Diffusion Model
🗓 2023年12月02日 📁 文章归类: torch
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2023/12/02/diffusion.html
是一种文字生成图片的模型,相似的模型 DDPM、EVA、DALL-E、Imagen
- Diffusion 是一种从噪音生成图片的模型
- Stable Diffusion 是一种从文字和噪音生成图片的模型
- Imagen (Google的模型,其 latent representation 是一张缩略图
整体思路
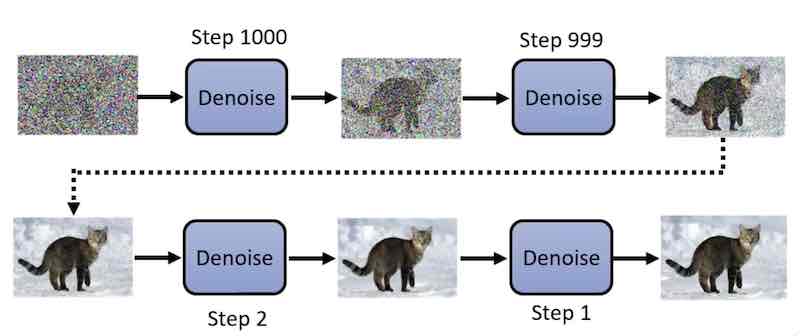
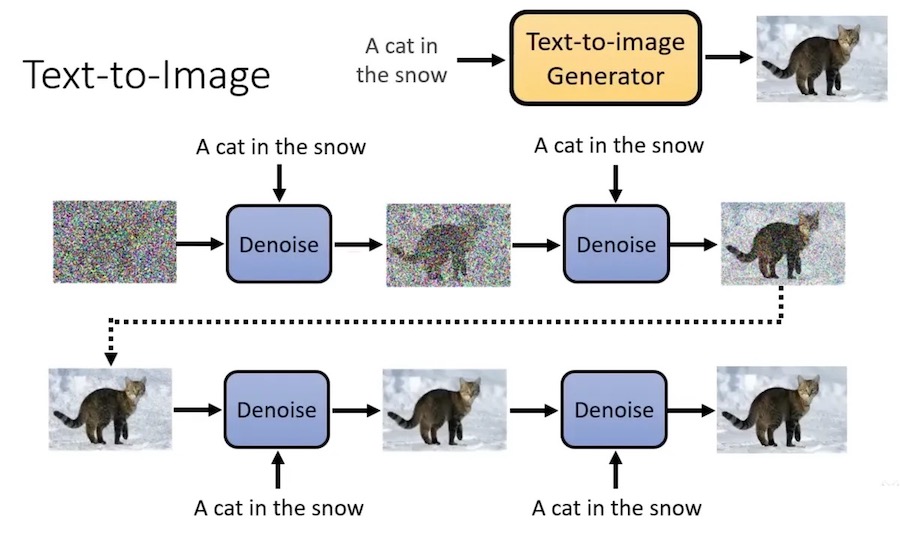
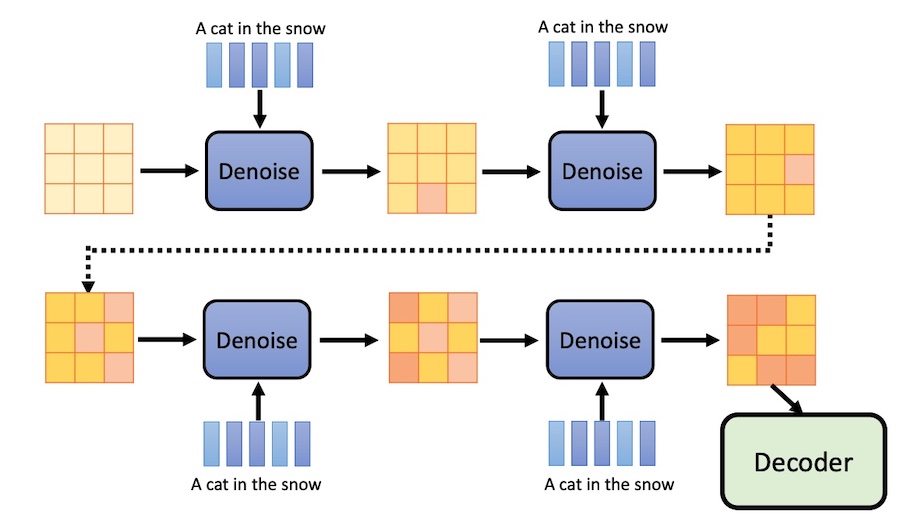
这个过程叫做 reversed process
- 它把一张白噪声图片,一步一步转变为一个有意义的图片
- 每个 Denoise 的参数都是一样的
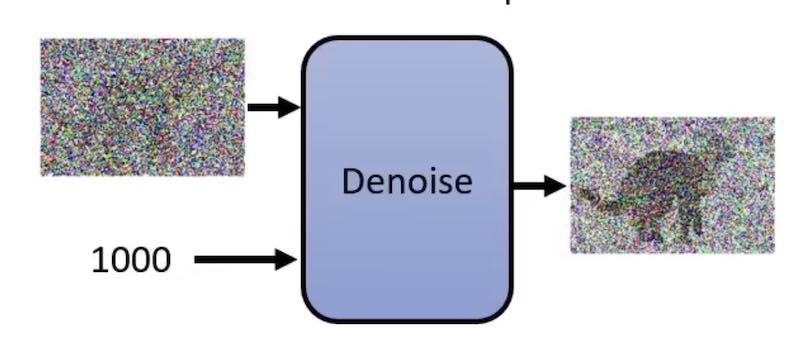
每个 Denoise 接受两个输入:
- 一张图片
- 当前位置序号。这个序号依次从1000到1
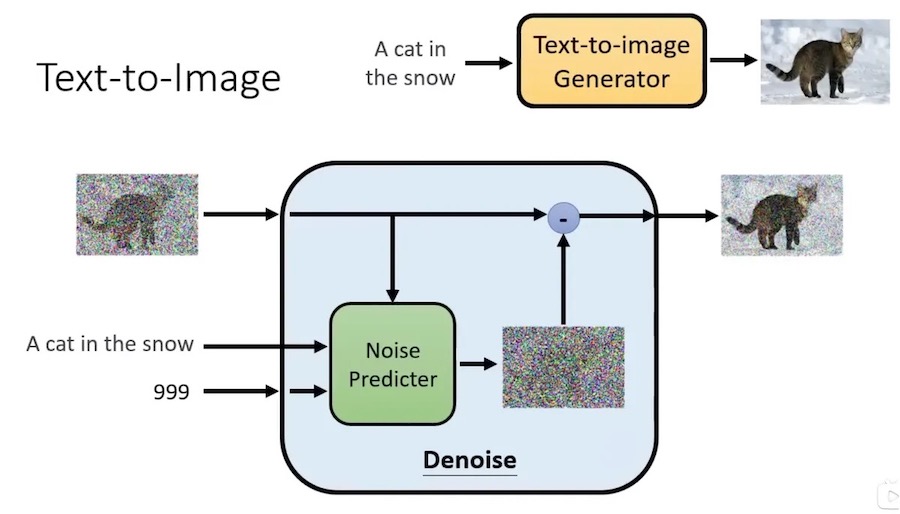
Denoise 内部结构:
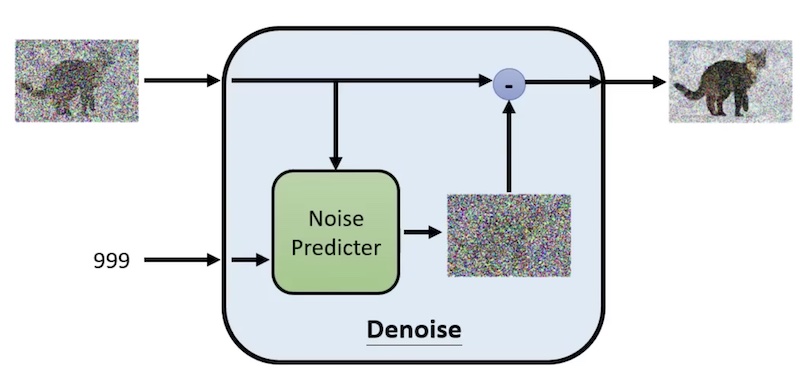
它的是这样的
- Noise Predicter,功能是预测图片中的噪声
- 然后把输入图片减去噪声
- 最终得到一个噪声少一些的图片
如何得到训练 Noise Predicter 所需要的数据?
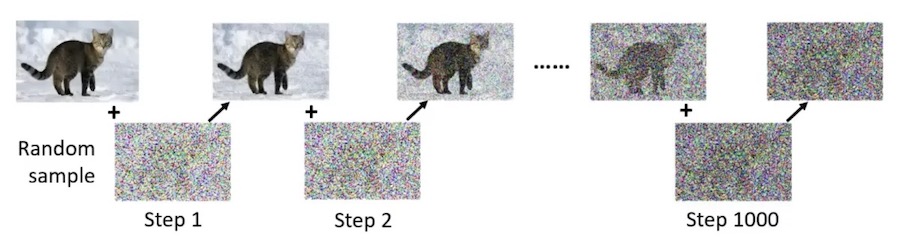
步骤
- 训练集中取一张图片
- 加上随机噪声
- 得到加噪的图片
- 这个过程叫做 Forward Process(Diffusion Process)
以上是生成图的过程,接下来的问题是如何把文字考虑进来
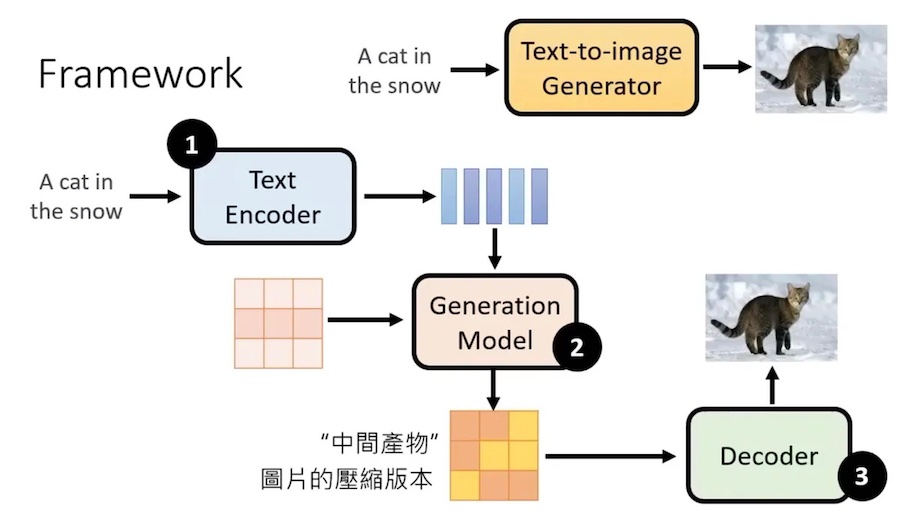
只需要把文字加入 Denoise:
Denoise 内部的结构
它包括3个模块,这3个模块分开训练
- Text Encoder:把一段文字转化为 embedding
- Generation Model。
- 输入:Text Encoder 产生的 embedding + 杂序图
- 输出:图片的压缩的版本 latent representation (可以是一个小的缩略图,也可以是一个人看不懂的张量)
- Decoder:根据 “图片压缩的版本”,产生一张高清图
- 如何训练?
- 如果中间产物是缩略图,可以把样本中的图片缩放,得到一组 X,y
- 如果中间产物是 latent representation,可以训练一个 Encoder-Decoder 模型
- 如何训练?
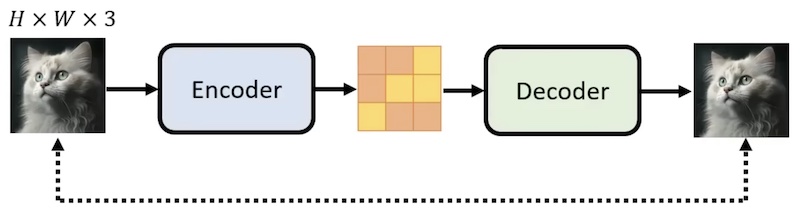
其中的 Decoder 有两种(如图)
- 如果为小图,
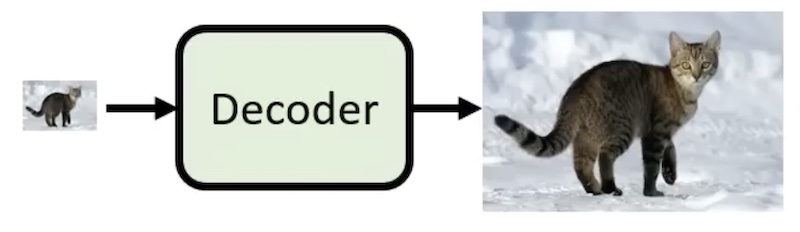
- 如果为 latent representation
模型评估
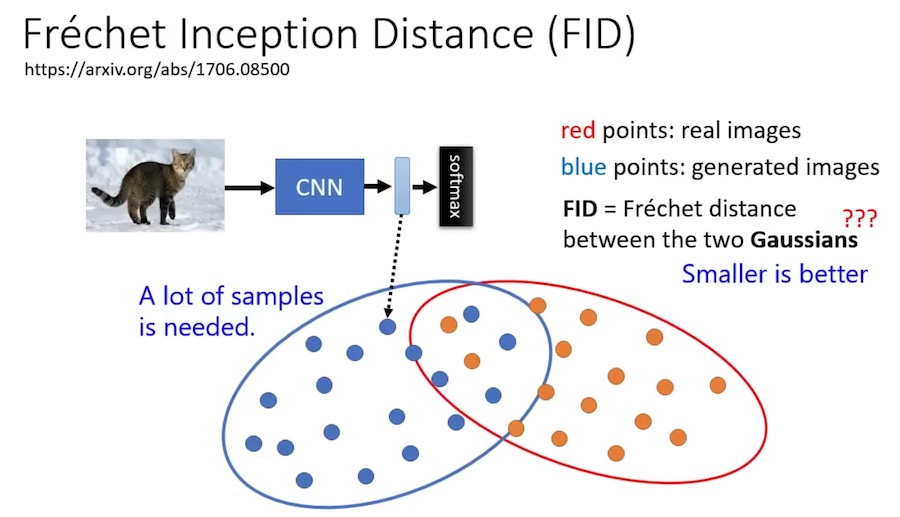
如何评估影响生成模型的好坏?FID
- 先有一个 CNN 模型(图像分类模型)
- 去掉最后的 Softmax 层,得到图片的 embedding
- 生成的图片和真实的图片,都有对应的 embedding
- 比较两组 embedding 的差别
- Stable Diffusion的做法是,假设两组服从高斯分布,然后计算它们的均值,进而比较距离。
另一种模型评估方案:
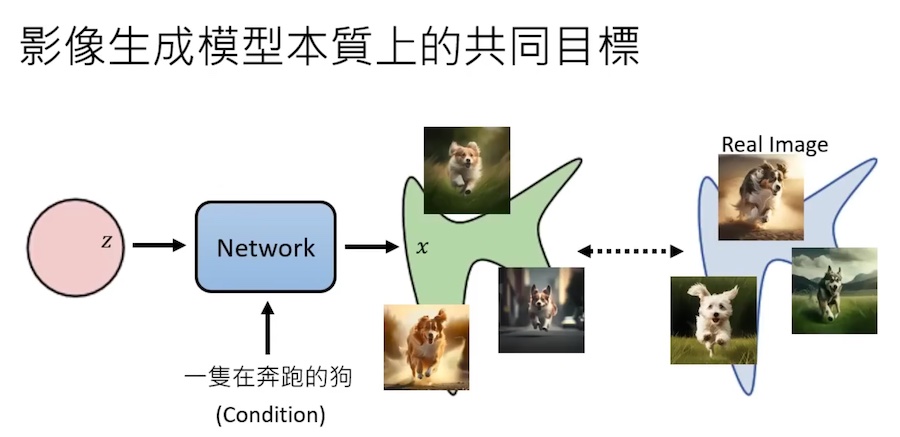
产生的图片和真实图片,两组概率分布尽量相同。
用极大似然估计。经公式推导,等价于 KL 散度。
模型细节
细节1
实际上不需要对原图加噪,只需要对 “中间产物”(latent represent) 加噪
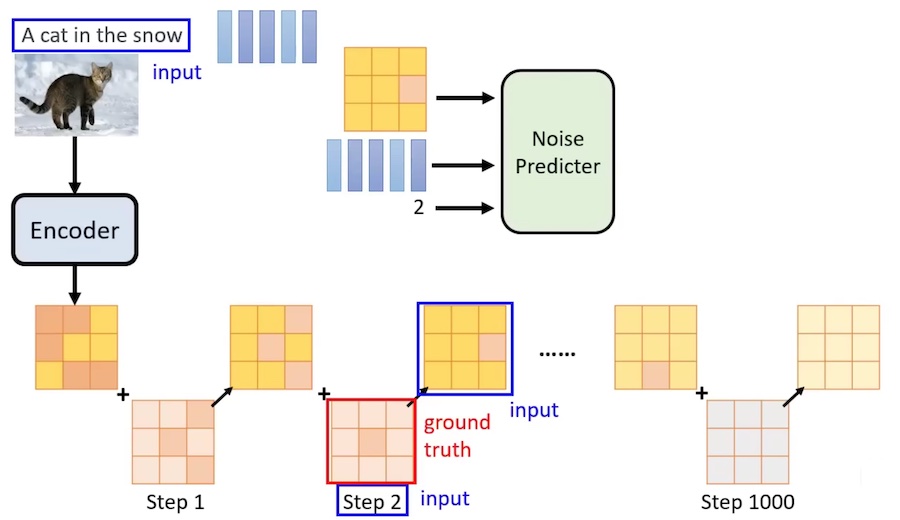
上面图是加噪的过程(forward process)
下面的图是 Denoise 的过程
细节2
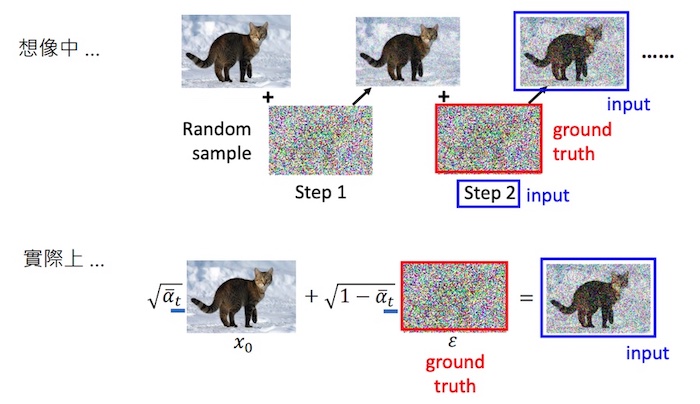
实际上,加噪音不是一步一步来的,而是一次性的
VAE vs Diffusion Model
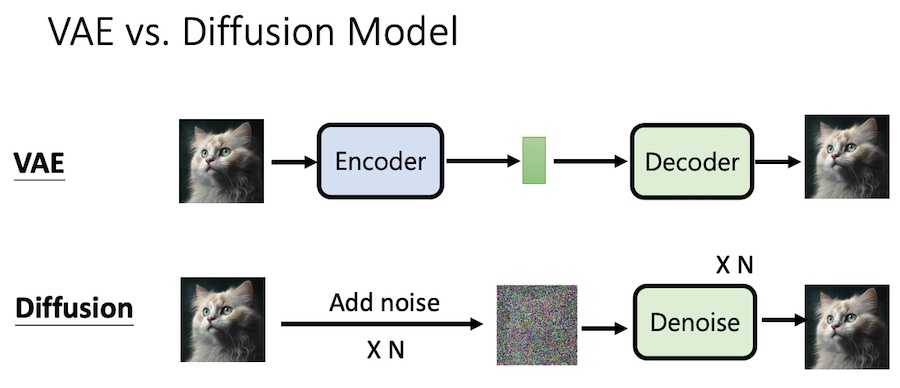
VEA 的 Encoder 是神经网络,而 Diffusion Model 是直接加上噪音
参考资料
- 视频课程:https://www.youtube.com/watch?v=ifCDXFdeaaM
- 课件:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
- https://www.bilibili.com/video/BV14c411J7f2/
您的支持将鼓励我继续创作!
