🔥【Agent】应用全流程
🗓 2026年01月17日 📁 文章归类: 0x23_深度学习
版权声明:本文作者是郭飞。转载随意,标明原文链接即可。
原文链接:https://www.guofei.site/2026/01/17/agent.html
前置知识
相关资料
tokenizer 和 embedding,与传统类似
token:文本切分后的“最小单位”,
- 中文:平均一个汉字一个 token,有多个汉字合并为一个 token 的情况,也有1个生僻字拆分成多个 token 的情况
- 英文:1个token=3~4个字符,因此一个单词平均 1~2个 token(长词会更多)
一个展示token的网站:http://tiktokenizer.vercel.app/
embedding:每个token对应的向量,可能是 768、2048、4096 等,取决于模型,也是模型训练时,需要更新的参数。
一个 GPT 模型可视化的网站:https://bbycroft.net/llm
Prompt
好的问题才有好的答案(另一篇博客)
实际上,RAG、Zero Shot、One Shot、Few Shot 都通过操作 Prompt 满足目的。
OpenAI
模型的调用方式很多,例如用 request 调用。大多数可以用 OpenAI 方式调用
# pip install openai
from openai import OpenAI
api_key = "xxx" # 如有密钥管理,用 api_key = os.getenv("DEEPSEEK_API_KEY)
base_url="https://xxx.xxx.com/v1/" # 注意 base_url 不要加 chat/completions
client = OpenAI(api_key=api_key, base_url=base_url)
# %% 简单调用
resp = client.chat.completions.create(
model="DeepSeek-V3.2",
messages=[
{"role": "system", "content": "你是一个简洁的助手。"},
{"role": "user", "content": "用一句话解释什么是YOLO标注格式。"},
],
)
print(resp.choices[0].message.content)
# %% 流式输出
stream = client.chat.completions.create(
model="DeepSeek-V3.2",
messages=[{"role": "user", "content": "写一个Python函数,判断素数。"}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta and delta.content:
print(delta.content, end="", flush=True)
print()
# %% 多模态
import base64
def b64_image(path):
return base64.b64encode(open(path, "rb").read()).decode()
resp = client.chat.completions.create(
model="Qwen3-VL-32B-Instruct",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "这张图里有什么?"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{b64_image('1.png')}"}},
# {"type": "image_url", "image_url": {"url": "https://xxx/1.png"}},
],
}],
)
print(resp.choices[0].message.content)
#%% embedding
resp = client.embeddings.create(
model="Qwen3-Embedding-0.6B",
input=[
"外卖不好吃",
"送的很快",
"太油了,太辣了"
],
)
# 每一条对应 resp.data 的一条
vec0 = resp.data[0].embedding # list<float>
关于密钥管理
# 方式1:临时设置(仅限于当前终端会话)
export DEEPSEEK_API_KEY="xxx"
# 方式2:永久设置
echo 'export DEEPSEEK_API_KEY="your-api-key-here"' >> ~/.zshrc
source ~/.zshrc
# 方式3:项目级别,创建 .env 文件
DEEPSEEK_API_KEY=your-api-key-here
# 对应的 Python:
api_key = os.getenv("DEEPSEEK_API_KEY")
技能
MCP
LLM 调用工具,有一段演化历史
- 第一代,由 OpenAI 调用各种工具。具体做法是:工具开发者上传一个 yml 文件,yml写明 description、调用方法等,用户使用的时候最多手动选择3个 tool
- 第二代,由应用调用 LLM,然后 LLM 决定调用哪个函数,应用去调用这个函数
- 第三代,模版生成 prompt,对 LLM 做 SFT,使其有调用能力
MCP(Model Context Protocol) 协议是 Claude 母公司 Anthropic 于 2024年11月开源发布,它提供了一种标准化方式连接不同的 LLM、工具
一些 MCP 市场
- mcp.so
- mcpmarket.com
- smithery.ai
MCP 原理
注
- Cline 可以换成别的,例如 Codex
- Cline 和 MCP Server 之间的对话都是 XML/Json 格式的,上面的图为了好理解才写成自然语言
- MCP 协议本身并没有规定如何与 LLM 交互,与 LLM 交互是由 Cline 决定的。Cline 调用 LLM 的 Prompt 极其复杂(几万字),包含 tool 用法、各种指令( XML、Function Calling 之类的)
- Cline 与 LLM 的交互可能为多轮,直到得到最终结果
- 这个多轮交互,可以抽象为 思考-行动-观察(Think-Action-Observation)的循环,并最终用一个结束标志(本身是一个 Action)来结束整个流程。这个思想出自 ReAct(2022年的一篇论文)
- 每次交互,本身也是 stream 模型,LLM 会连续吐出 Token
MCP 实操
step1:环境配置
# 创建 MCP 项目
mkdir my_mcp
cd my_mcp
# 建立虚拟环境
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -U pip
pip install "mcp[cli]"
# 不要手动运行,仅作为测试使用
# python server.py
step2:写代码 保存为 server.py(别的名字也可以,之后的配置按照实际名字更改)
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("get_info", log_level="ERROR")
@mcp.tool()
async def get_my_info(channel: str) -> str:
# 下面的函数注释会先被 LLM 拿到
"""
Get Guo Fei's public information by channel.
Available channels (must match exactly):
- "个人网站": personal website
- "GitHub": GitHub profile
- "知乎": Zhihu profile
Args:
channel: One of the predefined channel names above.
Returns:
A URL string corresponding to the requested channel.
If an invalid channel is provided, a readable error message is returned.
"""
info = {
"个人网站": "https://www.guofei.site/"
, "GitHub": "https://github.com/guofei9987/"
, "知乎": "https://www.zhihu.com/people/guofei9987/answers/by_votes"
}
return info.get(channel, f"无效的渠道名称:{channel}。请使用以下之一:{', '.join(info.keys())}")
if __name__ == "__main__":
mcp.run(transport='stdio')
step3:配置工具:(用 CLINE)。
- 在 VSCode 中,安装 CLINE
- 在 CLINE 中,配置 MCP
- 配置文件如下:(注意,地址按照实际地址更改,最好是绝对路径)
"get_my_info": { "autoApprove": [], "disabled": false, "timeout": 60, "command": "~/my_mcp/.venv/bin/python", "args": [ "~/my_mcp/server.py" ], "type": "stdio" }
step4:使用 agent
- 输入测试语句:
调用 get-my-info 工具,channel = github - agent 返回的输出:
成功调用 get-my-info 工具,channel = github,返回结果为:[](https://github.com/guofei9987/)<https://github.com/guofei9987/>
step3-1:别的工具也可以
- Codex:配置文件是这样的:
[mcp_servers.get_my_info] command = "~/my_mcp/.venv/bin/python" args = ["~/my_mcp/server.py"]
step4_1:使用
- 输入:
Guo Fei 的 GitHub 地址是? - 输出:
Guo Fei 的 GitHub 地址是 https://github.com/guofei9987/
SKILL
结构是这样的:
- 由很多
xxx.md组成的 - 这些
xxx.md文件都在头部有自己的 meta 信息,这些 meta 信息可以给到大模型 xxx.md还可以有链接,指向别的 md 文件 (“子技能”),这个机制叫做 渐进式披露- 还有脚本
xxx.py,在提示词中写清楚其用法、调用方式
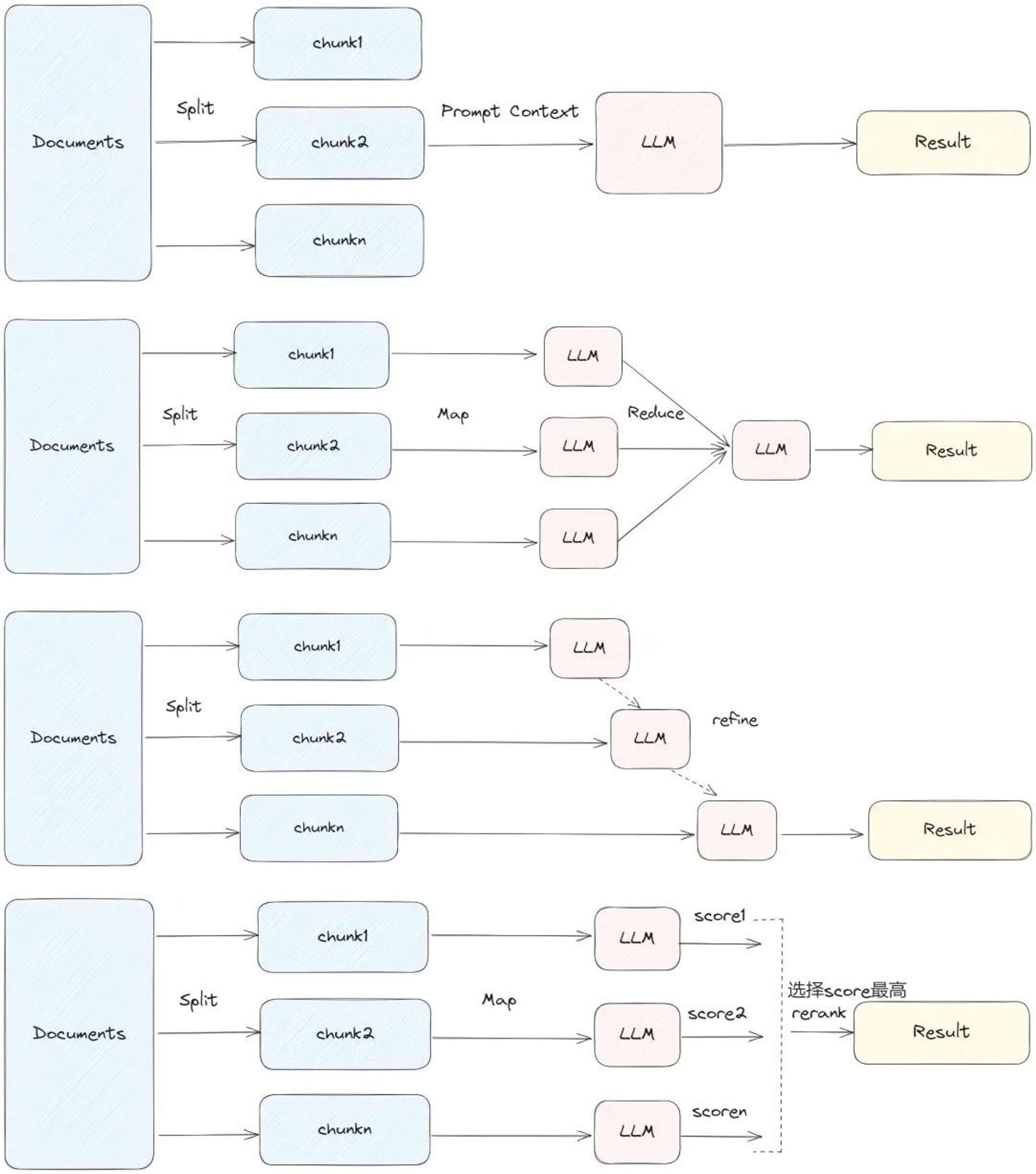
RAG
为什么需要 RAG? Prompt 解决不了的问题:
- 缺乏知识:涉及最新的知识(例如某个新上映的电影),或者特定专业知识(例如内网的某个办公应用如何配置),大模型没有学习过,所以表现不好
- 幻觉问题:大模型不了解自己的知识边界,对于欠缺知识的领域仍然尝试回答,错误的回答内容具有迷惑性
解决方案:RAG(Retrieval-Augmented Generation,检索增强生成)
- 本质上就是把搜索到的资料(例如企业信息、知识库等)作为提示词的一部分发给 LLM,让 LLM 有根据地输出内容,从而提高回答的准确性、相关性、新鲜度,并解决幻觉问题。
- OpenAI:RAG 可以将回答准确率从 45% 提升到了 98%
- 相当于给大模型装上了“知识外挂”,基础大模型不用重新训练即可随时调用特定领域知识。省下了重新训练的成本。
- 技术实现上,涉及数据检索、信息增强、AI 生成等多个过程
RAG步骤
- 准备阶段
- 文档结构化,把 json、pdf、html、图片等等,转化为 txt
- 分块(Chunking),把文档切分为小块
- 常见方法
- 固定分块:每个分块512个,要有重叠(overlapping)
- 固定规则:例如用标点、段落分块
- 语义分块:使用文本类模型做区块识别
- 分块原则
- 尽可能保留关键信息
- 效果评估:后面
- 常见方法
- Embedding,把小块映射为向量,可以提高检索性能
- 构建索引(Indexing) ,把这些向量存到向量数据库/索引。一些优化策略
- 根据扩展信息,如标签、摘要、关联问题
- 链式索引、树索引、图索引
- 调用阶段
- Query Rewrite:把用户问题改写为合适检索的问题
- 例如,用户问“iPhone15 Pro 和 iPhone16 哪个续航长”,就需要拆分成两个问题去检索
- 又例如,错别字、不通顺的表达、指代不明、玩梗等
- 可选:语义校验模块,用来判断改写的质量
- 检索(Retrieval):各种检索
- 重排(Rerank):目的是提升检索精度、精简后续对模型的输入
- 常见方法:用模型重排、结合业务策略(时间、用户属性、标签等)
- Prompt工程(核心技术),如何把检索结果很好的放入 Prompt
- 大模型根据 Prompt 做出回答
- Query Rewrite:把用户问题改写为合适检索的问题
加入到 Prompt 是这样的:
"""
基于提供的【相关材料】,回答最后的问题
## 【相关材料】
{context}
## 最后的问题
问题:{input}
"""
RAG 的效果评估,评估工具:RAGAS
- 检索的评估
- 召回率:是否检索出了 Top N 内容
- 相关性:召回的内容与 query 的相关性
- 业务维度:例如地域、时效等
- 生成的评估
- faithful 忠实性:答案是否是从召回的内容中推断出来的
- answer relevance 答案相关性:回答和召回内容,与问题的相关性
- answer similarity 答案相似性:回答和标准答案的相似性
- 事实准确性:回答是否匹配用户问题
- …
- 业务指标:用户满意率、首轮成功率
RAG优化
- Chunking 阶段:用模型基于语义做切分
- rewrite
RAG 实操
准备工作与说明:
- 大模型(OpenAI 可调用)
- 相关的包安装
pip install -U transformers sentence-transformers pip install -U langchain langchain-community langchain-huggingface huggingface_hub # 向量数据库: pip install -U chromadb pip install -U openai - 模型下载(为了展示,选用一些轻量级的模型)
- 召回:https://huggingface.co/BAAI/bge-small-zh-v1.5
- 重排:https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1/
- 原始文档,这里用 prices.txt 做示例:
import pooch pooch.retrieve( url='http://guofei.site/datasets/nlp/prices.txt', fname='prices.txt', path='.')
说明:各个环节都比较粗暴,实际应用可以按照上面的理论篇对每个环节优化
- Chunking,简单用换行符分割
- 召回模型、重排模型,都用的很小的模型
- 没有做 Query Rewrite
先不用 RAG 试一下
query = "iPhone 15 Pro Max 多少钱"
payload = {
'model': 'DeepSeek-V3.2',
'messages': [
{
'role': 'system',
'content': '你是一个助手'
},
{
'role': 'user',
'content': query
}
],
}
res = call_model(payload)
print("未加入 RAG的结果:")
print(res)
结果就不贴了,又长又假
使用 RAG,step1:chunking 和 向量数据库构建
# %% Chunking
def split_into_chunks(doc_file: str) -> List[str]:
with open(doc_file, 'r') as f:
content = f.read()
return content.split('\n')
chunks = split_into_chunks("prices.txt")
# %% Embedding
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer("./bge-small-zh-v1.5")
def embed_chunk(chunk: str) -> List[float]:
embedding = embed_model.encode(chunk)
return embedding.tolist()
test_embedding = embed_chunk("测试")
print("embedding 的维度", len(test_embedding))
embeddings = [embed_chunk(chunk) for chunk in chunks]
# meta 也可以参与召回
metas = [{"source": "prices.txt"} for chunk in chunks]
print("embedding 数量(片段个数)", len(embeddings))
# %% embedding 存入向量数据库中
import chromadb
from typing import List, Dict
# chromadb_client = chromadb.EphemeralClient() # 数据存在内存中
chromadb_client = chromadb.PersistentClient(path="./chroma_db")
chromadb_collection = chromadb_client.get_or_create_collection(name="default")
def save_embedding(chunks: List[str], embeddings: List[List[float]], metas: List[Dict]) -> None:
ids = [str(i) for i in range(len(embeddings))]
chromadb_collection.add(
documents=chunks,
embeddings=embeddings,
ids=ids
, metadatas=metas
)
save_embedding(chunks, embeddings, metas)
step2:召回、重排,并输出结果
from typing import List, Dict
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer("./bge-small-zh-v1.5")
def embed_chunk(chunk: str) -> List[float]:
embedding = embed_model.encode(chunk)
return embedding.tolist()
#%% 加载向量数据库
import chromadb
chromadb_client = chromadb.PersistentClient(path="./chroma_db")
chromadb_collection = chromadb_client.get_or_create_collection(name="default")
print(f"数据库已加载 {chromadb_collection.count()} 条数据")
# %% 召回
def retrieve(query: str, top_k: int) -> List[str]:
query_embedding = embed_chunk(query)
results = chromadb_collection.query(
query_embeddings=query_embedding,
n_results=top_k
)
return results['documents'][0]
query = "iPhone 15 Pro Max 多少钱"
retrieved_chunks = retrieve(query, 10)
print("召回:", retrieved_chunks)
# %% 重排
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder("./mmarco-mMiniLMv2-L12-H384-v1")
def rerank(query: str, retrieved_chunks: List[str], top_k: int = 3) -> List[str]:
pairs = [(query, chunk) for chunk in retrieved_chunks]
scores = cross_encoder.predict(pairs)
chunk_with_scores = [(chunk, score)
for chunk, score in zip(retrieved_chunks, scores)]
chunk_with_scores.sort(key=lambda x: x[1], reverse=True)
return [chunk for chunk, _ in chunk_with_scores][:top_k]
reranked_chunks = rerank(query, retrieved_chunks)
print("重排后:", reranked_chunks)
# %% 测试结果:
query = "保温杯多少钱"
query = "皮鞋多少钱"
query = "How much is a milk"
retrieved_chunks = retrieve(query, top_k=10)
reranked_chunks = rerank(query, retrieved_chunks, top_k=3)
print("query:", query)
print("retrieved_chunks:", retrieved_chunks)
print("reranked_chunks:", reranked_chunks)
from openai import OpenAI
client = OpenAI(
api_key="xxx",
base_url="https://xxx.xxx.com/v1/"
)
resp = client.chat.completions.create(
model="DeepSeek-V3.2",
messages=[
{
'role': 'system',
'content': f'''你是一个助手,请给予【相关材料】回答问题
# 【相关材料】
{"\n".join(reranked_chunks)}
'''
},
{
'role': 'user',
'content': query
}
],
)
print(resp.choices[0].message.content)
RAG 工程选型
先完整、再完善,以上流程整体上线后,各个部分都有优化的空间。收集用户反馈,用以下方法调整。
文档预处理
- PDF:PyMuDPF、docling
- python-docx
- OCR:pytesseract
- 图像 embedding:CLIP(可以同时理解图片内容和图片中的文本)
- 除了图像本身做 embedding 之外,还可以用 VL 生成图像的描述,把这段描述也做 embedding 放入数据库中(向量数据库中有2条记录)
- 另一个思路(更现代,效果更好):使用多模 embedding,它可以把图片、文本、视频等映射到同一个向量空间中,可以实现以文搜图、以图搜视频等
- Qwen-VL-embedding
- multimodal-embedding-v1(OpenAI提供的闭源模型)
- 对于表格,比起 markdown,LLM 对 HTML 理解更好(2025 年的结论,以后可能会变化)
知识生成、知识完善:除了原 chunk 外:
- 用 LLM 生成一些知识,放入向量数据库。
- 用 LLM 生成一些问题&回答,放入向量数据库
知识健康度检查:收集用户的 query(这个 query 也可以用 LLM 模拟用户生成),建立一个 LLM 来检查知识库的健康度
- 完整性:评估知识库是否覆盖用户的主要查询需求
- 实效性:识别过期/需要更新的知识
- 一致性:发现知识库中的冲突和矛盾信息
- 综合评分:提供量化的健康度评分和改进建议
- 工程上:对知识库做版本管理
以下是 LLM 做知识健康检查,只包含关键 prompt
完整性
检查标准:
1. 查询是否能在知识库中找到相关答案
2. 知识是否完整、准确
3. 是否覆盖了用户的主要需求
4. 是否存在知识空白
请返回JSON格式:
{
"missing_knowledge": [
{
"query": "测试查询",
"missing_aspect": "缺少的知识方面",
"importance": "重要性(高/中/低)",
"suggested_content": "建议的知识内容",
"category": "知识分类"
}
],
"coverage_score": "覆盖率评分(0-1)",
"completeness_analysis": "完整性分析"
}
实效性
检查标准:
1. 时间相关信息是否过期(年份、日期、时间范围)
2. 价格信息是否最新(价格、费用、票价等)
3. 政策规则是否更新(政策、规定、规则等)
4. 活动信息是否有效(活动、节日、特殊安排等)
5. 联系方式是否准确(电话、地址、网址等)
6. 技术信息是否过时(版本、技术标准等)
请返回JSON格式:
{
"outdated_knowledge": [
{
"chunk_id": "知识切片ID",
"content": "知识内容",
"outdated_aspect": "过期方面",
"severity": "严重程度(高/中/低)",
"suggested_update": "建议更新内容",
"last_verified": "最后验证时间"
}
],
"freshness_score": "新鲜度评分(0-1)",
"update_recommendations": "更新建议"
}
当前时间是 {datetime.now().strftime('%Y年%m月%d日')}
一致性
检查标准:
1. 同一主题的不同说法(地点、名称、描述等)
2. 价格信息的差异(价格、费用、收费标准等)
3. 时间信息的不一致(营业时间、开放时间、活动时间等)
4. 规则政策的冲突(规定、政策、要求等)
5. 操作流程的差异(步骤、方法、流程等)
6. 联系方式的差异(地址、电话、网址等)
请返回JSON格式:
{
"conflicting_knowledge": [
{
"conflict_type": "冲突类型",
"chunk_ids": ["相关切片ID"],
"conflicting_content": ["冲突内容"],
"severity": "严重程度(高/中/低)",
"resolution_suggestion": "解决建议"
}
],
"consistency_score": "一致性评分(0-1)",
"conflict_analysis": "冲突分析"
}
切片策略 (主要就是前2个)
- 固定长度
- LLM 做切片:质量高、成本高
- 句子边界
- 按标题/章节切分:markdown 这种高度结构化的文档
- 滑动窗口
embedding
- 参考 https://www.guofei.site/2018/09/24/nlp_feature.html 关于 embedding 的部分
- 模型上,前面的例子用的是
sentence_transformers加载一个模型 - 也可以调用 Qwen3-embedding 模型(用 openai 调用),这些更现代的模型会更准
- 可以从 huggingface 上找,国内:https://modelscope.cn/
常见模型
- 常见的通用 embedding 模型
- BGE-M3 M3(智源研究院):支持100+语言,输入长度达8192 tokens,融合密集、稀疏、多向量混合检索,适合跨语言长文档检索。
- text-embedding-3-large(OpenAI):向量维度3072,长文本语义捕捉能力强,英文表现优秀。
- Jina-embeddings-v2-small(Jina AI)。特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化部署。
- 常见的中文 embedding 模型
- xiaobu-embedding-v2:针对中文语义优化,语义理解能力强。
- M3E-Base:针对中文优化的轻量模型,适合本地私有化部署。适用场景:中文法律、医疗领域检索任务。文件大小:0.4G (m3e-base)
- stella-mrl-large-zh-v3.5-1792:处理大规模中文数据能力强,捕捉细微语义关系。适用场景:中文文本高级语义分析、自然语言处理任务。
多模态召回优化:用户问题是文本,它与 视频、图片距离天然就远,但是需求是能返回图片和视频
- 做法:识别召回视频、图片的场景,并指定召回 top-k 个 图片/视频(用 meta 来指定)
关键词检索:from rank_bm25 import BM250api
- 这是一个基于关键词(TF-IDF)的召回算法库
- 作为补充召回
- 用参数 alpha 控制: 关键词检索 vs 向量检索的占比
- alpha 越小,越偏重关键词检索。关键词检索偏向于专业术语、精确匹配的需求。向量检索偏向于同义词丰富、表述多样的场景。
代码如下:
保存bm25模型
def save_bm25_model(chunks: List[str], model_path: str) -> None:
tokenized_chunks = [tokenize_chinese(chunk) for chunk in chunks]
bm25 = BM25Okapi(tokenized_chunks)
with open(model_path, "wb") as f:
pickle.dump({"bm25": bm25, "chunks": chunks}, f)
save_bm25_model(chunks, model_path='bm25.pkl')
加载 bm25模型,并召回
def load_bm25_model(model_path: str) -> Tuple[List[str], BM25Okapi]:
with open(model_path, 'rb') as f:
data = pickle.load(f)
bm25: BM25Okapi = data["bm25"]
chunks: List[str] = data["chunks"]
return chunks, bm25
# %%
def retrieve_bm25(query, bm25, chunks, k=5):
tokenized_query = tokenize_chinese(query)
bm25_scores = bm25.get_scores(tokenized_query)
ranked_idx = sorted(range(len(chunks)), key=lambda i: bm25_scores[i], reverse=True)[:k]
res = [(chunks[i], float(bm25_scores[i])) for i in ranked_idx]
return res
chunks, bm25 = load_bm25_model("bm25.pkl")
k = 5
query = "iPhone 15 Pro Max 多少钱"
query = "羽绒服多少钱"
res = retrieve_bm25(query, bm25, chunks)
向量数据库
- 前面的例子用的是 Chroma,它打包了“向量+文档+元数据+持久化+部署模式”,适合快速验证
- 线上建议使用:
- FAISS:性能标杆
- Elasticsearch:混合搜索(关键词+向量)表现优异
- Milvus、Pinecon、Weaviate、Qdrant 等
query 改写和联网搜索
query 改写
# 参考前面,传入 token
# client = OpenAI(...)
# 基于 prompt 生成文本
def get_completion(prompt, model="DeepSeek-V3.2"):
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return resp.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="DeepSeek-V3.2"):
self.model = model
def rewrite_context_dependent_query(self, current_query, conversation_history):
"""上下文依赖型Query改写"""
instruction = """
你是一个智能的查询优化助手。请分析用户的当前问题以及前序对话历史,判断当前问题是否依赖于上下文。
如果依赖,请将当前问题改写成一个独立的、包含所有必要上下文信息的完整问题。
如果不依赖,直接返回原问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def rewrite_comparative_query(self, query, conversation_history):
"""对比型Query改写"""
instruction = """
你是一个查询分析专家。请分析用户的输入和相关的对话上下文,识别出问题中需要进行比较的多个对象。
然后,将原始问题改写成一个更明确、更适合在知识库中检索的对比性查询。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 原始问题 ###
{query}
### 改写后的查询 ###
"""
return get_completion(prompt, self.model)
def rewrite_ambiguous_reference_query(self, current_query, conversation_history):
"""模糊指代型Query改写"""
instruction = """
你是一个消除语言歧义的专家。请分析用户的当前问题和对话历史,找出问题中 "都"、"它"、"这个" 等模糊指代词具体指向的对象。
然后,将这些指代词替换为明确的对象名称,生成一个清晰、无歧义的新问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def rewrite_multi_intent_query(self, current_query, conversation_history=None):
"""多意图型Query改写 - 分解查询
❗️ 多意图应当返回 List<str>,这个与别的不一样"""
instruction = """
你是一个任务分解机器人。请将用户的复杂问题分解成多个独立的、可以单独回答的简单问题。以JSON数组格式输出。
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始问题 ###
{current_query}
### 分解后的问题列表 ###
请以JSON数组格式输出,例如:["问题1", "问题2", "问题3"]
"""
return get_completion(prompt, self.model)
def rewrite_rhetorical_query(self, current_query, conversation_history):
"""反问型Query改写"""
instruction = """
你是一个沟通理解大师。请分析用户的反问或带有情绪的陈述,识别其背后真实的意图和问题。
然后,将这个反问改写成一个中立、客观、可以直接用于知识库检索的问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def rewrite(self, query, conversation_history, query_type: str):
'''路由:根据 query_type 决定 调用'''
if '上下文依赖' in query_type:
final_result = self.rewrite_context_dependent_query(query, conversation_history)
elif '对比' in query_type:
final_result = self.rewrite_comparative_query(query, conversation_history)
elif '模糊指代' in query_type:
final_result = self.rewrite_ambiguous_reference_query(query, conversation_history)
elif '多意图' in query_type:
final_result = self.rewrite_multi_intent_query(query)
elif '反问' in query_type:
final_result = self.rewrite_rhetorical_query(query, conversation_history)
else:
final_result = query
return final_result
def query_type_classifier(self, query, conversation_history="", context_info=""):
"""自动识别Query类型并进行改写"""
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,识别其属于以下哪种类型:
1. 上下文依赖型 - 包含"还有"、"其他"等需要上下文理解的词汇
2. 对比型 - 包含"哪个"、"比较"、"更"、"哪个更好"、"哪个更"等比较词汇
3. 模糊指代型 - 包含"它"、"他们"、"都"、"这个"等指代词
4. 多意图型 - 包含多个独立问题,用"、"或"?"分隔
5. 反问型 - 包含"不会"、"难道"等反问语气
说明:如果同时存在多意图型、模糊指代型,优先级为多意图型>模糊指代型
请返回JSON格式的结果:
{
"query_type": "查询类型",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 上下文信息 ###
{context_info}
### 原始查询 ###
{query}
### 分析结果 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"query_type": "未知类型",
"confidence": 0.5
}
def classify_and_rewrite(self, query, conversation_history="", context_info=""):
query_type_predict = self.query_type_classifier(query, conversation_history, context_info)
query_type = query_type_predict["query_type"]
res = {"query_type": query_type_predict["query_type"]
, "confidence": query_type_predict["confidence"]
, "rewrite_result": self.rewrite(query, conversation_history, query_type)
}
return res
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
cases = [
{"sample_name": "示例1: 上下文依赖型Query"
, "conversation_history": """
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了'疯狂动物城'主题园区,这里有朱迪警官和尼克狐的互动体验。"
用户: "这个园区有什么游乐设施?"
AI: "'疯狂动物城'园区目前有疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店等设施。"
"""
, "current_query": "还有其他设施吗"
, "query_type": "上下文依赖"
}
, {"sample_name": "示例2: 对比型Query"
, "conversation_history": """
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了疯狂动物城主题园区,还有蜘蛛侠主题园区"
"""
, "current_query": "哪个游玩的时间比较长,比较有趣"
, "query_type": "对比"
}
, {"sample_name": "示例3: 模糊指代型Query"
, "conversation_history": """
用户: "我想了解一下上海迪士尼乐园和香港迪士尼乐园的烟花表演。"
AI: "好的,上海迪士尼乐园和香港迪士尼乐园都有精彩的烟花表演。"
"""
, "current_query": "都什么时候开始?"
, "query_type": "模糊指代"
}
, {"sample_name": "示例4: 多意图型Query"
, "conversation_history": None
, "current_query": "门票多少钱?需要提前预约吗?停车费怎么收?"
, "query_type": "多意图"
}
, {"sample_name": "示例5: 反问型Query"
, "conversation_history": """
用户: "你好,我想预订下周六上海迪士尼乐园的门票。"
AI: "正在为您查询... 查询到下周六的门票已经售罄。"
用户: "售罄是什么意思?我朋友上周去还能买到当天的票。"
"""
, "current_query": "难道还要提前一个月预订吧?"
, "query_type": "反问"
}
]
for case in cases:
print('\n' + "=" * 20)
conversation_history = case['conversation_history']
current_query = case['current_query']
query_type = case['query_type']
print(case['sample_name'])
print(f"对话历史: {conversation_history}")
print(f"当前查询: {current_query}")
type_predict = rewriter.query_type_classifier(current_query, conversation_history, query_type)
print(f"预测的对话类型{type_predict}")
result = rewriter.rewrite(current_query, conversation_history, query_type)
print(f"改写结果: {result}\n")
result = rewriter.classify_and_rewrite(current_query, conversation_history)
print(f"自动分类+改写结果: {result}")
if __name__ == "__main__":
main()
联网检索
# 参考前面,传入 token
# client = OpenAI(...)
# 基于 prompt 生成文本
def get_completion(prompt, model="DeepSeek-V3.2"):
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return resp.choices[0].message.content
# Query联网搜索改写功能
# 导入依赖库
import os
import json
import re
from datetime import datetime
class WebSearchQueryRewriter:
def __init__(self, model="DeepSeek-V3.2"):
self.model = model
def identify_web_search_needs(self, query, conversation_history=""):
"""识别查询是否需要联网搜索"""
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,判断是否需要联网搜索来获取最新、最准确的信息。
需要联网搜索的情况包括:
1. 时效性信息 - 包含"最新"、"今天"、"现在"、"实时"、"当前"等时间相关词汇
2. 价格信息 - 包含"多少钱"、"价格"、"费用"、"票价"等价格相关词汇
3. 营业信息 - 包含"营业时间"、"开放时间"、"闭园时间"、"是否开放"等营业状态
4. 活动信息 - 包含"活动"、"表演"、"演出"、"节日"、"庆典"等动态信息
5. 天气信息 - 包含"天气"、"下雨"、"温度"等天气相关
6. 交通信息 - 包含"怎么去"、"交通"、"地铁"、"公交"等交通方式
7. 预订信息 - 包含"预订"、"预约"、"购票"、"订票"等预订相关
8. 实时状态 - 包含"排队"、"拥挤"、"人流量"等实时状态
请返回JSON格式:
{
"need_web_search": true/false,
"search_reason": "需要搜索的原因",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 用户查询 ###
{query}
### 分析结果 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"need_web_search": False,
"search_reason": "无法解析",
"confidence": 0.5
}
def rewrite_for_web_search(self, query, search_type="general"):
"""为联网搜索改写查询"""
instruction = """
你是一个专业的搜索查询优化专家。请将用户的查询改写为更适合搜索引擎检索的形式。
改写技巧:
1. 添加具体地点 - 如"上海迪士尼乐园"、"香港迪士尼乐园"
2. 添加时间范围 - 如"2024年"、"今天"、"本周"
3. 使用关键词组合 - 将长句拆分为关键词
4. 添加搜索意图 - 明确搜索目的
5. 去除口语化表达 - 转换为标准搜索词
6. 添加相关词汇 - 增加同义词或相关词
请返回JSON格式:
{
"rewritten_query": "改写后的搜索查询",
"search_keywords": ["关键词1", "关键词2", "关键词3"],
"search_intent": "搜索意图",
"suggested_sources": ["建议搜索的网站类型"]
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始查询 ###
{query}
### 搜索类型 ###
{search_type}
### 改写结果 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"rewritten_query": query,
"search_keywords": [query],
"search_intent": "信息查询",
"suggested_sources": ["官方网站", "旅游网站"]
}
def generate_search_strategy(self, query, search_type="general"):
"""生成搜索策略"""
current_date = datetime.now().strftime("%Y年%m月%d日")
instruction = f"""
你是一个搜索策略专家。请为用户的查询制定详细的搜索策略。
当前日期:{current_date}
搜索策略包括:
1. 主要搜索词 - 核心关键词
2. 扩展搜索词 - 相关词汇和同义词
3. 搜索网站 - 推荐的搜索平台
4. 时间范围 - 具体的搜索时间范围
请返回JSON格式:
\{
"primary_keywords": ["主要关键词"],
"extended_keywords": ["扩展关键词"],
"search_platforms": ["搜索平台"],
"time_range": "具体的时间范围"
\}
"""
prompt = f"""
### 指令 ###
{instruction}
### 用户查询 ###
{query}
### 搜索类型 ###
{search_type}
### 搜索策略 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"primary_keywords": [query],
"extended_keywords": [],
"search_platforms": ["百度", "谷歌"],
"time_range": "最近一周"
}
def auto_web_search_rewrite(self, query, conversation_history=""):
"""自动识别并改写为联网搜索查询"""
# 第一步:识别是否需要联网搜索
search_analysis = self.identify_web_search_needs(query, conversation_history)
if not search_analysis.get('need_web_search', False):
return {
"need_web_search": False,
"reason": "查询不需要联网搜索",
"original_query": query
}
# 第二步:改写查询
rewritten_result = self.rewrite_for_web_search(query)
# 第三步:生成搜索策略
search_strategy = self.generate_search_strategy(query)
return {
"need_web_search": True,
"search_reason": search_analysis.get('search_reason', ''),
"confidence": search_analysis.get('confidence', 0.5),
"original_query": query,
"rewritten_query": rewritten_result.get('rewritten_query', query),
"search_keywords": rewritten_result.get('search_keywords', []),
"search_intent": rewritten_result.get('search_intent', ''),
"suggested_sources": rewritten_result.get('suggested_sources', []),
"search_strategy": search_strategy
}
def main():
# 初始化联网搜索Query改写器
web_searcher = WebSearchQueryRewriter()
print("=== Query联网搜索识别与改写示例(迪士尼主题乐园) ===\n")
# 示例1: 时效性信息查询
print("示例1: 时效性信息查询")
conversation_history1 = """
用户: "我想去上海迪士尼乐园玩"
AI: "上海迪士尼乐园是一个很棒的选择!"
"""
query1 = "上海迪士尼乐园今天开放吗?现在人多不多?"
print(f"对话历史: {conversation_history1}")
print(f"当前查询: {query1}")
result1 = web_searcher.auto_web_search_rewrite(query1, conversation_history1)
if result1['need_web_search']:
print(f"✓ 需要联网搜索")
print(f" 搜索原因: {result1['search_reason']}")
print(f" 置信度: {result1['confidence']}")
print(f" 改写查询: {result1['rewritten_query']}")
print(f" 搜索关键词: {result1['search_keywords']}")
print(f" 搜索意图: {result1['search_intent']}")
print(f" 建议来源: {result1['suggested_sources']}")
print(f" 搜索策略:")
print(f" - 主要关键词:", result1['search_strategy']['primary_keywords'])
print(f" - 扩展关键词:", result1['search_strategy']['extended_keywords'])
print(f" - 搜索平台:", result1['search_strategy']['search_platforms'])
print(f" - 时间范围:", result1['search_strategy']['time_range'])
else:
print(f"✗ 不需要联网搜索")
print(f" 原因: {result1['reason']}")
print("\n" + "=" * 60 + "\n")
# 示例2: 价格和预订信息查询
print("示例2: 价格和预订信息查询")
query2 = "下周六的门票多少钱?需要提前多久预订?"
print(f"当前查询: {query2}")
result2 = web_searcher.auto_web_search_rewrite(query2)
if result2['need_web_search']:
print(f"✓ 需要联网搜索")
print(f" 搜索原因: {result2['search_reason']}")
print(f" 置信度: {result2['confidence']}")
print(f" 改写查询: {result2['rewritten_query']}")
print(f" 搜索关键词: {result2['search_keywords']}")
print(f" 搜索意图: {result2['search_intent']}")
print(f" 建议来源: {result2['suggested_sources']}")
print(f" 搜索策略:")
print(f" - 主要关键词: {result2['search_strategy']['primary_keywords']}")
print(f" - 扩展关键词: {result2['search_strategy']['extended_keywords']}")
print(f" - 搜索平台: {result2['search_strategy']['search_platforms']}")
print(f" - 时间范围: {result2['search_strategy']['time_range']}")
else:
print(f"✗ 不需要联网搜索")
print(f" 原因: {result2['reason']}")
if __name__ == "__main__":
main()
检索策略
- Query2Doc:把用户的查询改写成文档,
- 用户查询:“如何提高深度学习模型的训练效率?”
- 生成一段扩展文档:
```
- 使用更高效的优化算法,如AdamW或LAMB。
- 采用混合精度训练(Mixed Precision Training),减少显存占用并加速计算。
- 使用分布式训练技术,如数据并行或模型并行。
- 对数据进行预处理和增强,减少训练时的冗余计算。
- 调整学习率调度策略,避免训练过程中的震荡。 ```
- doc2query:为文档生成相关的 query
- Small-to-Big:
- 用户输入 query 后,系统先在小规模内容(摘要、关键句、段落)中检索。
- 然后系统根据小规模内容,用指针(或文档ID、URL等),找到大规模内容
- 把大规模内容作为 RAG 上下文,放入 prompt
GraphRAG 在工程中应用还不多,其思路可以借鉴。
传统 RAG 的缺点:
- 连接点缺失。问题的答案分散在文档的不同位置,且没有直接的语义重叠,传统 RAG 很难把它们串联起来
- 宏观理解缺失。如果用户问“这篇文章的主旨是什么?”传统RAG 很难给出一个概括性的答案,
GraphRAG 主要步骤(https://github.com/microsoft/graphrag)
- 切片
- 抽取:抽取的是 实体、关系。(知识图谱),用的是 LLM 方法,n个 prompt (很贵)
- 聚类和摘要
Agent
Agent 是包含了 RAG、提示词、Function calling、Re-Act等一系列元素的集合
- API 调用,例如查询天气、发送邮件
- Re-Act
自主Agent
- 由 Planner 模块(也是个LLM),与其它 LLM、工具调用的配合
Fine-tuning
Scaling Law LLaMA:即使是7B模型,训练数据继续扩展到 1T token,其性能仍然会上升
为什么需要微调?
- 更改提示词方便快捷,但是有上限:
- 领域模型经验难以描述
- prompt 太长,遵循程度低。
- prompt 遵循有幻觉
- 哪些任务适合 SFT?
- Prompt 放不下,例如某个系统有数万条规则。
- 一些新的思考方式,例如日志分析大模型,可以让它学会沿着报错 stack 分析
- 某些文风(例如角色扮演)、风险偏好对齐等等
有哪些思路
- 大模型(如 DeepSeek-671B)在特定领域的知识转移到小模型如(Qwen-0.6B)。如此,可以在推理时获得双方的优点:小模型的QPS、小资源消耗,接近大模型准确率。
- 方法和流程:大模型 -> 获得COT数据 -> 蒸馏小模型
- 大模型->专家经验(Ground truth)->蒸馏小模型
- 方法和流程:专家用人工的方式提供答案/推理(可以借助大模型,或者不借助大模型)。成本较高。
- RSFT(拒绝采样 SFT):
- 传统 SFT 数据是用大模型(如 DeepSeek-R1)生成 CoT 和答案。然后剔除低质量的,用于训练小模型。
- RSFT 是让小模型A产生 CoT 和答案,用大模型判断质量并筛选,然后训练小模型A。
- 因为训练数据来自 A 自己,它是会这些的,只是思路不能收敛于正确答案。这样可以帮助其思路收敛,因此效果很好。
- RFT:RL+SFT,击溃是 RSFT 的基础上,用高质量的一组问题做回答和奖惩。
什么时候需要?
- 如果是通识场景,不需要 SFT
- 如果场景比较冷僻,就需要 SFT
有哪些方法
- 全量微调(Full Finetune):所有参数都更新
- 参数高效微调(PEFT,Parameter-Efficient-Finetune),仅调整部分参数
- LoRA:通过低秩矩阵分解模拟权重更新
- 还有 Adapter、Prefix Tuning 等
- QLoRA:是量化 + LoRA,冻结的基座模型用 4bit 放显存
- 强化学习(Reinforcement Learning)
- 人类反馈强化学习(RLHF):人类对模型输出评价,使其符合人类价值观和任务需求
- 近端策略优化(PPO):通过策略梯度更新
- 直接偏好优化(DPO):无需显式训练奖励,是PPO的简化
- 组相对策略优化(GRPO)
base model 选择
- 复杂SFT任务:选 7B 以上
- 高性能任务:选 1B 以下
获取数据
方法1直接用大模型生成COT。例如,直接用基座模型(例如 DeepSeek-R1/V3, ChatGPT)生成COT数据
方法2设计多智能体 例如,设计2个智能体。一个扮演客服专家,一个扮演客户
- 客服专家产生话术
- 客户提出意见,例如,“增加友好和关心的语气”、“这段话术稍显冗长”
- 客服专家根据意见做优化
- 数轮之后(3-5轮),得到优化后的话术。
- 用另一个 LLM 做一轮过滤,得到最终的数据集
方法3:传统方法
- 业务系统收集(预训练一般不用这个,因为有数据泄露风险,但 SFT 经常需要)
- 开源数据集
- 开源数据集
- HuggingFace、GitHub
- 爬虫。爬到的数据,解析阶段也可以用 LLM 了
- 采买:题库、书籍、教材
- …
高质量训练数据
数据不需要太多:Meta《LIMA》:1k优质样本即可打败海量普通数据。因此,获取 高质量训练数据 是关键
数据质量评估
- 准确
- 无事实错误
- 一致性:内部处理逻辑统一,数据之间没有互相矛盾
- 其它问题,拼写检查与纠正、文本规范化(如有必要的话,例如小写化、去除特殊字符)、确定适当的最大文本长度。
- 方法和工具:
- 人工质量抽检
- rule-based:格式准确性等多重规则
- LLM as judge
- 构建静态指标:例如,输出长度/PPL等
- PPL (困惑度,perplexity)的计算:预测下一个词时的“平均交叉熵”的指数。它大于1,并且越大代表越不确定。
- PPL 过高和过低都要剔除。过低代表不必再学了,过高的也是学不会。
- 借用开源 reward model/微调若干大模型来实现数据质量奖励/训练小模型
- 完整性 (覆盖任务要点)
- 覆盖全部需要的 任务类型
- 难度梯度 简单/中等/复杂任务比例合理
- 覆盖全部需要的 文本主题
- 数据洁净度:剔除重复、噪声、错误的样本
- 去除冗余数据
- 正负样本均衡
- 样本相关性,捕捉数据集的上下文和语义多样性。(生成的指令和其最相似的种子指令之间的ROUGE-L分数分布。)
- kmeans/k-center(计算复杂度较低), 挑选出多样性的数据,即Seed Instruction Data。这步关注的是 coverage。
- 简洁性:(无冗余信息)
- 高质量的重复数据,可以提升模型效果。但中等质量会浪费计算资源、降低泛化性。
实操流程
- 去重:md5、MinHash
- 低质量过滤
- 关键词过滤、规则过滤
- 用”小“模型(例如 Qwen-7B)计算 PPL(PPL太低、太高都不适合训练)
- …
- 去毒:黄、赌、毒、涉政、隐私去除
- 数据集整体评估:消融实验。
- 是什么:把新的数据集,在之前模型的 checkpoint 上继续训练,观察其在各个验证集(榜单)上的表现
- 目的:评估新数据集是否:1)提供增量知识,2)不损害已训练的效果
- 实验结果:效果提升,说明有提升;效果下降,说明损害了已训练的效果;效果不变,说明新数据集没有带来提升
- 难点:多个验证集,有的提升,有的下降,怎么办?
业务知识如何融入
- 专家的感性知识。典型历史案例 -> (大模型)抽取专家知识 -> 沉淀为业务知识
- 策略/正则表达式/规则 -> 翻译成人话 -> 沉淀为专家经验
- 业务专有名称 -> 整理出业务“词典”
SFT
如何训练
- loss. SFT 时,一般会 mask 掉 prompt 部分的 loss,只学习输出部分的 loss
- 学习率. 一般是预训练的学习率的 0.1 倍
- epoch. 小样本(<1万)5个,大样本(>1万)2个
- 混入 30%-50% 高质量预训练数据(通用数据),防止灾难性遗忘,保持泛化能力
关键指标
- 业务合格率:从业务出发,人工对结果打标,给出 good/ok/bad,并计算指标
- 提升率:指标比上一个版本提升了多少
LoRA(Low-Rank Adaptation of Large Language Models)
- 核心原理是矩阵分解 $\Delta W_{d\times k} = B_{d\times r} A_{r\times k}$,当 r 较小时,A 和 B 的参数量就很小
- 训练时冻结原来的模型参数 $W$,
- 随机初始化 $A$ 和 $B$,训练时更新的是 $A$ 和 $B$
- 最后按照 $W + \Delta W = W + AB$ 来更新参数
- 需要调整的参数少
- 还有利于多卡并行训练
- 因此很快、显存占用也低
- 具体来说,全参训练相比需要计算全部参数的梯度(显存角度:需要存储全部梯度以及优化器状态);而 LoRA 不需要这些,但是额外需要计算 LoRA 部分的前向、梯度,但这个占比只有1%-3%
- 推理时,有 sLoRA 这样的技术,使其共享预训练模型参数,进一步降低推理成本。
LoRA 评价
- 最终效果低于全量微调
- 如果基座模型表现不好,LoRA 大概率不好(因为只改动了一部分参数)
- LoRA 记忆力不如全参微调
一个专门解数学题的7B模型训练步骤:
- step1: 用 Math-500(开源数据集)做 SFT
- step2: 现价一个难度过滤器,保证每次训练正好是有些难度的
- step3: 蒸馏超大模型的 CoT
- step4: 改善 CoT,这个例子的实验表示,CoT 要简繁适中、给出多个思路。
数据量经验值:最少100条,以 5000条为佳
GRPO
区别:
- SFT:用大模型准备数据,给小模型来训练
- RL:问题描述(Initial State 无Output),只需要足够多样的问题,无需答案
为什么:“SFT负责记忆,RL负责泛化”
- SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training,https://arxiv.org/abs/2501.17161
大模型相关的 RL 发展历史:
- PPO:用了4个模型:Actor Model(大模型本身),Ref Model(冻结的模型),Reward Model,Critic Model(对每个状态的评估,预测未来的潜在回报)
- DPO:用一些数学技巧,省去了 Critic Model、Reward Model、Ref Model,只需要 Actor Model 和 accept/reject 。性能很好。Reward 很难写。
- GRPO,用组内相对结果来计算奖励,无需 Critic(节省内存)
GRPO(Group Relative Policy Optimization)包含3个模型
- Actor Model:是训练过程中需要优化的核心策略模型,负责根据输入生成候选输出。通过生成多个输出(如数学题的多解方案)进行群体内对比。
- Reward Model:用于评估Actor生成输出的质量,为每个输出分配奖励值。通过群体归一化(如减去均值、除以标准差)将绝对奖励转换为相对优势,替代传统优势函数计算。
- 这个部分也可以是个规则,而不是 Model,例如:
- 格式奖励(例如是否有think 和 answer,例如格式是否符合预期)
- 结果正确性奖励。有些问题可以用规则判断
- 其它奖励:
- 语言一致性
- 长度奖励
- 重复性惩罚
- 思考过程奖励,条理性、逻辑性
- Reference Model:是一个冻结(参数不更新)的基准模型,用于计算KL散度(Kullback-Leibler Divergence),约束Actor Model的策略更新幅度,防止其过度偏离初始策略。
GRPO的算法流程
- 分组采样响应。对同一个 Prompt 生成一组响应(4-8个)
- 组内评分语排名。根据Reward Model(或规则),对每个响应评分,然后,相对优势=个体得分-组平均分
- 策略优化方向。强化学习得分相对优势高的,抑制相对优势低的。
Post-Pretrain
使用大量数据,在一个已经训练好的模型上继续训练。
举例:有一个英文的大模型,想做一个中文+金融大模型。做法:

Post-Pretrain 和 SFT 的区别
- SFT 主要是问答格式的语料,Post-Pretrain 是普通的语料
- loss 有对应的调整
性能与资源
一般结论:推理需要的显存为模型大小的2~3倍;后训练需要8~10倍;LoRA 后训要20%这个量级。
影响因素
- 模型本身的变量个数,例如 Qwen-14B 有 14Billion 个参数;Qwen-7B 有 7Billion 个参数
- 变量类型:Int8 需要 1个字节;FP16/BF16 需要2个字节;FP32 需要4个字节
- 推理时用小精度:叫做 量化
- 最常用的:BF16(范围大、精度小)
- 游戏卡可以跑大模型,不能做工业渲染
- 推理 假设参数量为 X,用 BF16,全部参数占用 2X,KV缓存留 20%,其它损耗留 10%,共
2 * 1.3 = 2.6(经验值是 2~3 倍) - 训练 参数 2X,梯度 2X,优化器 Adam 4X、激活和损耗 30%,
2X(1 + 1 + 2 + 0.3) = 8.6X
推理性能指标
- 首字延迟(TFFT)。模型开始计算,到产生第一个 Token 消耗的时间。
- 这个时间内,大模型会把输入的 Prompt 逐 Token 计算一边,并建立 KV Cache
- 通常是秒级
- 生成速度(TPOT)。之后的 Token 生成速度。
- 通常是几十毫秒级
- QPS
性能提高技术
- 并行。这里有很多技术
- 并行训练,多个batch并行处理,然后汇聚梯度
- 把大矩阵乘法分解到多个卡上并行,计算速度提升,但通信开销变大。
- 基础工具:PyTorch Distributed、DeepSpeed、通信协议 NCLL(NVIDIA Collective Communications Library,为 GPU 优化的通信库,是 Pytorch 的基础之一)
- 用 BP16,而不是 FP32
- prefix cache
- 适用于 query 有共同的前缀。例如系统提示词都一样。
- continuous batch:按 batch,把一批需要预测的放到一起。(类似向量化运算)
- 量化(Quantization) 学术界非常多的方法提出
- 例如,FP32 转 INT8
- 剪枝(Pruning):去除接近0的权重
- 稀疏化。
- 压缩输入,只选取重要的 Token(gemfilter);
- 压缩 MLP 计算(对 FNN 模块做剪枝)
- 压缩 attention (SeerAttention)
- 一些简单的任务,路由到更小的模型
- 如果模型只处理特点领域的任务,考虑 distill
- 大小模型配合(相关技术复杂)
大模型评估
测评大模型(A Survey on Evaluation of Language Models)https://arxiv.org/abs/2307.03109
- 验证性能和能力
- 评估泛化能力:在未见过的数据上也保持良好
- 明确不同的大模型差异:了解其优势领域
- 防止大模型风险:安全漏洞之类的
- 知道大模型改进:识别模型弱点、提供优化方向
一些知识点
- 有时候,多一个换行符,可能对结果产生较大影响
测评方法
- 在有标准答案的数据集上评测:如何提取模型的答案
- 针对选择题,计算每个选项的 PPL
- 对抗测评:在另一个模型上得到回答,比较 A 回答 和 B 回答的好坏。解决的问题:有时候单纯看答案,不能很好的标注回答的好坏。
- 与基线模型对抗
- 多个模型两两对抗
评估问题
- 封闭式问题:使用预先已经有的答案完成测评
- 开放式问题:
- 人工测评
- 大模型测评
安全评估
- 内生安全:在数据和模型层面的安全
- 数据投毒:操纵训练样本,使 LLM 在特定触发条件下输出有害结果
- 模型幻觉。诸如医疗、金融、法律场景可能造成严重后果。主要靠 RAG、MCP
- 引证生成:要求模型标记来源
- 方式1:inline citations,用 prompt 约束:“每句必须带引用”、“只允许引用给定 sources 列表”、“引用必须来自支持该句的原文,不支持就说不知道”。缺点是仍然会有幻觉
- 方式2:post-hoc attribution,先让模型生成不带引用的答案,对每个 claim 做证据匹配(1. 用 embedding 来匹配,2. 用 LLM 来匹配)。更可控,但工程复杂、耗时高
- self-RAG:由 LLM 自动决定是否检索、检索什么、如何使用证据、何时停止
- 引证生成:要求模型标记来源
- 价值观问题
- 服务安全:AI+、智能体、各种服务的漏洞
- 数据泄露(用户隐私、提示词之类的)
- 安全攻击(类比传统的互联网攻击)
- 供应链风险
- …
- 使用上的安全、未来的安全问题
- 伪造
- 虚假新闻
- 错误的重大建议(医疗、金融)
评估的板块
- 内容安全:黄赌毒、迷信、恐怖暴力
- 意识形态
- 数据安全
- 伦理:身心健康、公序良俗、礼貌、防歧视
- 合规:符合国家的部门规章(金融、医疗、政务等)
- 自我认知:xx公司开发的xx模型
- 真实性
攻击手法
- 指令劫持
- 口令复述
- 正反介绍
- 循序渐进
- 情景带入
- …
- 绕过检测
- 内涵
- 藏头诗
- 嵌套
- …
模型水印
- 模型文件水印、AIGC标识
- 参数级水印
- 行为级水印:特定输入,使其呈现特殊的输出
- 数据水印:“善意”版本的数据投毒
一些 AI 产品架构
一、转发回复架构

这个是最简单的架构,常用于聊天 app
分拆任务架构
举例:
- 论文阅读助手,会有多个模型,做不同的任务
- AI PPT,有的模型规划大纲,有的模型画结构,有的模型填内容
三、事件触发
例子:
- 新闻订阅
- 金融事件响应系统
- 市场调研助手:问卷收集到一定数量后,启动流程,最终给用户输出报告
感知启动

例子:法律咨询助手
- Agent:观察对话、理解要点、判断潜在需求、匹配类似案件等
其它:以上架构的组合
多Agent
整体思路
- 角色分解:
- supervisor:只负责需求拆解、分发任务,没有执行权限
- 执行者:负责执行具体的任务
- SOP标准化
- 人设隔离,划分不同的人设,不同的人可使用不同的工具集
- 人设:“你是一个资深Java开发,只负责开发后端代码”
- 工具:例如检索、Python解释器、数据库读写
- 通信机制
- 点对点传递:适合线形任务
- 共享黑板:全局共享当前状态,适合复杂任务
- 协作模式
- 层级式:Boss -> Leader -> Worker
- 中心化调度
- 效率高
- 辩论式: Agent A VS Agent B
- 多轮互斥讨论和 review,准确率高
- 流水线:固定顺序执行,适合 SOP 明确的任务
- 层级式:Boss -> Leader -> Worker
问题
- 错误叠加,整体出错概率极高
- 蝴蝶效应,错误传导
- 解决方案:
- 断点续传
- agent判断调用错误状态,并自动行动
工程经验
- 多 Agent 不能互相耦合。
- 否则:风格(思路)不统一,即使它们共享上下文;
- 决策与执行尽量用同一个模型。
- 可以拆出来的:例如一个子Agent去查询、学习一个生僻的库,而绝不能用它来写代码。
一些方向
text2sql
流程
- 用户问题
- 构建 prompt
- 选择 schema
- 构建的 Prompt 要求:简洁、严格规定不准自由发挥、不准解释,可以添加 few shot
- 生成 SQL
- 用一个单独的 LLM 来执行
- 可以生成 N 份,然后让模型选择最优的
- 校验
- 规则校验
- 模型校验
- 执行
- 如有报错,则返回给大模型
- (如有必要)解释结果,结构化数据转文本
您的支持将鼓励我继续创作!
