【vLLM】学习笔记
🗓 2025年09月13日 📁 文章归类: 0x23_深度学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2025/09/13/vllm.html
概念
- vLLM 推理加速
训练加速:
- Megatron:并行和流水线
- DeepSpeed:优化器。也有推理能力
更底层的
- NCCL:通信库
vLLM
https://github.com/vllm-project/vllm
KV Cache 机制
- 大模型一个一个吐出 Token,然后把已经输出的所有的 Token 放一起继续计算下一个。
- 这个过程中,前面的 Token 之间的 K 和 V 是不变的。
- 如果每次都重新计算它们,就太浪费了。
- 因此把前面的 K 和 V 存下来,就节省了大量计算资源
- 也正是因为这个机制,在 LLM 输出时,你不会感觉到越来越慢
但 KV Cache 也是有浪费的
- 大模型一开始不知道要生成多少 Token,因此按最大预分配
- 大模型预测第一个 Token 时,也要预分配全部 Cache,随着时间才逐渐用完,这也浪费
- 显存之间有碎片
vLLM 解决了以上问题,用了若干个方法:
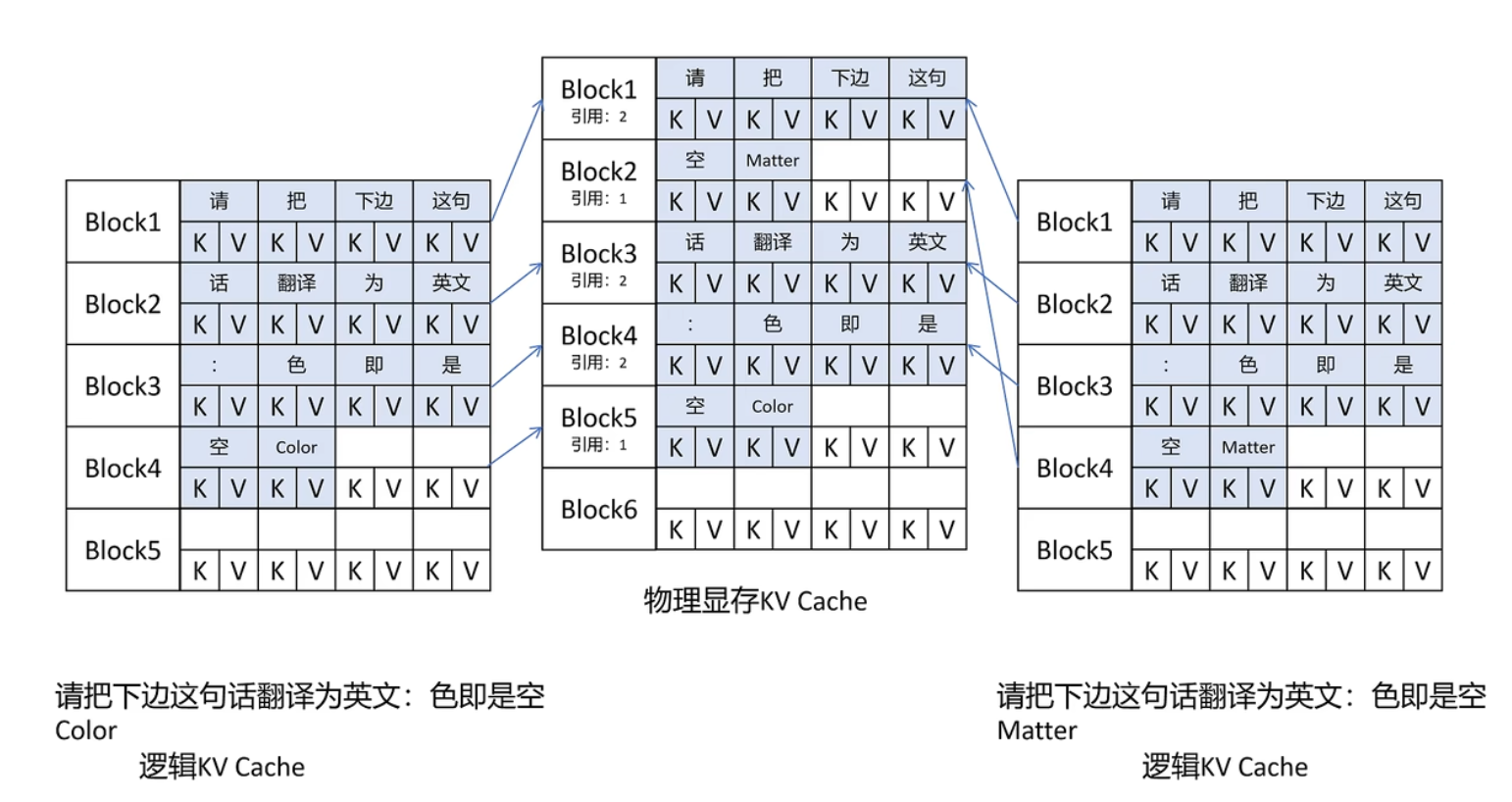
- 参考操作系统对内存的管理,用 “页” 来管理 KV Cache 集合,每页 N 个。也引入了逻辑显存、物理显存的概念
- 在 Prompt 相同时,只存放一份关于 Prompt 的 KV Cache,做法如下
- 对 Prompt 对应的 KV 块计数,计数
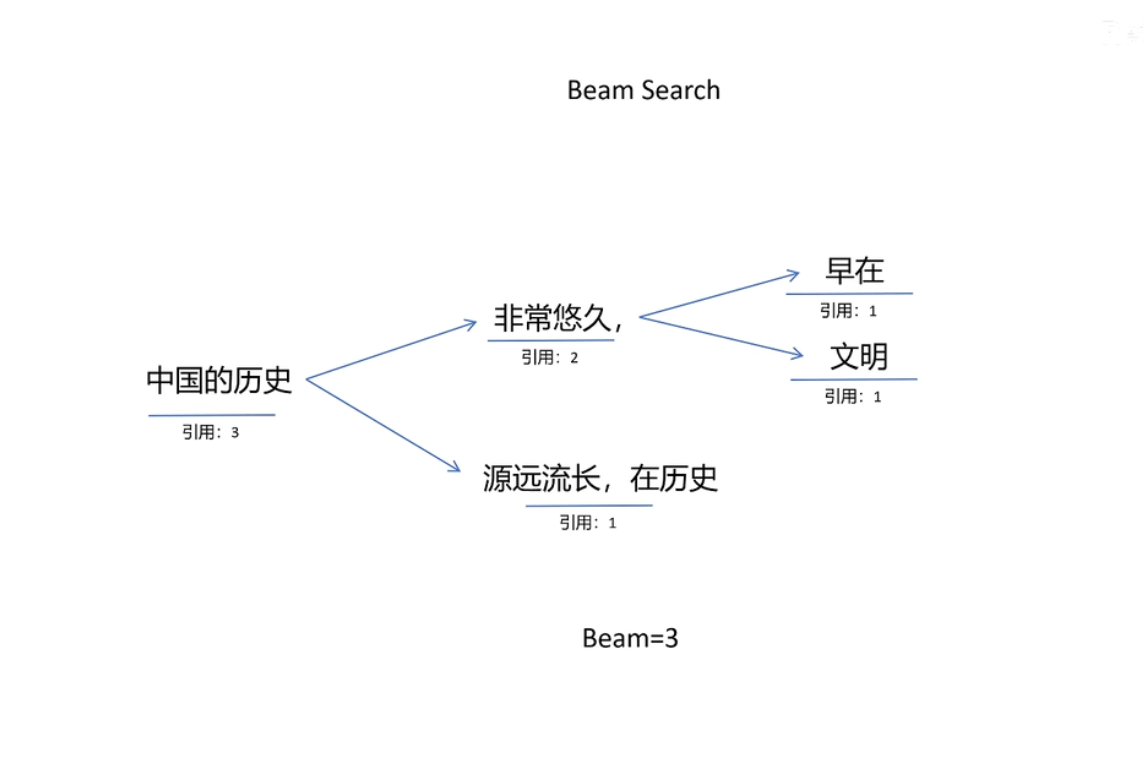
- Beam Search
例子
# 安装,要注意 CUDA 版本
# pip install vllm
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
# 换成你的模型地址
model_dir = "/path/to/model/Qwen/Qwen2.5-7B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 加载模型
llm = LLM(
model=model_dir,
trust_remote_code=True,
tensor_parallel_size=4, # 多卡可设为 GPU 数
gpu_memory_utilization=0.9,
max_model_len=16 * 1024, # 上下文长度
)
#%% 接下来是推理阶段
# 输入
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "用一句话介绍 vLLM。"},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
sampling_params = SamplingParams(
n=1, # 同一个 prompt,返回多少个输出序列
temperature=0.7,
top_p=0.9,
max_tokens=8192, # 输出的最大 Token 数量
)
# 推理
outputs = llm.generate([prompt], sampling_params)
# 第一个 [0] 代表:可以一次输入多个 prompt;第二个 0 对应前面设置的 n
print(outputs[0].outputs[0].text)
# 结束已经启动的模型,释放显存
# del llm
还可以用命令行启动,它启动的是一个网络服务,支持 stream 调用
启动服务
vllm serve /path/to/model/Qwen/Qwen2.5-7B-Instruct \
--host 0.0.0.0 --port 8000 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.9 \
--max-model-len 8192 \
--trust-remote-code
# 还有其它模式
# 'chat', 'complete', 'serve', 'bench', 'collect-env', 'run-batch'
请求服务
# 查询当前启动了哪些模型
curl http://127.0.0.1:8000/v1/models
# 请求模型
curl -N http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/path/to/model/Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "system", "content": "你是安全分析助手,只输出JSON。"},
{"role":"user","content":"介绍一下 vLLM"}],
"stream": true,
"max_tokens": 2000
}'
# stream : 流式输出,删掉后是整体输出
Megatron
https://github.com/NVIDIA/Megatron-LM
为什么?
NN 训练耗时 = 训练数据 X 单步计算量 / 计算速率计算速率 = 单设备计算速率 x 设备数 x 多设备并行效率- 扩展来讲,取决因素为:
计算速率 = 单设备计算速率(摩尔定律、混合精度、算子融合、梯度叠加) x 设备数(服务器架构、通讯拓扑优化) x 多设备并行效率(数据并行、模型并行、流水并行)
Megatron:从单卡到千卡测试,算力线形提升
原理:
- 流水线。NN 按照层切分到不同设备,实现并行。(类似计算机原理的流水线)
MoE
OLMoE: Open Mixture-of-Experts Language Models(2024)https://arxiv.org/abs/2409.02060
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity(2021 https://arxiv.org/abs/2101.03961
混合专家模型。模型中的一部分参数拆分成多个“专家网络”,每次推理只激活若干专家
- 结构
- 结构:子网络通常是 Transformer 的 FNN 层
- 路由:小的路由决定如何分配
- 稀疏激活:每个 token 只计算少数专家
- 优点:
- 性能
- 论文指出,从推理最终表现看,
A1B-7B模型 超过稠密模型7B和1B。训练角度看,MoE 的收敛速度、训练效率,都有明显提高
- 缺点:
- 结构更复杂,
- 可能有专家负载不均衡的问题
您的支持将鼓励我继续创作!
