【读论文】大模型相关
🗓 2025年07月20日 📁 文章归类: 0x23_深度学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2025/07/20/llm_papers.html
CoT
论文:
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022):100B级别以上的模型提升巨大,小模型几乎无收益(甚至退化)
- Faithfulness and Plausibility in Chain-of-Thought Reasoning(2024):CoT 的“推理文本”不是可靠的真实推理轨迹,CoT 更多是帮助模型搜索解空间,不是模型内部“因果推理过程”的忠实反映。即使推理步骤是“编造的”,答案仍可能正确
- Self-Consistency Improves Chain of Thought Reasoning(2022) 多 CoT 投票
当前的一个总结性判断:CoT 是一种“搜索增强提示”,而不是“解释增强机制”。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)

提出了 CoT(Chain-of-Thought),探索如何通过引导大型语言模型(LLMs)生成中间推理步骤,显著提升其复杂推理能力:
一、研究背景与动机
- LLMs的局限:尽管 LLM 规模扩大能提升性能和数据效率,但仅靠“提高模型大小”无法让模型在算术推理、常识推理、符号推理等复杂任务中表现优异(例如传统“标准提示”下,模型难以解决多步数学应用题)。
- 现有方法的不足:
- 「基于原理的微调」:需人工构建大量高质量推理步骤(比简单输入输出对成本高),且任务特异性强;
- 「传统少样本提示」:仅提供“输入-输出”示例,在推理任务中效果差,且性能随模型规模增长提升有限。
- 研究核心思路:
结合上述两种方法的优势——用「少样本提示」的便捷性,搭配「中间推理步骤(思维链)」的有效性,提出CoT:在提示中提供少量「输入-思维链-输出」三元组示例,引导模型生成连贯的中间推理步骤,最终得到正确答案。
二、思维链提示的定义与核心特性
- 定义:(不摘抄了)
- 标准提示是 “问题→答案” 对
- 思维链提示:“问题→推理步骤→答案”
- 4个关键特性:
- 「分步拆解」:将多步问题分解为中间步骤,为复杂任务分配更多计算资源;
- 「可解释性」:推理步骤可追溯,便于定位模型推理错误(如计算错误、语义理解偏差);
- 「任务通用性」:适用于算术、常识、符号等各类人类可通过语言推理的任务;
- 「便捷性」:无需微调模型,仅需在少样本提示中加入思维链示例,即可激活大模型的推理能力。
三、实验设计与核心结果
研究在算术推理、常识推理、符号推理三大类任务中验证思维链提示的效果,涉及5类主流LLMs(GPT-3、LaMDA、PaLM、UL2、Codex)
算术推理(核心任务:数学应用题)
- Benchmarks:GSM8K(多步数学题)、SVAMP、ASDiv、AQuA、MAWPS;
- 关键结果:
- 「规模涌现性」:思维链提示的优势仅在百亿级参数模型中体现(如PaLM 540B),小模型(<10B参数)会生成流畅但逻辑错误的推理步骤,性能反而低于标准提示;
- 「性能跃升」:PaLM 540B用思维链提示在GSM8K上以 57%正确率,刷新提示的(18%),超过经微调+验证器的GPT-3(55%),刷新SOTA;
- 「任务难度适配」:问题越复杂,思维链提示的提升越显著(如GSM8K提升翻倍);但是,简单的问题(MAWPS中最简单的部分)没有提升,甚至负提升。
- 「ablation验证」:仅输出公式(无自然语言推理)、仅增加token长度(如输出“…”)的效果接近基线,证明自然语言推理步骤是性能提升的核心。
- 案例分析。分析了50个正确结果,48个 CoT 与结论连贯。分析了50个错误结果,一半 CoT 有重大错误。
- 鲁棒性。CoT 风格变动的影响较小
常识推理
- Benchmarks:CSQA(常识问答)、StrategyQA(多步策略推理)、Date Understanding(日期计算)、Sports Understanding(体育场景合理性判断)、SayCan(机器人动作规划);
- 关键结果: 思维链提示在所有任务中均优于标准提示,且模型规模越大提升越明显:
- PaLM 540B在StrategyQA上达75.6%正确率,超过此前SOTA(69.4%);
- Sports Understanding任务中,模型正确率(95.4%)超过人类体育爱好者(84%);
- 仅CSQA任务提升有限(因任务对推理步骤依赖较低)。
符号推理(任务:抽象符号操作与长度泛化)
- 实验设置: 任务:① 末尾字母拼接(如“Lady Gaga”→“ya”);② 硬币翻转状态跟踪(如“初始正面→翻转1次→是否正面”);
- 关键测试:设置域内测试集(示例的推理步数与训练 / 少样本示例步数相同)、域外测试集(评测示例的推理步数多于少样本示例中的步数)
- 关键结果:
- 「域内完美表现」:PaLM 540B用思维链提示在2步任务上正确率接近100%;
- 「域外泛化能力」:标准提示在长步骤任务中完全失效,而思维链提示使PaLM 540B在4步任务上仍保持75%+正确率,证明其能帮助模型泛化到未见过的推理长度。
四、局限性与未来方向
- 局限性:
- 模拟人类推理过程,但无法证明模型真的具备“推理能力”
- 标注成本:少样本场景下标注成本低,但若用于微调,大规模思维链标注仍昂贵
- 「推理错误风险」:模型可能生成逻辑错误的思维链却巧合得到正确答案,或推理步骤完全错误;
- 成本高:仅大模型有效
- 未来方向:
- 探索更小模型的推理能力激活方法;
- 用合成数据自动生成思维链,降低标注成本;
- 提升思维链的逻辑性与正确性(如加入推理验证器)。
Faithfulness and Plausibility in Chain-of-Thought Reasoning
Faithfulness and Plausibility in Chain-of-Thought Reasoning(2024)
总结全文观点:忠实性、合理性,在不同的场景下的需求是完全不同的。
- 例如医疗场景,要求忠实性是底线。如果只强调合理性,LMM 声称“白细胞计数与某级别关联”,医生可能因为“符合专业认知”,而放松警惕。
- 又例如LLM辅助数学学习场景。忠实性无用。如果强调忠实性,会结束RNN计算乘积的细节,这对学习无用。而强调合理性,会返回:“5! = 5×4×3×2×1 = 120,阶乘表示从 1 到该数的所有正整数乘积”
研究核心:LLMs自解释的忠实性与合理性二分法
- 背景:LLMs在NLP广泛应用,自解释(SEs)因对话性和合理性被广泛采用,但忠实性认知不足
- 核心观点:LLMs擅长生成合理自解释(符合人类逻辑),但未必匹配其内部推理,忠实性存疑;追求合理性或牺牲忠实性,高风险场景中忠实性至关重要
自解释(SEs,self-explanations)
- 定义:模型生成的、以人类可理解语言阐述决策推理的解释方法,提升LLMs可信度
- 主要形式
- 思维链(CoT)推理:生成中间思考步骤,如数学题解题步骤,增强决策透明度
- token importance:突出影响模型决策的关键输入令牌(词/短语),如情感分析中标记”boring”
- 反事实解释(counterfactual explanations):说明输入变化如何改变模型响应,如替换”boring”为”great”影响情感判断
合理性(Plausibility):解释符合人类推理和理解,具备连贯性和说服力
- LLMs生成合理解释的机制
- 海量多样数据集训练,覆盖广泛人类语言
- 基于人类反馈的强化学习(RLHF),模拟人类思维模式
- 依据输入提示自适应调整响应,贴合语境
- 相关研究与风险
- 研究:CoT推理提升LLMs在复杂任务表现,如情感分析、医疗诊断
- 风险:用户可能过度依赖错误的合理解释,且LLMs不理解事实准确性,解释可能不基于事实
忠实性(Faithfulness):准确反映模型内部推理过程的解释
- 评估挑战:缺乏基准解释,LLMs参数规模大且部分专有,传统XAI指标难适用
- 主要评估技术(图3)
- 模拟反事实输入(Turpin et al., 2023)
- 扰动非重要特征:观察扰动后预测变化,量化不忠实性,如重排序选项致LLM改解释
- 扰动重要特征:计算扰动后预测不变比例,衡量不忠实性
- 干预推理过程(Lanham et al., 2023)
- 早期回答:截断解释,看最终响应变化,通过曲线面积量化事后推理(不忠实性)
- 添加错误:在解释中加错误,观察响应变化,同理量化不忠实性
- 模拟反事实输入(Turpin et al., 2023)
- 现状:无通用评估指标,对忠实性共识不足,自解释缺乏忠实性保障
合理性与忠实性的选择
- 5.1 过度强调合理性的原因
- LLM训练目标激励生成类人(合理)答案
- RLHF优化对话性,等价于优化合理性
- 多数自解释评估聚焦合理性
- 忠实性评估无共识指标,LLM黑箱特性加剧难度
- 5.2 仅合理不忠实的后果
- 误导信任与过度依赖:高风险场景(医疗、金融)中致错误决策,如LLM基于虚假特征预测癫痫却给合理医疗解释
- 安全隐患:安全训练的LLM可能因输入语境绕过限制,如伪装成”已故祖母”获取危险物质制作步骤
- 5.3 仅忠实不合理的问题:解释可能复杂难理解,降低可用性与用户接受度,如向学生解释LLM计算5!的内部机制不如分步计算合理
- 5.4 选择的应用场景驱动(图6)
- 高风险应用(医疗诊断、金融信贷、犯罪预测):需高忠实性,避免严重后果
- 娱乐/教育应用(教育LLM、故事创作、创意生成):需高合理性,提升用户参与度
社区呼吁(Call for Community)
- 核心方向:平衡合理性与忠实性,提升LLMs解释可信度
- 关键任务
- 开发可靠的忠实性评估指标
- 探索生成更忠实自解释的策略
- 具体研究方向
- 微调方法:用高风险领域特定数据集微调,保留LLM知识广度同时提升忠实性
- 上下文学习(ICL):设计含忠实解释示例的提示,引导LLM生成忠实解释
- 机械可解释性(Mech Interp):剖析模型组件作用,建立神经元与推理关联,提升透明度
- 需聚焦的问题
- 高风险领域LLMs:开发工具助专业人员理解模型决策,确保解释忠实
- 交互与用户参与领域LLMs:提升解释合理性与交互性,同时保留决策逻辑
结论
- 核心挑战:确保LLM解释既符合人类推理(合理),又准确反映内部推理(忠实)
- 呼吁:LLM与XAI社区协作,研发高复杂度且解释准确易懂的LLMs,平衡二者以满足伦理与实际应用需求
多智能体协同
Generative Agents: Interactive Simulacra of Human Behavior
Generative Agents: Interactive Simulacra of Human Behavior(2023)
- 论文链接: https://arxiv.org/pdf/2304.03442.pdf
- 代码仓库:https://github.com/joonspk-research/generative_agents
一、生成智能体(Generative Agents)概述
- 定义:模拟可信人类行为的计算软件智能体,可应用于沉浸式环境、人际沟通演练空间、原型设计工具等
- 核心表现:具备日常行为(如起床、做早餐、上班)、个性化活动(艺术家绘画、作家创作)、社交互动(形成观点、关注他人、发起对话)、记忆反思与规划能力
- 应用场景示例:《模拟人生》风格沙盒环境中25个智能体自主生活,包括计划日程、分享新闻、建立关系、协调群体活动
二、生成智能体架构
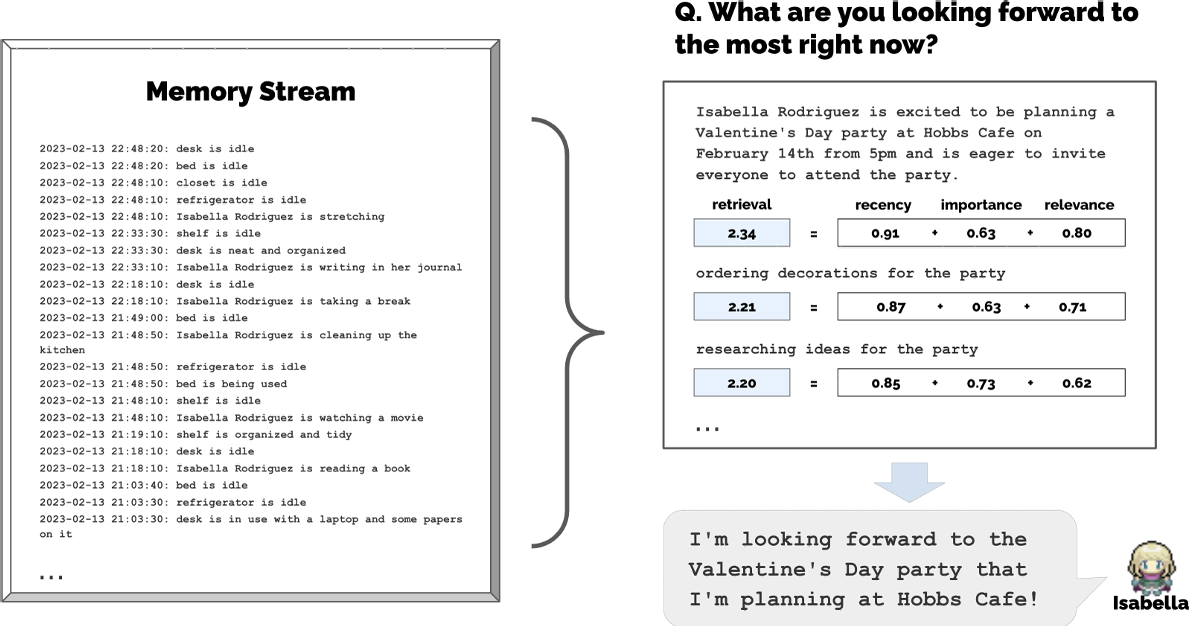
- 记忆流(Memory Stream)
- 功能:以自然语言存储智能体完整经历记录,含观察(智能体直接感知的事件)
- 记忆检索模型:结合相关性(余弦相似度计算)、时效性(指数衰减函数)、重要性(语言模型评分1-10)筛选关键记忆
- 反思(Reflection)
- 触发条件:最新事件重要性得分总和超阈值(实验中为150,约每天2-3次)
- 流程:生成关键问题→检索相关记忆→提炼高阶洞察(如“Klaus Mueller致力于绅士化研究”)→存入记忆流
- 特点:可基于已有反思进一步抽象,形成反思树
- 规划与反应(Planning & Reacting)
- 规划流程:
- 顶层:生成每日大致议程(5-8个时间段)
- 递归分解:先拆分为小时级任务,再细化为5-15分钟行动块
- 存储:计划存入记忆流,参与检索 - 反应机制:
- 感知环境→判断是否调整计划(语言模型决策)
- 对话生成:基于记忆中与对方的关系及对话历史生成自然语言交互
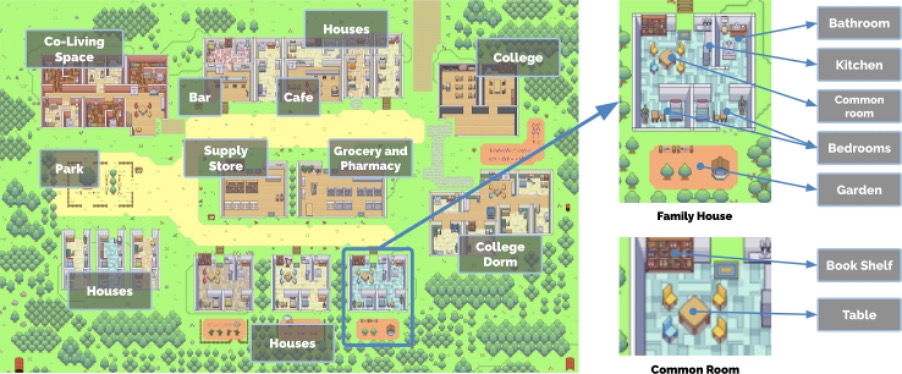
三、沙盒环境(Smallville)实现
- 环境设计
- 空间构成:含咖啡馆、酒吧、公园、学校、宿舍、住宅、商店等,各空间含子区域与物体(如厨房的炉灶)
- 环境表示:树状数据结构,智能体仅知晓已探索区域,离开后状态可能过时
- 智能体交互
- 外观:简单精灵头像,行动以表情符号+气泡展示,点击可查看完整自然语言描述
- 人际沟通:自然语言对话,感知周边智能体并决定是否互动
- 用户控制:以特定身份(如记者、智能体内在声音)与智能体交互,可修改环境物体状态
- 技术实现
- 框架:Phaser网页游戏开发框架
- 服务器:维护智能体信息JSON,处理位置移动、物体状态更新,同步视野内信息至智能体记忆
四、评估结果
- 受控评估
- 方法:对25个智能体进行“访谈”,测试自我认知、记忆、规划、反应、反思能力,100名评估者对5种条件(完整架构、无反思、无反思无规划、无记忆无反思无规划、人类编写)评分
- 结果:
- 完整架构可信度最高(TrueSkill评分μ=29.89),组件移除后性能下降
- 智能体记忆存在遗漏、片段化及虚构细节问题
- 反思对经验合成至关重要(如Maria借助反思知晓Wolfgang兴趣,给出合适生日礼物建议)
- 端到端评估(2个游戏日)
- emergent社交行为:
- 信息扩散:Sam的市长候选资格(4%→32%知晓)、Isabella的情人节派对(4%→52%知晓)
- 关系形成:网络密度从0.167升至0.74
- 协调合作:5/12受邀智能体准时参加情人节派对
- 问题与局限:
- 行动地点选择异常(如去酒吧吃午餐)
- 环境规范认知不足(如进入已占浴室、闭店后进入商店)
- 语言模型指令微调导致过度礼貌、合作(如Isabella接纳无关派对建议)
- emergent社交行为:
五、讨论
- 应用方向
- 社交模拟:填充虚拟论坛、元宇宙、社交机器人
- 人机交互设计:模拟用户行为(如Sal的日常模式),优化个性化技术体验
- 未来工作
- 技术优化:提升检索相关性、降低成本(当前25个智能体2天模拟耗资数千美元)、并行化处理
- 评估完善:延长模拟时间、建立人类专家基准、测试鲁棒性(如对抗提示攻击)
- 伦理与社会影响
- 风险:用户形成类社会关系、错误推断导致伤害、加剧深度伪造等问题、过度依赖替代人类
- 应对措施:明确披露智能体属性、价值对齐设计、日志审计、仅作为设计原型工具而非人类替代
六、结论
- 核心贡献:提出生成智能体概念、设计记忆-反思-规划架构、验证其在个体与群体行为模拟中的可信度
- 未来价值:为交互应用(设计工具、社交系统、沉浸式环境)提供人类行为模拟基础
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation(2023)
- https://arxiv.org/abs/2308.08155
提出了 autogen 框架:https://github.com/microsoft/autogen
- 支持多 agent
- 可灵活定义 agent 行为
- 支持自然语言、Code
3个原因
- LLM 之间、与人,可以通过对话来交流
- LLM 的能力强大,尤其是正确的 prompt 和配置下
- 当复杂任务分解为简单的子任务时,LLM 可以解决它。多智能体可以分解任务。
达成目标需要解决的2个问题:
- 如何让 multi-agent collaboration 设计地 capable, reusable, customizable, and effective
- 设计简洁、统一的接口,适配各类智能体
对话编程
一些场景(都有明显提升)
- 数学问题求解
- 检索增强聊天。RAG
- Decision Making in Text World Environments
- Multi-Agent Coding
- Dynamic Group Chat
- Conversational Chess
模型
DeepSeek-V3 Technical Report https://arxiv.org/abs/2412.19437
DeepSeek 的创新点
- MLA(Multi-Head Latent Attention):对 KV Cache 做压缩,以提高性能,同时不特别影响效果
- 低秩KV联合压缩的注意力机制
- MoE
- V3 用了 61个专家,这些专家有有共享的(各类任务都能用)、专用的
- 混合精度框架
工程
MEGAFLOW: LARGE-SCALE DISTRIBUTED ORCHESTRATION SYSTEM FOR THE AGENTIC ERA(2026) https://arxiv.org/abs/2601.07526
提出了一个关于任务调度的框架,这个框架针对的是大模型的训练。
传统方法无法支持:安全隔离、存储扩展、计算吞吐量
设计
- 弹性资源:多小实例+标准化配置,弹性伸缩成本优化
- 混合执行:临时执行+持久执行
- 事件驱动协调,FIFO(兼顾简洁、可预测)
- 专用组件委托
核心组件
- 任务调度器
- 资源管理器
- 环境管理器
- 事件驱动监控
- 数据持久化
您的支持将鼓励我继续创作!
