【Transformer】Bert和GPT
🗓 2022年10月29日 📁 文章归类: 0x23_深度学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2022/10/29/transformer.html
为什么
RNN的问题:
- 不能并行计算
- 引入 Self-Attention 机制
word2vec 的问题
- 一个词在不同的句子中的语义不一样
- 预训练好的向量永久不变
可用于什么任务?
- 文本语义关系。2段文本,预测3种关系:蕴含entailment(M可以推导N)、矛盾 contradiction、中立neutral
- 文本匹配。2段文本,预测是否等价
- 推理。二分类任务,正样本包含正确的answer,负样本包含不正确的answer
- 文本分类(本文重点)
- 文本相似度。2个文本之间的相似度,分数1到5
- 抽取式阅读理解。下面有例子
- NER
- 带选择题的阅读理解。1个陈述句子和4个备选句子,判断哪个最有连续性
Transformer
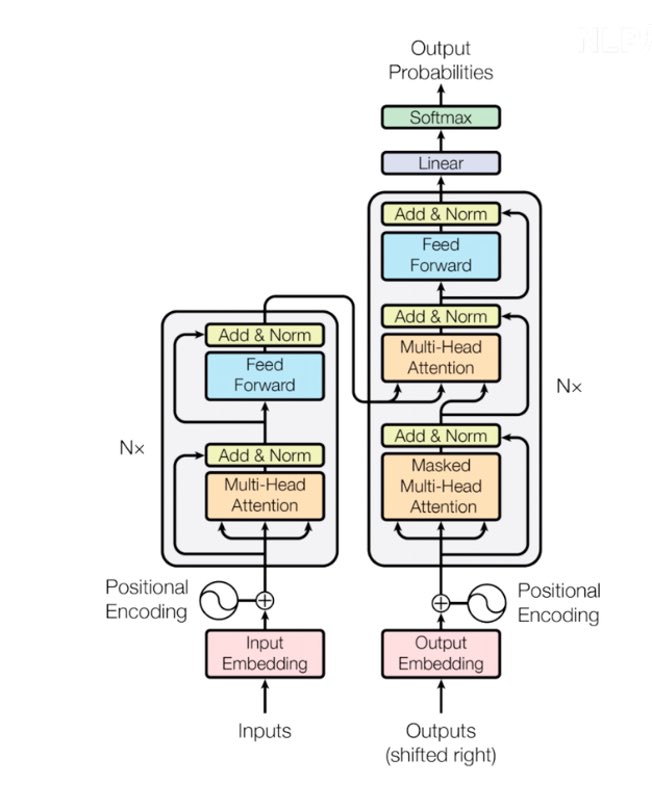
网络结构
tokenize
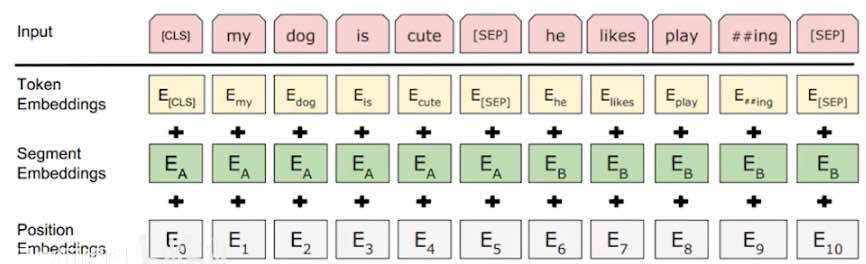
关于token:
- 先用tokenization 工具分词,例如playing 变成 play+ing
- 如果是中文,不用分词,每个汉字隔开(而不是按词分割)
[SEP]:用来分割两句话,[CLS]:用来分类两句话是否有上下文关系- 如果长度不足,用
[PAD]补充。
关于 segment:用来分割 关于Position:如果没有position,就缺失了序列(或者位置)信息,所以需要position,把位置编码学出来。(细节:用正弦函数编码,而不是one-hot)
位置编码
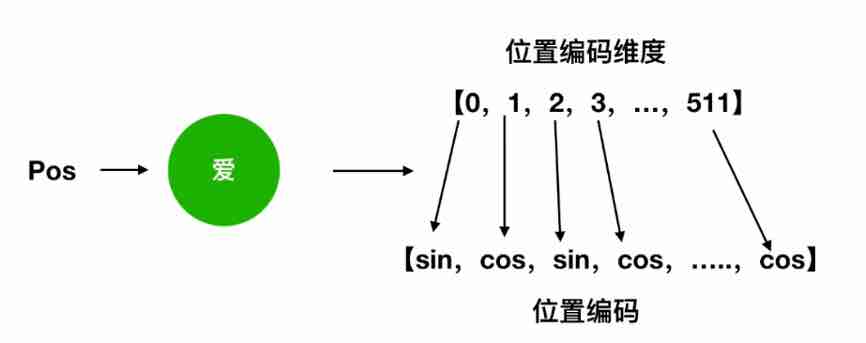
如果不做位置编码,模型实际上就不涉及到位置信息,也就会导致单词任意互换位置不影响结果,这不符合现实。
所以加上位置编码。 bert 一般用 正弦/余弦做位置编码
维度说明
batch_size = 8
seq_len = 128 # 每个输入,最多 128 个词。
embedding_size = 768 # 每个向量有 768 个维度
# 词对应的 embedding 向量维度:
(batch_size, seq_len, embedding_size)
# 位置编码:
# token_type_table
# [CLS] hello world ! [SEP] good morning . [SEP]
# 0 0 0 0 0 1 1 1 1
# 0 代表前一句话,1代表后一句话
# 如果输入值是一句话,那么全0
# [CLS] hello world ! [SEP]
# 0 0 0 0 0
(2, 768)
# 补 0 机制:mask
# 如果长度不满 128 ,那么补 0: 1)词 embedding 补 0,用 0 号单词补。 2)token 直接补 0
# 然后建立一个 mask 向量,例如:
# 假设某次输入的句子长度为 80,那么
mask = [1] * 80 + [0] * (128 - 80)
# position_embedding
(128, 768)
# 最终:
# TPU计算二维矩阵效率高,因此 resize 成 1024*768 的矩阵
Self-attention
Self-attention 是做什么的?
- The animal did not cross the street because
itwas too tired. - The animal did not cross the street because
itwas too narrow.
根据语境,“判断”哪个词对 it 更重要。
如果计算机能够学到每个词对其它词的影响权重,也就是把上下文语境融入到单个词,那么计算机可以更好的理解语言。
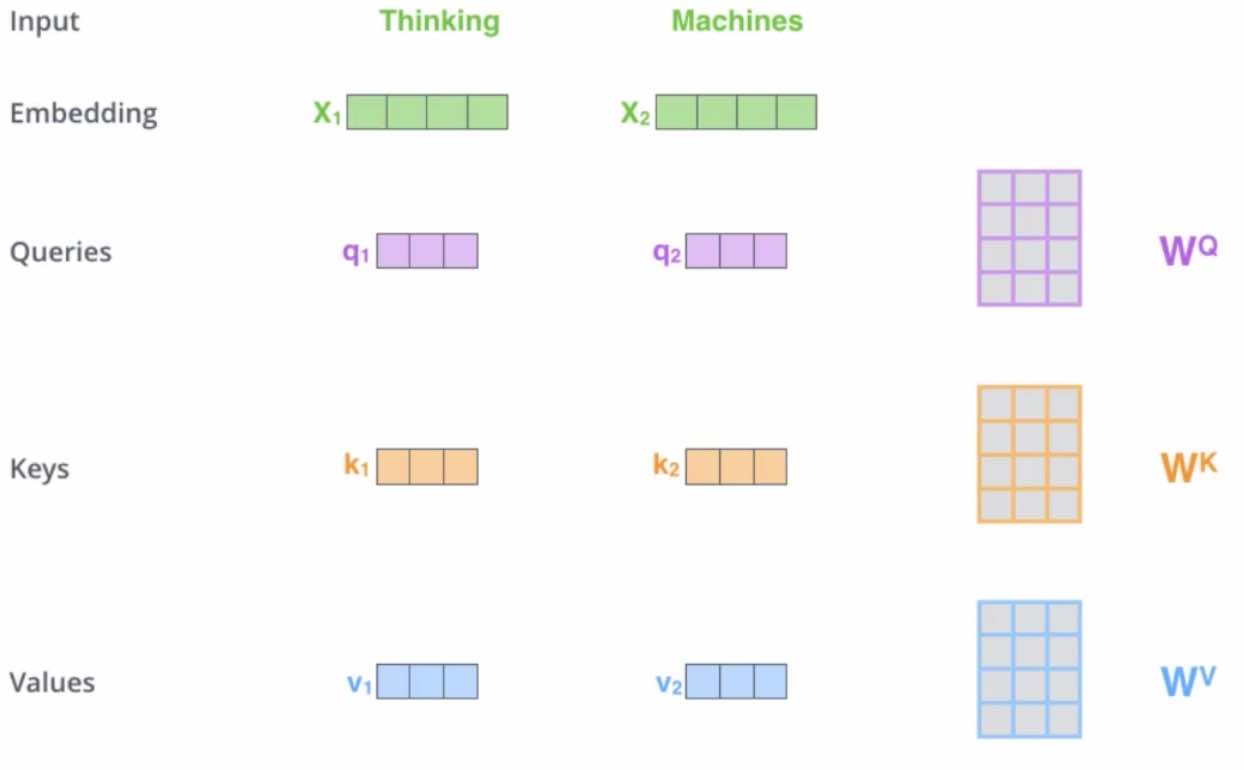
- X:一个词对应的embeding。展示两个单词,所以两行,每行对应一个单词。图中4列表示每个单词对应一个长度为4的特征向量。
- Q(query):要去查询的。第i行表示,第i单词对别的单词的关系。
- 某个单词的“影响力”也是一种知识,它可以用向量表达,Q有3列就是指用了3维向量表达这种知识
- K(key):等着被查的。第i行表示,第i个单词被别的单词的影响。
- V:实际的特征信息。第i行表示,单词i的特征向量。
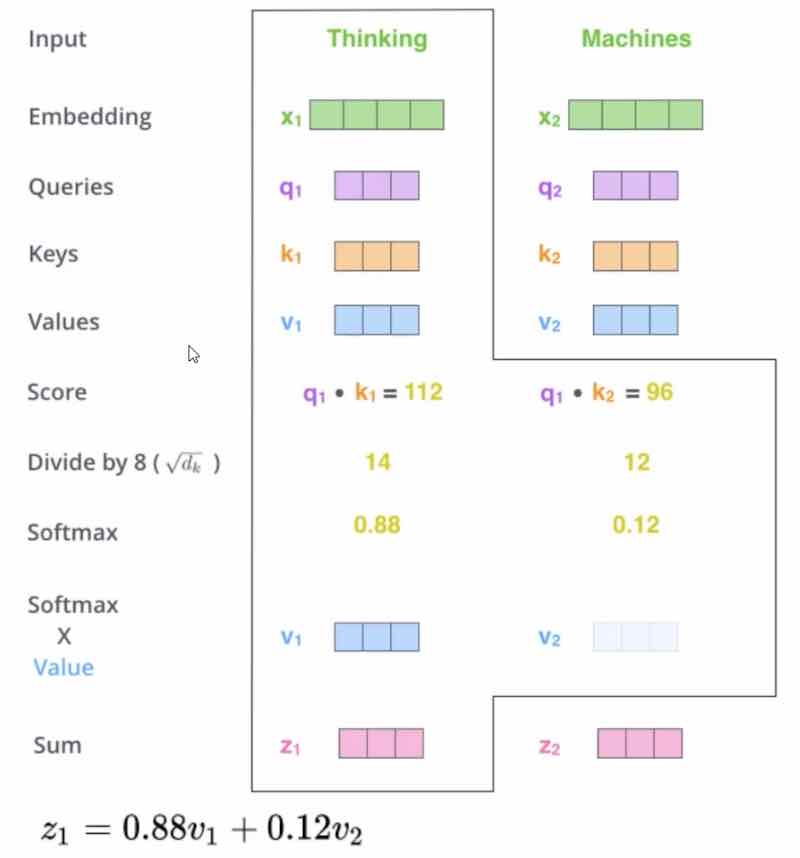
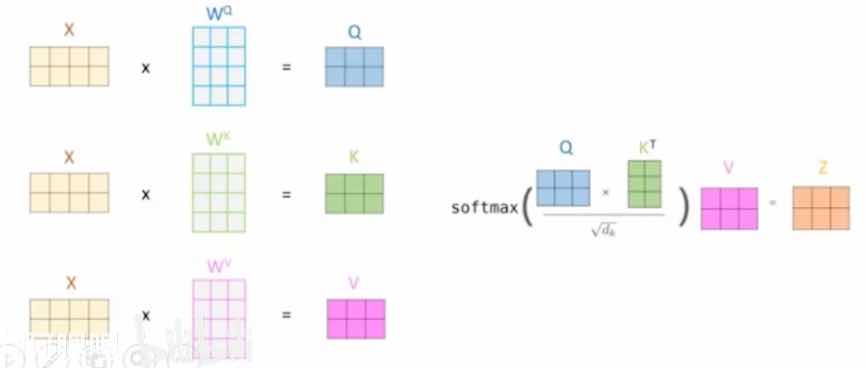
- $q_1*k_1$ 乘法是内积。
- 为什么是内积?内积代表了相关程度:正交时为0,平行时最大。
- 内积大的就更重要,内积小的就不重要。(和相关系数类似)
- softmax,把数字变成比例
- 图里面两个单词,softmax的输入是2x2矩阵,计算时其实对每一行做softmax,做了2次
- $d_k$,
总结下来,就是这样
$\mathrm{Attention}(Q,K,V) = \mathrm{softmax}(\dfrac{QK^T}{\sqrt{d_k}})V$
Multi-head 机制
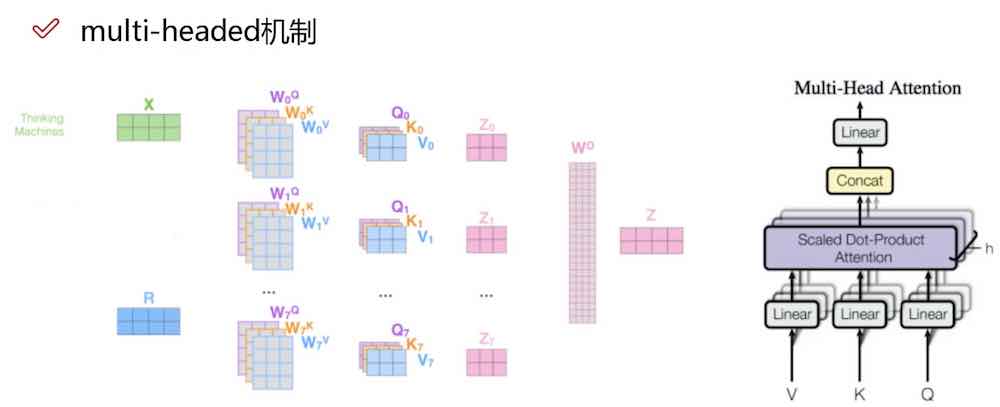
为什么?因为只做一组 self-attention,不足以表示所有维度的“关注”,因此多做几组,就是 multi-head
- 多组Q/K/V,生成多成的下一层。目的是生成多组不同的特征表达,类似 CNN 的一次卷积操作。
- 一般8组够了
- 然后把所有特征拼接在一起(concat)
- 然后通过一层全连接层降低维度。
堆叠
self-attention 不是只做一次,而是多次串起来
Layer normalization
为什么不用BN(batch normalization)呢?
BN是针对R个样本,每个样本同一个特征做的处理。如图。
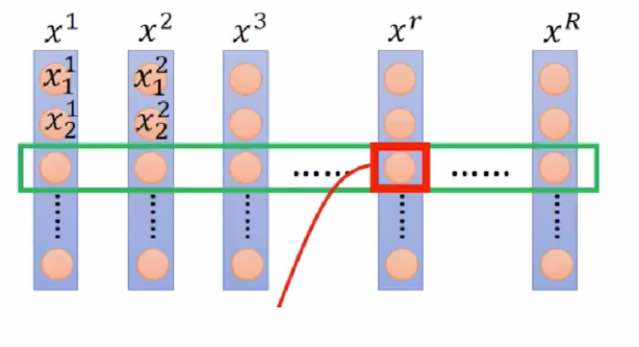
BN的优点如下:
BN的缺点:BN在NLP任务中,效果往往不好,因为:
- Batch_size较小的时候,效果很差。
- NLP的输入句子往往长度不一样,稍长的句子长出来的部分就没办法很好的计算均值方差。
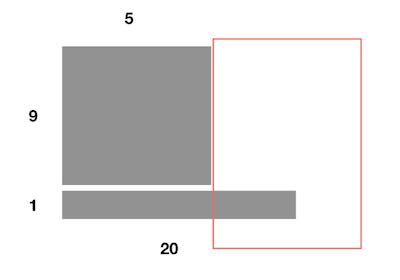
所以使用 Layer normalization,让每个特征向量变成 $N(0,1)$
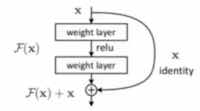
残差机制
类似 RES,防止梯度消失。
特别的是,bert 的残差机制是加起来,而不是拼接。
ChatGPT
Bert vs GPT
共同点:GPT(Generative Pre-trained Transformer)和 BERT(Bidirectional Encoder Representations from Transformers) 都是基于 Transformer 的预训练语言模型
差别:
| 方面 | Bert | GPT |
|---|---|---|
| 模型结构 | Encoder-only | Decoder-only |
| 训练目标 | 去噪自编码(Denoising Autoencoder),主要 MLM,常配合 NSP/替代任务 | 自回归(Autoregressive),Next Token Prediction |
| 注意力方向 | 双向注意力(同时看左右上下文),更擅长“理解/表征” | 因果/单向注意力(只能看左边上下文),更适合“续写/生成” |
| 核心能力倾向 | 强在理解(分类、实体识别、检索排序、语义匹配等判别式任务) | 强在生成(对话、写作、代码、摘要、翻译等生成式任务) |
| 下游使用方式 | 通常在 [CLS] 向量等表征上接一个分类/标注头进行微调 | 常用“提示词/指令 + 解码生成”,也可微调做特定生成任务 |
| 输出形式 | 输出每个 token 的上下文化向量表示,再用于判别或填空 | 输出一段可继续生成的文本序列 |
| 典型应用举例 | 情感分类、意图识别、命名实体识别、搜索/匹配 | 聊天机器人、内容创作、代码助手、长文总结 |
GPT-1 到 ChatGPT 的演化
- GPT1: 预训练——微调
- GPT2: 引入 prompt,拥有 ZeroShot learning 能力
- GPT3: 有 FewShot learning 能力
- InstructGPT
ChatGPT
- 基于大规模预训练语言模型(GPT-3,一般也称作 base 模型)进一步训练
- 通过在人工标注和反馈的数据上进行指令对齐,从而有更好的对话能力(ChatGPT,一般也称为 chat 模型)
阶段一:SFT(supervised fine-tuning)
- 人工收集、标注训练样本,有监督地微调 GPT-3.5 模型
- 问题来源:1)标注员 2)ChatGPT的用户
- 答案(demonstration)有标注员填写,标准:有用、无害、真实
- 此阶段 1.3万+ 样本量
- 通过有监督微调,赋予 GPT 模型能理解人类的复杂指令
- Plain:标注人员构思问题和答案
- Few-shot
- User-based:根据用户提交的问题改写
- API prompt:从 OpenAI的 API调用种抽取的 Prompt
阶段二:RM(Reward Model)
- 人工对模型输出候选结果进行排序,训练奖励模型
- 同一个问题,模型输出多个回答,标注员对其排序
- RLHF(Reinforcement Learning from Human Feedback)
- 奖励模型以人类的视角来衡量模型的表现
阶段三:PPO(Proximal Policy Optimization)
- 通过 RM,利用强化学习 PPO 算法对模型进一步训练
- 重复阶段二和阶段三,从而使得模型不断增强

其它GPT模型
有哪些
- 参考 OpenAI 论文复现的开源模型 OPT(Open Pre-trained Transformer Language Models)
- Meta 开源的 LLaMA
LLaMA 做了哪些改进
- 层归一化,使用了 RMSNorm $\bar a_i = \dfrac{a_i}{RMS(a)}$,其中 $RMS(a) = \sqrt{1/n \sum\limits_{i=1}^n a_i^2}$
- SwiGLU 激活函数
- 稀疏注意力机制的组合

- Multi Query Attention,多头共享 K、V 组合,各自保留自己的 Q. 如果采用此机制,在 SFT 阶段只需要 5% 数据即可达到原来的效果。
Decode 部分
Attention 计算不同(待补充)
Mask机制
在预测的时候,可以使用前面的词,但不能使用后面的词(不然就是作弊了),所以把后面的单词Mask掉
损失函数
cross-entropy
Bert:预训练
MLM(Mask Language Model 策略)
- 15% mask,其中:
- 10% 随机替换
- 10%不替换
- 80%替换为
[mask]
训练任务 训练时,两个任务同时进行:
- 预测被MLM掩盖的字
- 预测两句话是否有顺序关系(Next Sentence Prediction, NSP)
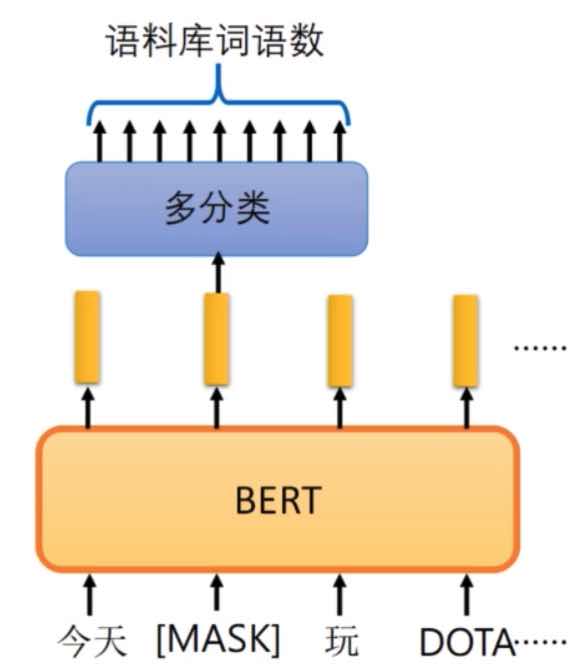
(上图是训练任务1:预测被掩盖的字,注意:beart 汉字是以字为单位而不是词,图里面是为了看着好)
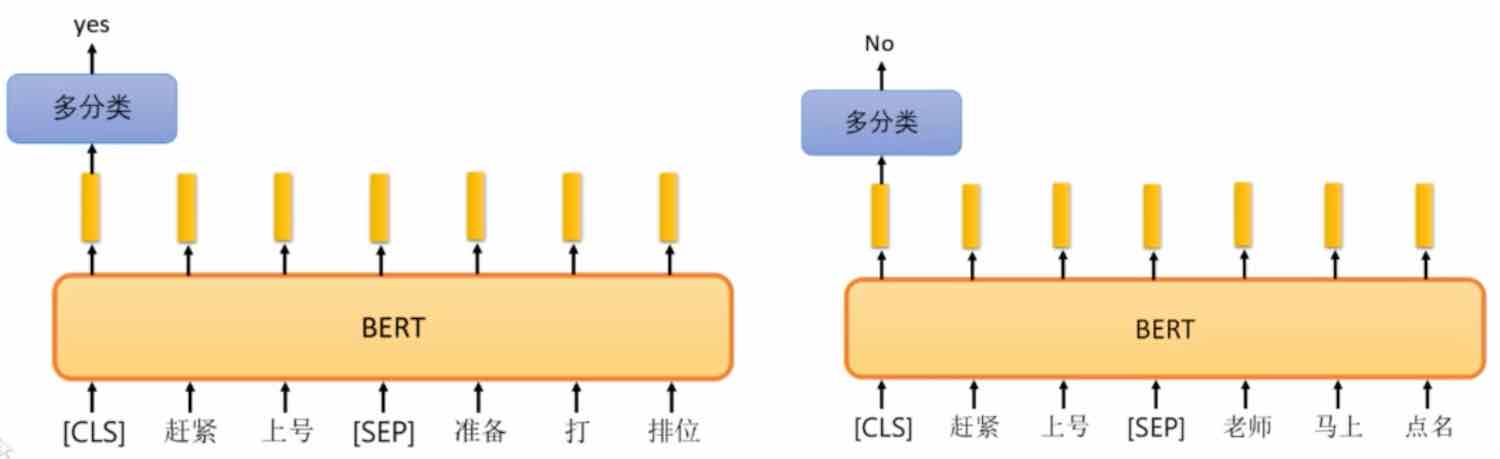
(训练任务2)
辅助训练任务:NSP(Next Sentence Prediction)、SOP(Sentence Order Prediction)
使用
End-to-end形式:
不是先训练embedding,然后训练分类任务,而是放一起训练。
案例1:阅读理解

模型的输出是:答案在文章中的起止位置 (start_idx,end_idx)
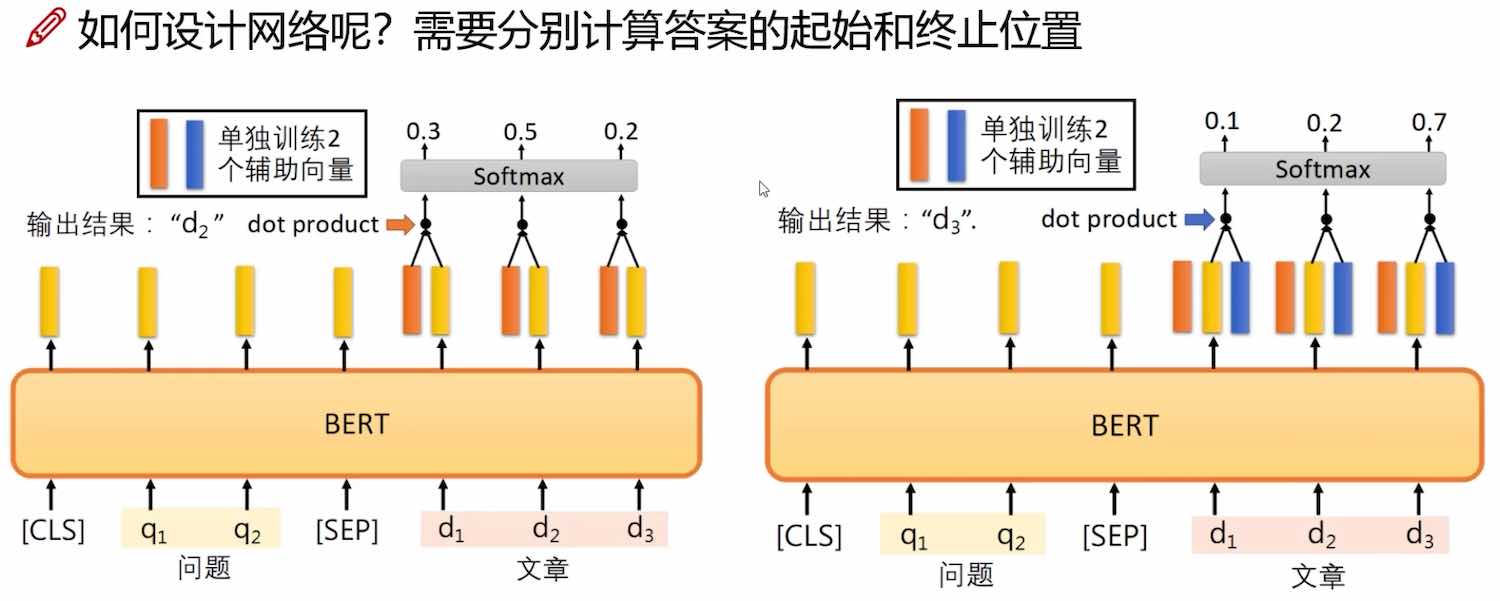
- 分别单独训练两个辅助向量,分别用来辅助预测 start_idx, end_idx
- 辅助向量与bert输出做内积
- 然后做 softmax,看最大值对应哪一个位置。图中案例分别是 start_idx=2, end_idx=3,所以模型输出是 (2, 3)
参考资料
- Attention Is All You Need:http://arxiv.org/abs/1706.03762
- 一行代码实现 Bert: https://github.com/guofei9987/pybert
- https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
- https://github.com/huggingface/transformers
您的支持将鼓励我继续创作!
