【YOLO】理论与实现
🗓 2024年07月14日 📁 文章归类: 0x25_CV
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2024/07/14/yolo.html
YOLO
(you only look once)
- Real-Time:速度快,标准版每秒处理 45帧,Fast YOLO 每秒 155帧
- YOLO 把检测编程一个回归问题,输入是图像,输出是 bounding boxes + 类别的概率
- 应用极为广泛,例如 自动驾驶、安防监控
YOLO-v1 的思路
- 分割图片,形成 SxS 个 grid,每个 grid 大小相同
- YOLO 要求物体的 中心 落在某个 grid 中,那么由这个 grid 来表示有这个物体,假设一个框可以预测 B 个物品
- 每个物品有5个量,分别是物体的中心位置
(x, y),它的高和宽(h, w)预测的置信度 confidence, - 假设整个 YOLO 需要预测 C 种物品
- 那么每个框需要预测
B * 5 + C个数字 - 因此整个模型的 y 的长度为
S * S * (B * 5 + C) - 举例来说:
- 某个 YOLO 可以检测 20种物体,它用的是 7x7 的 grid,每个框预测 2个物体,那么它的输出是:
7 * 7 * (2 * 5 + 20) = 7 * 7 * 30的 tensor- 它最多能预测多少个物体?
7 * 7 * 2个
- 损失函数:误差 = 定位误差 + 分类误差
- 特点
- 速度快。因为是一个网络,且是一个回归问题
- 基于其设计特点,YOLO 在训练和推理时会看到整个图像,比 RCNN 之类的正确率高
- 泛化好。能学习到物体的通用表示
- 使用了更少的卷积层

NMS
- 问题:一个物体可能被多个框检测到
- 为了去掉多余的框,设计了以下做法
算法
- 选取这类 box 中 scores 最大的那个,记为 box_bset
- 计算 box_best 与其它 box 的 IOU
- 如果 IOU > 0.5,认为它们表示了同一个目标,就丢弃掉这个 box
- 在剩余的 box 中,再找 最大 score,如此循环
实践
- labelImg:用来做图像标注的工具
- 标注后的数据除了图片外,是 xml 格式,里面有类别、坐标等信息
- 用 torch 直接写 YOLO 还是稍微麻烦,可以调一个封装好的包 ultralytics
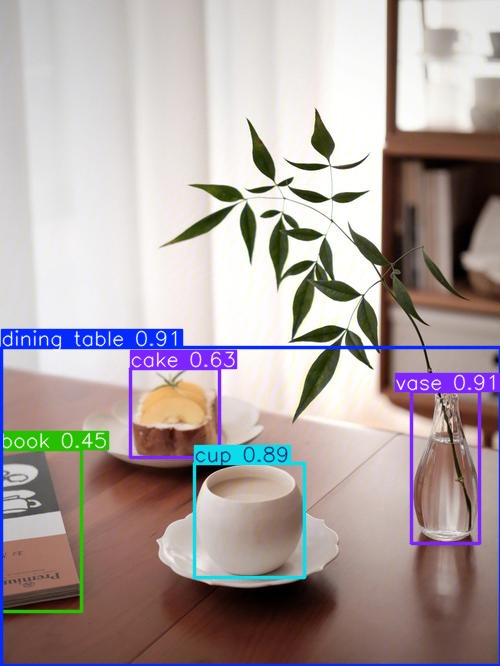
使用预训练模型
from ultralytics import YOLO
# 会自动下载模型,下次换成下载好的模型文件
model = YOLO('yolo26n.pt')
# 使用model进行目标检测
results = model("/1.png")
results[0].show()
训练
文件结构
├── dataset.yaml
├── test
│ │ └── ...
└── train
├── images
│ ├── 0.jpg
│ └── 0.xml
├── test.txt
├── train.txt
└── val.txt
其中,dataset.yaml 是这样的:
path: ./all_data # 数据集根目录,最好用绝对路径
train: train/images # 训练图像路径
val: eval/images
test: test/images
# 类别名称
names:
0: cat
1: dog
2: people
3: cup
4: door
5: car
训练代码
from ultralytics import YOLO
import os
model = YOLO('yolo26n.pt')
# model = YOLO('yolo26n.yaml') # 这个从头开始训练
model.info()
# 模型训练
results = model.train(
data='./data/dataset.yaml', # 数据集配置文件
epochs=20, # 训练轮数
batch=16, # 批次大小
imgsz=640, # 输入图像尺寸
patience=50, # 早停轮数
save=True, # 保存模型
device='0', # GPU设备号,如果使用CPU则设为'cpu'
workers=8, # 数据加载线程数
pretrained=True, # 是否使用预训练权重
optimizer='auto', # 优化器类型
verbose=True, # 是否显示详细信息
# 数据增强参数
scale=0.5, # 图像缩放比例
mosaic=1.0, # 马赛克数据增强概率
mixup=0.1, # 混合数据增强概率
copy_paste=0.1, # 复制粘贴增强概率
)
# 在测试集上评估模型
results = model.val()
加载模型并预测
# 加载训练好的模型
model2 = YOLO('./runs/detect/train28/weights/best.pt')
# 在单张图像上测试模型
test_image_dir = './data/test/images'
if os.path.exists(test_image_dir):
for image_name in os.listdir(test_image_dir)[:5]: # 测试前5张图片
image_path = os.path.join(test_image_dir, image_name)
results = model2(image_path)
# 保存预测结果
results[0].save(os.path.join('./runs/detect/predict', image_name))
(还有训练它的代码,去官网上看)
您的支持将鼓励我继续创作!
