// 要点7: Online learning 可以解决此问题,训练次数是需要调参的
segment.enableCustomDictionary(false);
// ???这里最好改成while循环
for (int i = 0; i < 3; ++i)
segment.learn("人 与 川普 通电话");
System.out.println(segment.seg("银川普通人与川普通电话讲四川普通话"));
// 结果完美! [银川, 普通人, 与, 川普, 通电话, 讲, 四川, 普通话]
}
}
注意几个要点
- 模型的训练、压缩、保存
- 模型的加载、使用、评估
- 模型的调整:自定义词典、在线学习
- 感知机模型的准召率全面超过HMM,OOV的识别也有极大提高
附加1 :模型压缩和保存
// 关于模型压缩
LinearModel model = new LinearModel("src/model/cws.bin") // 读入模型
model.save("src/model/compress_cws.bin", 0.5, false)
// 参数分别是:新模型路径,压缩比例,是否同时保存一个 txt 供 debug
// 压缩到 0.5 其实准召下降不大
// 如果再次压缩,模型文件又会减半
附加2:segment和LinearModel的互相转化
// LinearModel 转 segment
PerceptronLexicalAnalyzer segment = new PerceptronLexicalAnalyzer(model);
// PerceptronLexicalAnalyzer segment = (PerceptronLexicalAnalyzer) new PerceptronLexicalAnalyzer(model).enableCustomDictionary(false) ;
// ???这好像是个缺陷,用的父类方法 return this
// segment 转 LinearModel
LinearModel newLinearModel=segment.getPerceptronSegmenter().getModel();
附加3:增量训练并保存模型
//加载模型
PerceptronLexicalAnalyzer segment = new PerceptronLexicalAnalyzer("src/test/resources/model/compress_cws.bin");
segment.enableCustomDictionary(false);
//增量训练
String words = "社区卫生服务站,社区卫生服务中心,妇幼保健院,妇幼保健站";
for (String word : words.split(",")) {
String sentence1 = "我去 " + word + " 逛街";
String sentence = "我去" + word + "逛街";
System.out.println("training: " + sentence1 + " for word " + word);
int i = 0;
while (!segment.seg(sentence).contains(word)) {
segment.learn(sentence1);
i++;
//最多训练5次,不成也就不成了
if (i > 5) {
break;
}
}
System.out.println("train result: " + sentence + " -> " + segment.seg(sentence));
}
LinearModel newLinearModel = segment.getPerceptronSegmenter().getModel();
newLinearModel.save("src/test/resources/model/online_compress_cws.bin", newLinearModel.featureMap.entrySet(), 0.0, false);
条件随机场
原理不多说
有C++版本
# macOS
brew install crf++
# Linux
# 略
语料格式转化
// 原始的语料:
商品 和 服务
商品 和服 物美价廉
服务 和 货币
// 需要转化成标注格式:
商 B
品 E
和 S
服 B
务 E
商 B
品 E
和 B
服 E
物 B
美 M
价 M
廉 E
服 B
务 E
和 S
货 B
币 E
(特征可以有多列,这里只做了一列)
使用 HanLP
import com.hankcs.hanlp.corpus.io.IOUtil;
import com.hankcs.hanlp.model.crf.CRFSegmenter;
import org.junit.Test;
import java.io.IOException;
public class CrfppTrainHanLPLoad {
// 语料
public static final String TXT_CORPUS_PATH = "src/data/test/my_cws_corpus.txt";
// 转化为标注格式
public static final String TSV_CORPUS_PATH = TXT_CORPUS_PATH + ".tsv";
// 特征模版
public static final String TEMPLATE_PATH = "src/data/test/cws-template.txt";
// 模型地址
public static final String CRF_MODEL_PATH = "src/data/test/crf-cws-model"; // HanLp 不兼容这种格式
public static final String CRF_MODEL_TXT_PATH = "src/data/test/crf-cws-model.txt";
// 把原始语料转化为 CRF 所需格式
@Test
public void makeModel() throws IOException {
CRFSegmenter segmenter = new CRFSegmenter(null); // 创建空白分词器
// 把原始语料转化为 CRF 需要的标注格式,并保存下来
segmenter.convertCorpus(TXT_CORPUS_PATH, TSV_CORPUS_PATH); // 执行转换
// 导出特征模版
segmenter.dumpTemplate(TEMPLATE_PATH);
System.out.printf("语料已转换为 %s ,特征模板已导出为 %s\n", TSV_CORPUS_PATH, TEMPLATE_PATH);
System.out.printf("请安装CRF++后执行 crf_learn -f 3 -c 4.0 %s %s %s -t\n", TEMPLATE_PATH, TSV_CORPUS_PATH, CRF_MODEL_PATH);
System.out.printf("或者执行移植版 java -cp hanlp.jar com.hankcs.hanlp.model.crf.crfpp.crf_learn -f 3 -c 4.0 %s %s %s -t\n", TEMPLATE_PATH, TSV_CORPUS_PATH, CRF_MODEL_PATH);
}
// 训练模型,并存下来
@Test
public void trainModel() throws IOException {
System.out.println("训练模型");
CRFSegmenter segmenter = new CRFSegmenter(null);
// 训练模型,并把模型存到 CRF_MODEL_PATH
// 训练集语料太大了,作为测试,用个只有3条数据的跑跑看
// String corpus = "data/test/icwb2-data/training/msr_training.utf8";
String corpus = TXT_CORPUS_PATH;
segmenter.train(corpus, CRF_MODEL_PATH);
}
// 加载并使用模型
@Test
public void useModel() throws IOException {
if (IOUtil.isFileExisted(CRF_MODEL_TXT_PATH)) {
// 加载模型,会自动创建一个 .txt.bin 文件,下次加载模型会快很多
CRFSegmenter segmenter = new CRFSegmenter(CRF_MODEL_TXT_PATH);
System.out.println(segmenter.segment("商品和服务"));
} else {
System.out.println("模型文件不存在");
}
}
}
序列标注模型应用到词性标注
训练集
我国/n 将/d 实行/v 播音员/n 主持人/n 持证/v 上岗/v 制度/n
李铁映/nr 等/u 向/p 第一/m 批/q 获得/v 资格/n 证书/n 的/u 代表/n 颁证/v
这里每个词变成一个基本单元了。作为对比,前面的分词算法是每个字一个基本单元,标签是 BMES 共4个;这里是每个词一个基本单元,标签有几十个。
除此之外的模型原理一样。
训练和使用词性标注模型
HanLP 实现了 HMM、二阶HMM、感知机、CRF 的词性标注 这里。
看起来CRF是最准的,感知机是速度较快的里面最准的,下面就只摘抄这两个了。
/*
CRFPOSTagger->POSTagger
PerceptronPOSTagger->POSTagger
HMMPOSTagger->POSTagger
*/
import com.hankcs.hanlp.model.crf.CRFPOSTagger;
import com.hankcs.hanlp.model.perceptron.POSTrainer;
import com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger;
import com.hankcs.hanlp.model.perceptron.PerceptronTrainer;
import com.hankcs.hanlp.model.perceptron.model.LinearModel;
import org.junit.Test;
import java.io.IOException;
import java.util.Arrays;
public class EvaluatePOS {
// data:http://file.hankcs.com/corpus/pku98.zip
public static String PKU199801_TRAIN = "src/data/test/pku98/199801-train.txt";
public static String PKU199801_TEST = "src/data/test/pku98/199801-test.txt";
public static String POS_MODEL = "/pos.bin";
public static String NER_MODEL = "/ner.bin";
public static String perceptronModelPath = "src/data/model/perceptronModel_pos.bin";
@Test
public void trainPerceptronPOSTagger() throws IOException {
// 训练并保存模型
PerceptronTrainer trainer = new POSTrainer();
LinearModel model = trainer.train(PKU199801_TRAIN, perceptronModelPath).getModel();
PerceptronPOSTagger postTagger = new PerceptronPOSTagger(model);
//模型使用
postTagger.tag("多吃苹果有益健康");
}
@Test
public void usePerceptronPOSTagger() throws IOException {
// 模型的加载和使用
PerceptronPOSTagger postTagger = new PerceptronPOSTagger(perceptronModelPath);
//模型使用
String[] sent = {"多吃", "苹果", "有益", "健康"};
System.out.println(Arrays.toString(postTagger.tag(sent)));
}
//CRF 模型的训练、加载
public static String CRFModelPath = "data/test/pku98/pos.bin";
@Test
public void trainCRFPOSTagger() throws IOException {
CRFPOSTagger tagger = new CRFPOSTagger(null);
tagger.train(PKU199801_TRAIN, CRFModelPath);
// 或者加载CRF++训练得到的pos.bin.txt
// return new CRFPOSTagger(modelPath + ".txt");
CRFPOSTagger crfposTagger = new CRFPOSTagger(CRFModelPath);
}
@Test
public void useCRFPOSTagger() throws IOException {
// 加载训练好的模型,并使用
CRFPOSTagger crfposTagger = new CRFPOSTagger(CRFModelPath);
System.out.println(Arrays.toString(crfposTagger.tag("多吃", "苹果", "有益", "健康")));
}
}
上面展示的是仅仅做词性标注这一步。实际使用时,我们希望先分词然后做标注。也就是说,分词算法和词性标注算法连起来用。如下:
@Test
public void usePerceptron() throws IOException {
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(
// 分词算法
new PerceptronSegmenter("src/data/model/perceptron/large/cws.bin"),
// 词性标注算法
new PerceptronPOSTagger("src/data/model/perceptron/pku1998/pos.bin"));
System.out.println(analyzer.analyze("他的希望是希望上学"));
}
他/r 的/u 希望/vn 是/v 希望/n 上学/v
上面是 perceptron 分词算法 + perceptron 词性标注算法连用,其实也可以 perceptron 分词 + CRF 词性标注连用,随意的。
模型的调整
用户自定义词典,代码
public class CustomPOS {
public static void main(String[] args) throws IOException {
HanLP.Config.PerceptronCWSModelPath = "src/data/model/perceptron/large/cws.bin";
HanLP.Config.PerceptronPOSModelPath = "src/data/model/perceptron/pku1998/pos.bin";
HanLP.Config.PerceptronNERModelPath = "src/data/model/perceptron/pku1998/ner.bin";
CustomDictionary.insert("苹果", "手机品牌 1");
CustomDictionary.insert("iPhone X", "手机型号 1");
PerceptronLexicalAnalyzer analyzer = new PerceptronLexicalAnalyzer();
analyzer.enableCustomDictionaryForcing(true);
System.out.println(analyzer.analyze("你们苹果iPhone X保修吗?"));
System.out.println(analyzer.analyze("苹果有益健康"));
}
}
你们/r 苹果/手机品牌 iPhone X/手机型号 保修/v 吗/y ?/w
苹果/手机品牌 有益/a 健康/a
第二条出现了问题。
命名实体识别
我们完成分词算法、词性标注后,句子已经能很好的结构化,但还有一些多词组成的专有名词难以解决。
- 命名实体根据领域不同,有很大不同,例如电商领域的商品名词,医疗领域的疾病名
- 数量无穷,且源源不断的产生,例如恒星名、蛋白质名
- 构词灵活,例如中国工商银行、工商银行、工行。甚至有嵌套,例如 “联合国销毁伊拉克大规模杀伤性武器特别委员会”,这个命名实体就嵌套了一个地名和一个机构名
- 类别模糊。某些地名本身也是机构,例如“国家博物馆”
语料格式规范
[伊拉克/ns 外交部/n]/nt 发言人/n 18日/t 宣布/v ,/w [伊拉克/ns 驻/v 约旦/ns 大使馆/n]/nt 公使/n 希克迈特·赫朱/nr 夫妇/n 及/c 5/m 名/q 伊拉克/ns 公民/n 和/c 1/m 名/q 埃及/ns 人/n 17日/t 晚/Tg 在/p 约旦/ns 首都/n 安曼/ns 遇刺/v 身亡/v 。/w
方案
- 方案1。对于规则性强的命名实体,例如网址、email、ISBN、商品编号。可以用正则,未能正则的片段交给统计模型
- 方案2。对于较短的命名实体,可以用分词算法确定边界,然后用词性标注算法确定类别。往往足以解决问题。
- 方案3。对于复合词命名识别的任务,可以转化为序列标注问题,转为“BMES”标签,对于命名实体之外的词,标为 “O” 标签
下面把每个做法写下来
方案1:基于规则的命名识别
任务:音译外国人名识别
- 先分词
- 音译对应的汉字,往往就那么几十上百个,做成词典
- 从左到右看每个分词是否命中词典,如果命中,继续吸收右边的词(如果右边在词典中)
- 改进:词典中的汉字,可能是常用词,这会造成大量误召回,所以词典改成双词。
Segment segment = HanLP.newSegment().enableTranslatedNameRecognize(true);
List<Term> termList = segment.seg(sentence);
中英文数字识别,HanLP 也是用规则向右吸收法,有现成的了
public static void main(String[] args)
{
Segment segment = new ViterbiSegment();
System.out.println(segment.seg("牛奶三〇〇克壹佰块"));
System.out.println(segment.seg("牛奶300克100块"));
System.out.println(segment.seg("牛奶300g100rmb"));
// 演示自定义字符类型
String text = "牛奶300~400g/100rmb";
System.out.println(segment.seg(text));
CharType.type['~'] = CharType.CT_NUM;
System.out.println(segment.seg(text));
}
[牛奶/n, 三〇〇/m, 克/q, 壹佰/m, 块/q]
[牛奶/n, 300/m, 克/q, 100/m, 块/q]
[牛奶/n, 300/m, g/nx, 100/m, rmb/nx]
[牛奶/n, 300/m, ~/nx, 400/m, g/nx, //w, 100/m, rmb/nx]
[牛奶/n, 300~400/m, g/nx, //w, 100/m, rmb/nx]
方案2:基于成叠HMM的角色标注
人名识别
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.corpus.dictionary.EasyDictionary;
import com.hankcs.hanlp.corpus.dictionary.NRDictionaryMaker;
import com.hankcs.hanlp.corpus.document.sentence.Sentence;
import com.hankcs.hanlp.seg.Dijkstra.DijkstraSegment;
import com.hankcs.hanlp.seg.Segment;
import org.junit.Test;
// HanLP.Config.enableDebug();
Segment segment = new DijkstraSegment();
System.out.println(segment.seg("李天一的爸爸是李刚。"));
[李/nr, 天一/j, 的/uj, 爸爸/n, 是/v, 李刚/nr, 。/w]
“李天一” 这个命中没有被默认分词器识别出来
从语料中训练,并增量训练,并保存:
HanLP.Config.enableDebug();
String corpus="src/data/test/pku98/199801.txt";
String model ="src/test/data/nr";
EasyDictionary dictionary = EasyDictionary.create(HanLP.Config.CoreDictionaryPath); // 核心词典
NRDictionaryMaker maker = new NRDictionaryMaker(dictionary); // 训练模块
maker.train(corpus); // 在语料库上训练
maker.saveTxtTo(model); // 输出HMM到txt
// 增量训练
maker.learn(Sentence.create("李天一/nr 开车/v 撞人/v 。/w")); // 学习一个句子
maker.learn(Sentence.create("门卫/n 也/d 拦/v 不住/d 李天一/nr 。/w")); // 学习一个句子
(???如何加载已训练好的模型,并做增量训练?还没调研出来)
载入并使用训练好的模型:
String model ="src/test/data/nr";
HanLP.Config.PersonDictionaryPath = model + ".txt"; // data/test/nr.txt
HanLP.Config.PersonDictionaryTrPath = model + ".tr.txt"; // data/test/nr.tr.txt
Segment segment = new DijkstraSegment(); // 该分词器便于调试
System.out.println(segment.seg("把下一位被告李天一带上来!"));
[把/p, 下/f, 一/m, 位/q, 被告/n, 李天一/nr, 带/v, 上/f, 来/v, !/w]
挺成功
模型原理:(verbose 模式会输出中间结果)
- 用通用分词器分词
- 用通用标注器标注词性
- 用实体标注器标注人名。(重点)
原理(看 verbose 信息,能看出原理)。
对于分词后的结果,标注名字置词、后置词、名字本身各个结构做标志,以此为训练集合和识别目标。
训练一个序列识别器。去识别这套标记。
地名识别
原理一摸一样,不过用到的基础词性和标注tag名不一样,
方案3:基于序列标注的命名实体识别
此方案在做分词后,采用 BMES 标识做序列标注。
基于 HMM 的 NER
- 训练 HMM NER 模型,然后做增量训练
// 用 pku 语料训练一个 NER 模型
String corpus = "src/data/test/pku98/199801.txt";
HMMNERecognizer recognizer = new HMMNERecognizer();
recognizer.train(corpus);
AbstractLexicalAnalyzer analyzer1 = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), recognizer);
System.out.println(analyzer1.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"));
// 增量训练
String[] wordArray = {"华北", "电力", "公司"}; // 构造单词序列
String[] posArray = {"ns", "n", "n"}; // 构造词性序列
String[] nerTagArray = recognizer.recognize(wordArray, posArray); // 序列标注
for (int i = 0; i < wordArray.length; i++)
System.out.printf("%s\t%s\t%s\t\n", wordArray[i], posArray[i], nerTagArray[i]);
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), recognizer);
analyzer.enableCustomDictionary(false);
System.out.println(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"));
基于感知机的NER
String corpus = "src/data/test/pku98/199801.txt";
String ner_model = "/ner.bin";
PerceptronTrainer nerTrainer = new NERTrainer();
NERecognizer recognizer = new PerceptronNERecognizer(nerTrainer.train(corpus, corpus, ner_model, 0, 50, 8).getModel());
//在线学习1
String[] wordArray = {"华北", "电力", "公司"}; // 构造单词序列
String[] posArray = {"ns", "n", "n"}; // 构造词性序列
String[] nerTagArray = recognizer.recognize(wordArray, posArray); // 序列标注
for (int i = 0; i < wordArray.length; i++)
System.out.printf("%s\t%s\t%s\t\n", wordArray[i], posArray[i], nerTagArray[i]);
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), recognizer);
analyzer.enableCustomDictionary(false);
System.out.println(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"));
// 在线学习2
PerceptronLexicalAnalyzer analyzer2 = new PerceptronLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), (PerceptronNERecognizer) recognizer);
Sentence sentence = Sentence.create("与/c 特朗普/nr 通/v 电话/n 讨论/v [太空/s 探索/vn 技术/n 公司/n]/nt");
while (!analyzer.analyze(sentence.text()).equals(sentence))
analyzer2.learn(sentence);
System.out.println(analyzer.analyze("与特朗普通电话讨论太空探索技术公司"));
基于CRF的 NER
String corpus = "src/data/test/pku98/199801.txt";
String ner_model = "src/data/ner.bin";
PerceptronTrainer nerTrainer = new NERTrainer();
NERecognizer recognizer = new PerceptronNERecognizer(nerTrainer.train(corpus, corpus, ner_model, 0, 50, 8).getModel());
//在线学习1
String[] wordArray = {"华北", "电力", "公司"}; // 构造单词序列
String[] posArray = {"ns", "n", "n"}; // 构造词性序列
String[] nerTagArray = recognizer.recognize(wordArray, posArray); // 序列标注
for (int i = 0; i < wordArray.length; i++)
System.out.printf("%s\t%s\t%s\t\n", wordArray[i], posArray[i], nerTagArray[i]);
AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), recognizer);
analyzer.enableCustomDictionary(false);
System.out.println(analyzer.analyze("华北电力公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"));
// 在线学习2
PerceptronLexicalAnalyzer analyzer2 = new PerceptronLexicalAnalyzer(new PerceptronSegmenter(), new PerceptronPOSTagger(), (PerceptronNERecognizer) recognizer);//①
Sentence sentence = Sentence.create("与/c 特朗普/nr 通/v 电话/n 讨论/v [太空/s 探索/vn 技术/n 公司/n]/nt");
while (!analyzer.analyze(sentence.text()).equals(sentence))//③
analyzer2.learn(sentence);
System.out.println(analyzer.analyze("与特朗普通电话讨论太空探索技术公司"));
自定义NER
NERTrainer trainer = new NERTrainer();
trainer.tagSet.nerLabels.clear(); // 不识别nr、ns、nt
trainer.tagSet.nerLabels.add("np"); // 目标是识别np
PerceptronNERecognizer recognizer = new PerceptronNERecognizer(trainer.train(PLANE_CORPUS, PLANE_MODEL).getModel());
// 1. 在NER预测前,需要一个分词器,最好训练自同源语料库
LinearModel cwsModel = new CWSTrainer().train(PLANE_CORPUS, PLANE_MODEL.replace("model.bin", "cws.bin")).getModel();
PerceptronSegmenter segmenter = new PerceptronSegmenter(cwsModel);
PerceptronLexicalAnalyzer analyzer = new PerceptronLexicalAnalyzer(segmenter, new PerceptronPOSTagger(), recognizer);
analyzer.enableTranslatedNameRecognize(false).enableCustomDictionary(false);
System.out.println(analyzer.analyze("米高扬设计米格-17PF:米格-17PF型战斗机比米格-17P性能更好。"));
System.out.println(analyzer.analyze("米格-阿帕奇-666S横空出世。")); }
HanLP的其它功能
您的支持将鼓励我继续创作!
